部署环境
# 操作系统:ubuntu-16.04-x64
# jdk版本:1.8
# scala版本:2.11.6
# spark版本:spark-2.0.1-bin-hadoop2.6
# 主机ip:192.168.103.12
独立模式
除了在mesos或yarn集群管理器运行,spark还提供了一个简单的独立部署模式(standalone)。它除了可以部署到单机,也可以部署到集群中,不依赖任何其他资源管理系统。
安装步骤
1.安装前准备
安装jdk-1.8
root# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
安装scala-2.11
root@sparkclient:/opt/spark/spark-2.0.1-bin-hadoop2.6# scala -version
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
下载spark-2.0.1-bin-hadoop2.6,点击这里
2.安装spark
上传安装包到主机上
root# ls -l
total 180560
-rw-r--r-- 1 root root 184890838 May 8 16:52 spark-2.0.1-bin-hadoop2.6.tgz
解压并创建安装目录
# mkdir -p /opt/spark # 创建安装目录
# tar xf spark-2.0.1-bin-hadoop2.6.tgz # 解压安装包
# mv spark-2.0.1-bin-hadoop2.6 /opt/spark
修改环境变量
# vim /etc/profile
添加以下内容
export SPARK_HOME=/opt/spark/spark-2.0.1-bin-hadoop2.6
