终于说到了体现分布式计算价值的地方了!
和单机运行的模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非你用到了HDFS的内容。

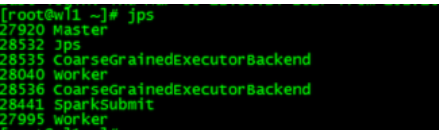
启动的进程如下:(其他非Master节点上只会有Worker进程)

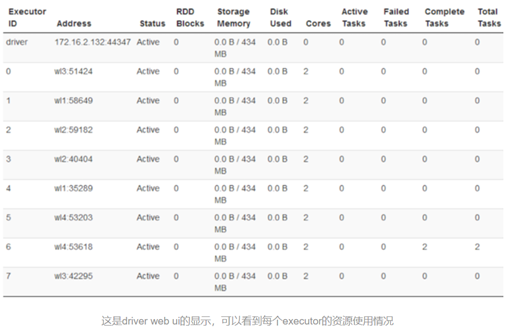
这种运行模式,可以使用Spark的8080 web ui来观察资源和应用程序的执行情况了。

可以看到,当前环境下,我启动了8个worker进程,每个可使用的core是2个,内存没有限制。言归正传,用如下命令提交应用程序:

代表着会在所有有Worker进程的节点上启动Executor来执行应用程序,此时产生的JVM进程如下:(非master节点,除了没有Master、SparkSubmit,其他进程都一样)

转载自:
作者:俺是亮哥
链接:https://www.jianshu.com/p/65a3476757a5
來源:简书