export PATH=${SPARK_HOME}/bin:$PATH
使修改生效
# source /etc/profile
spark shell命令行
spark自带了spark-shell和pyspark 两个交互式shell,可以以脚本方式进行交互式执行。spark-shell依赖scala,pyspark依赖python。所以为了交互shell能正常运行,需要预先安装好依赖组件,这里以spark-shell为例。
进入Spark-Shell只需要执行spark-shell即可:
#spark-shell
进入到Spark-Shell后可以使用Ctrl D组合键退出Shell
在Spark-Shell中我们可以使用scala的语法进行简单的测试,比如下图所示我们运行下面几个语句获得文件/etc/protocols的行数以及第一行的内容:
scala> var file = sc.textFile("/etc/protocols")
file: org.apache.spark.rdd.RDD[String] = /etc/protocols MapPartitionsRDD[1] at textFile at <console>:24
scala> file.count()
res0: Long = 64
scala> file.first()
res1: String = # Internet (IP) protocols
上面的操作中创建了一个RDD file,执行了两个简单的操作:
- count()获取RDD的行数
- first()获取第一行的内容
spark 分布式服务
1.启动主节点
# cd /opt/spark/spark-2.0.1-bin-hadoop2.6/
# ./sbin/start-master.sh
没有报错的话表示master已经启动成功,master默认可以通过web访问http://192.168.103.12:8080
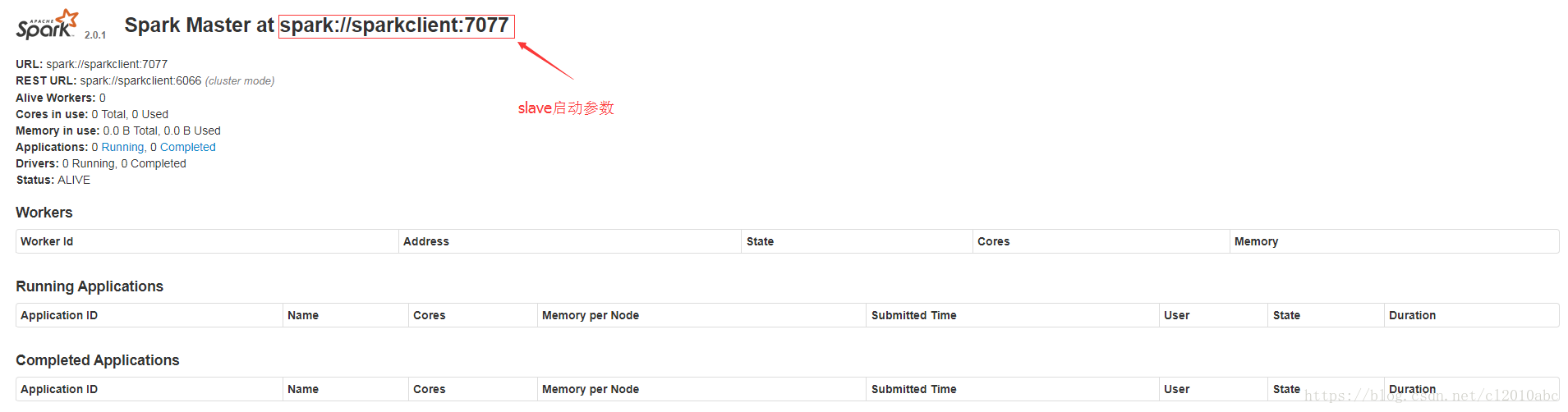
图中所示,master中暂时还没有一个worker,我们启动worker时需要master的参数,该参数已经在上图中标志出来:spark://sparkclient:7077
2.启动从节点
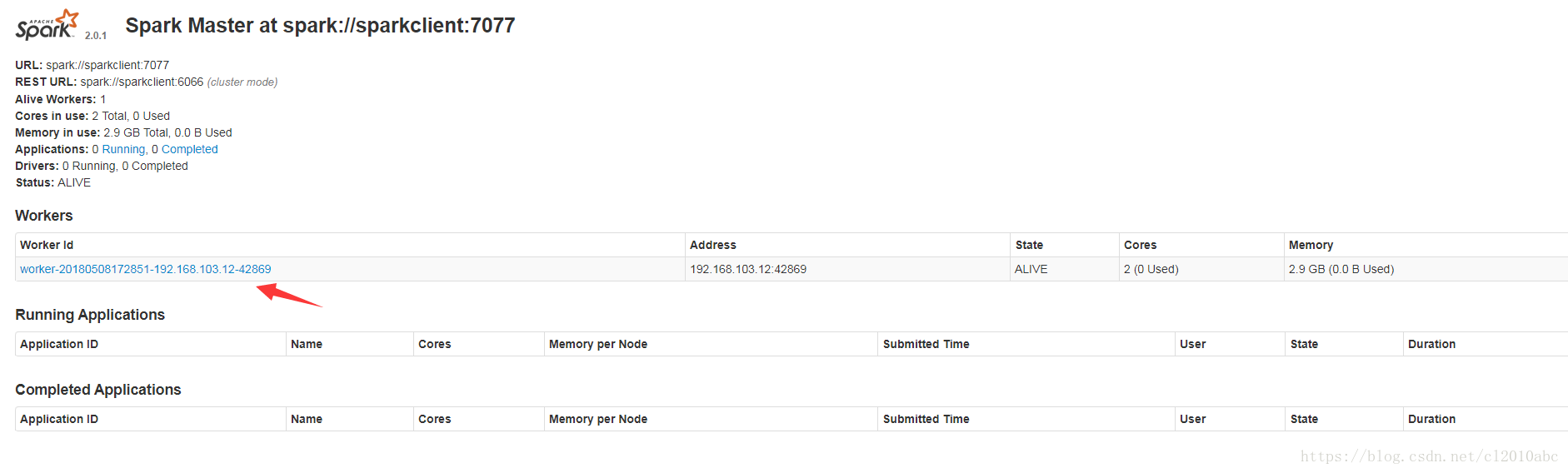
./sbin/start-slave.sh spark://sparkclient:7077
没有报错表示启动成功,再次刷新浏览器页面可以看到下图所示新的worker已经添加:
3.测试实例
spark shell 连接测试
使用spark-shell连接master再次进行上述的文件行数测试,如下图所示,注意把master参数替换成你实验环境中的实际参数:
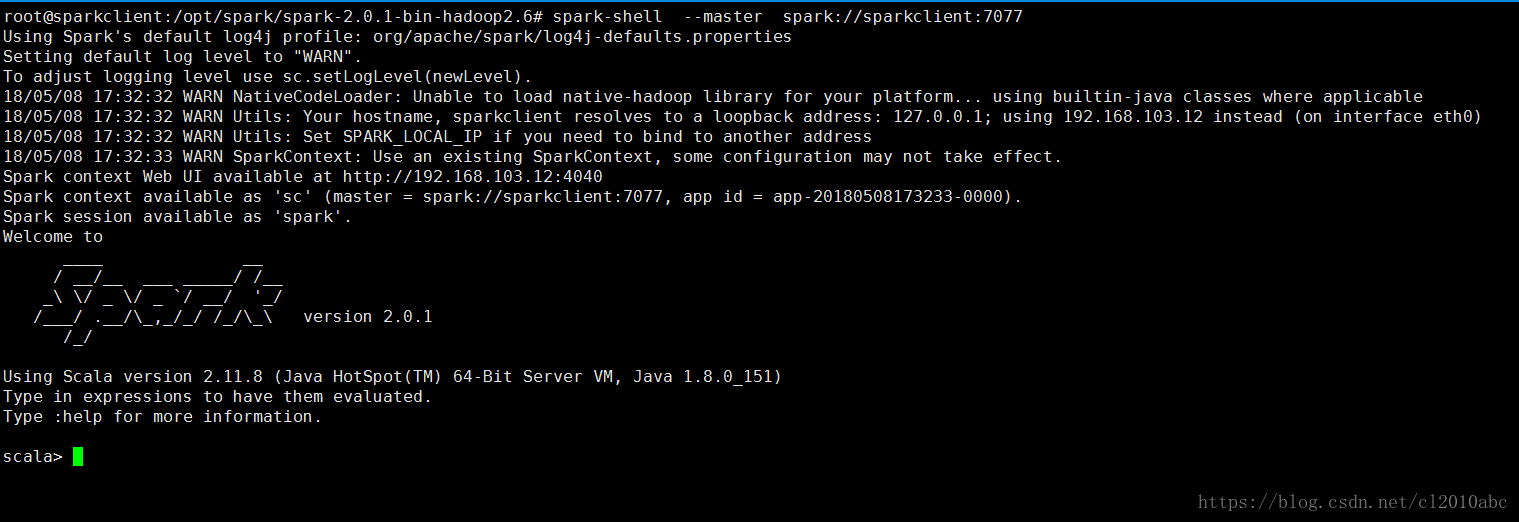
新master的web页面,可以看到新的Running Applications,如下图所示:
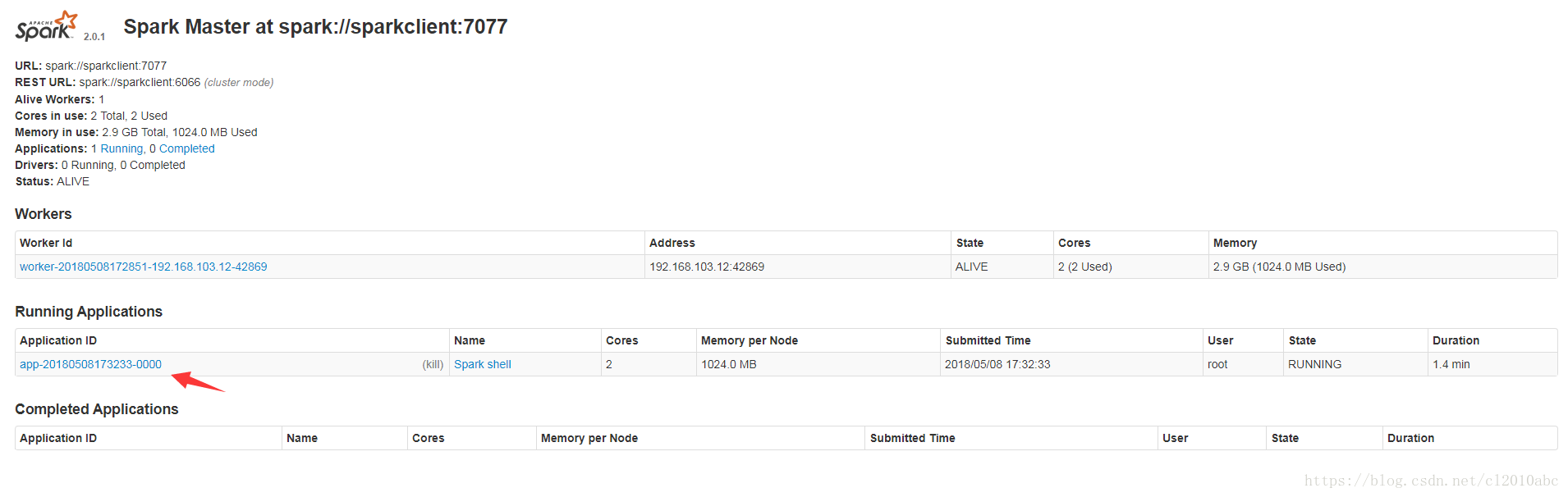
当退出spark-shell时,这个application会移动到Completed Applications一栏。
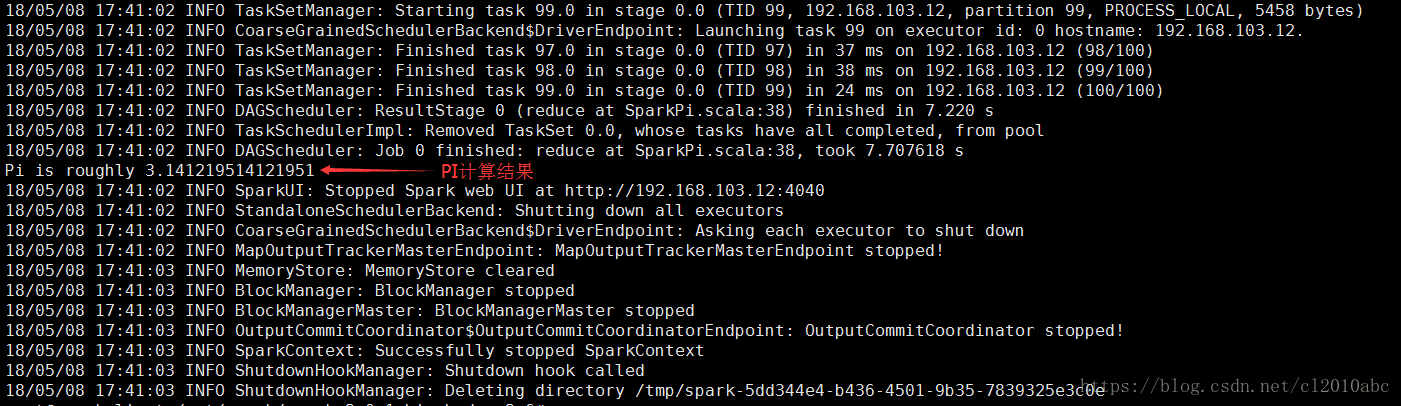
spark 自带pi计算测试
# spark-submit --class org.apache.spark.examples.SparkPi --master spark://sparkclient:7077 examples/jars/spark-examples_2.11-2.2.1.jar 100
运行结果如下: