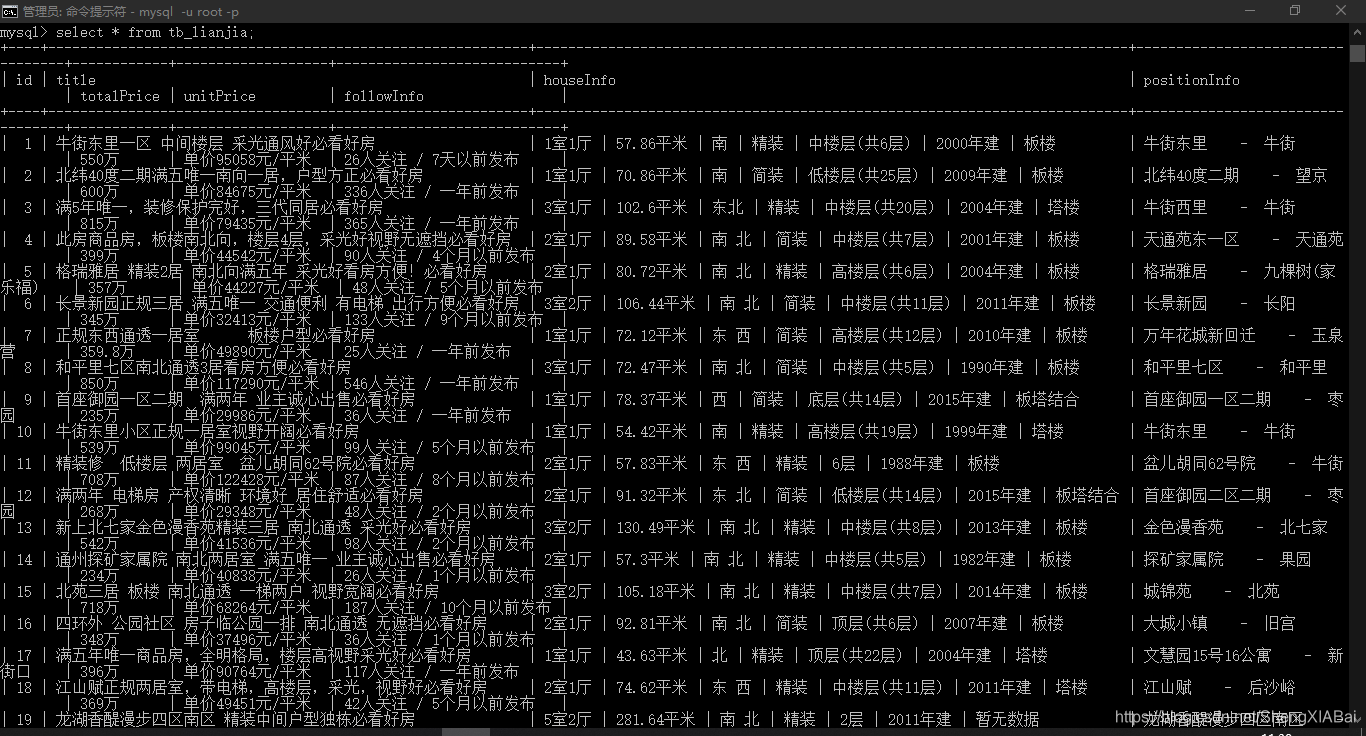
Python与MySQL的交互操作
案例——链家二手房数据
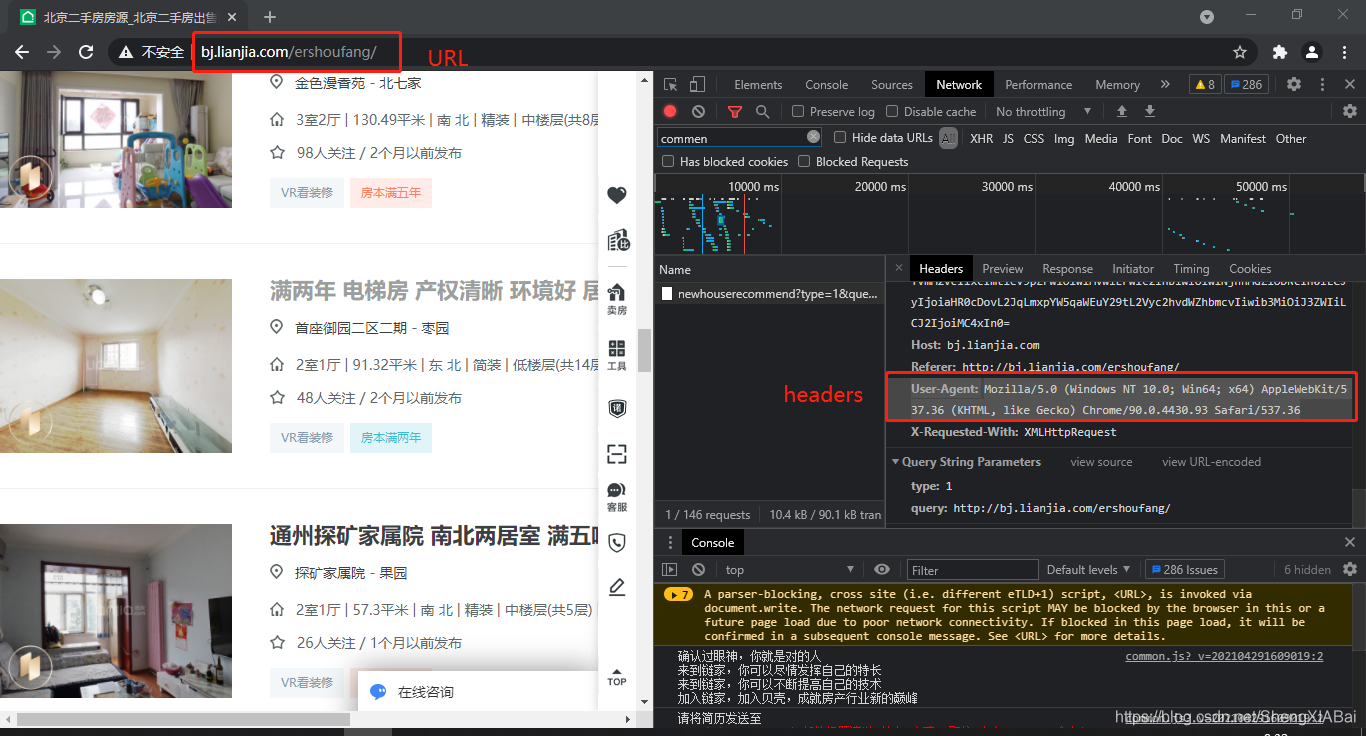
请求数据获取
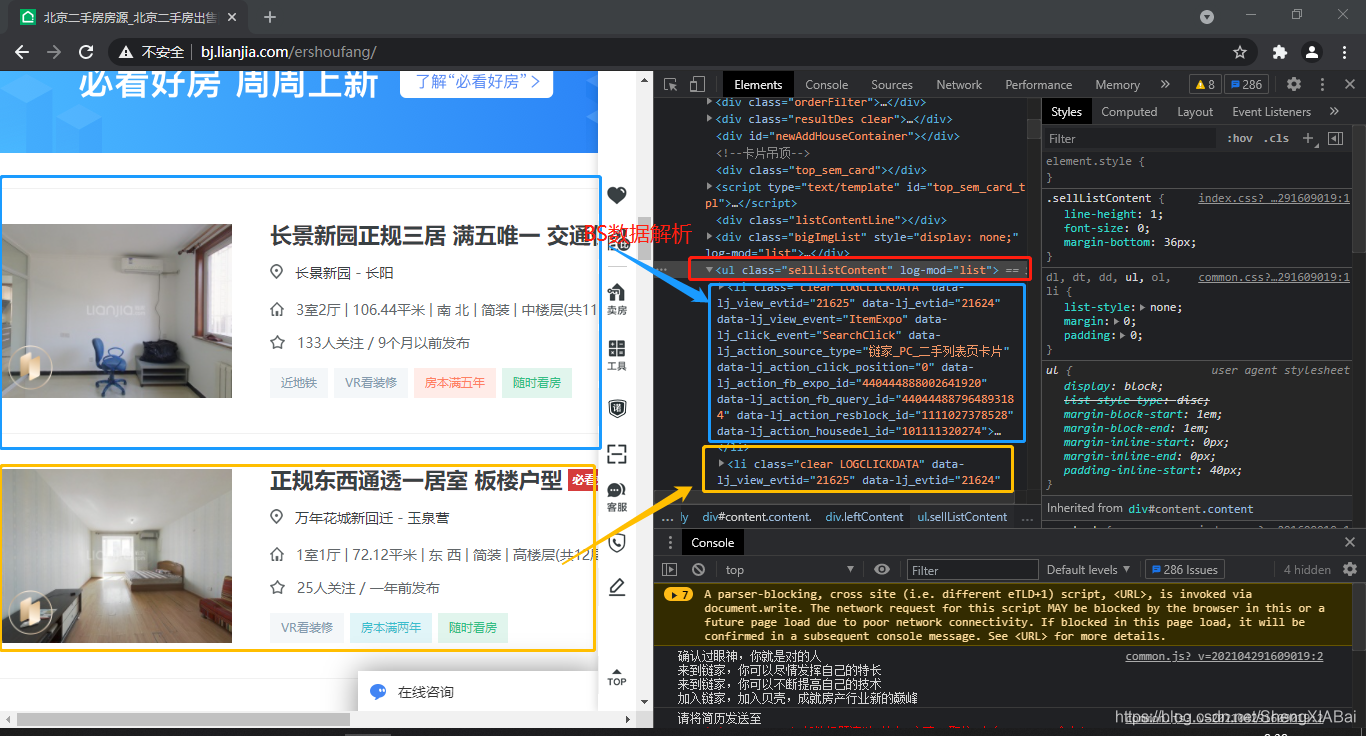
数据解析
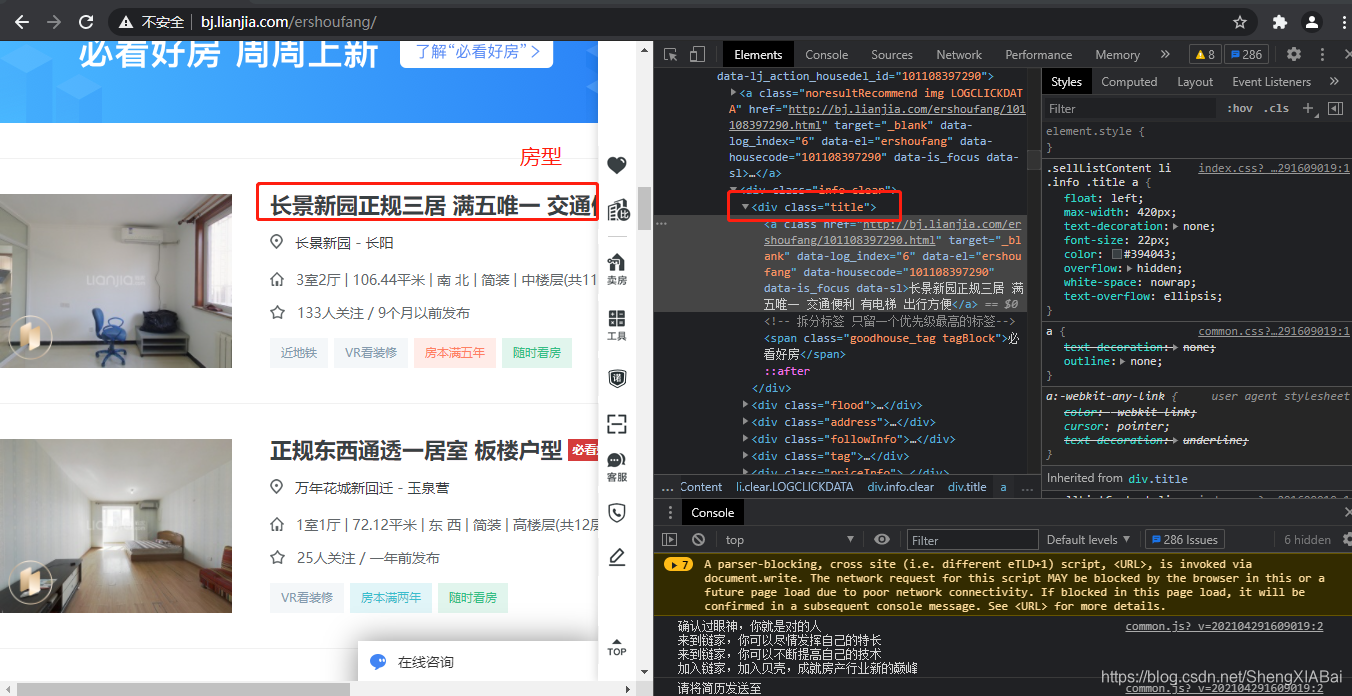
房名
房型信息
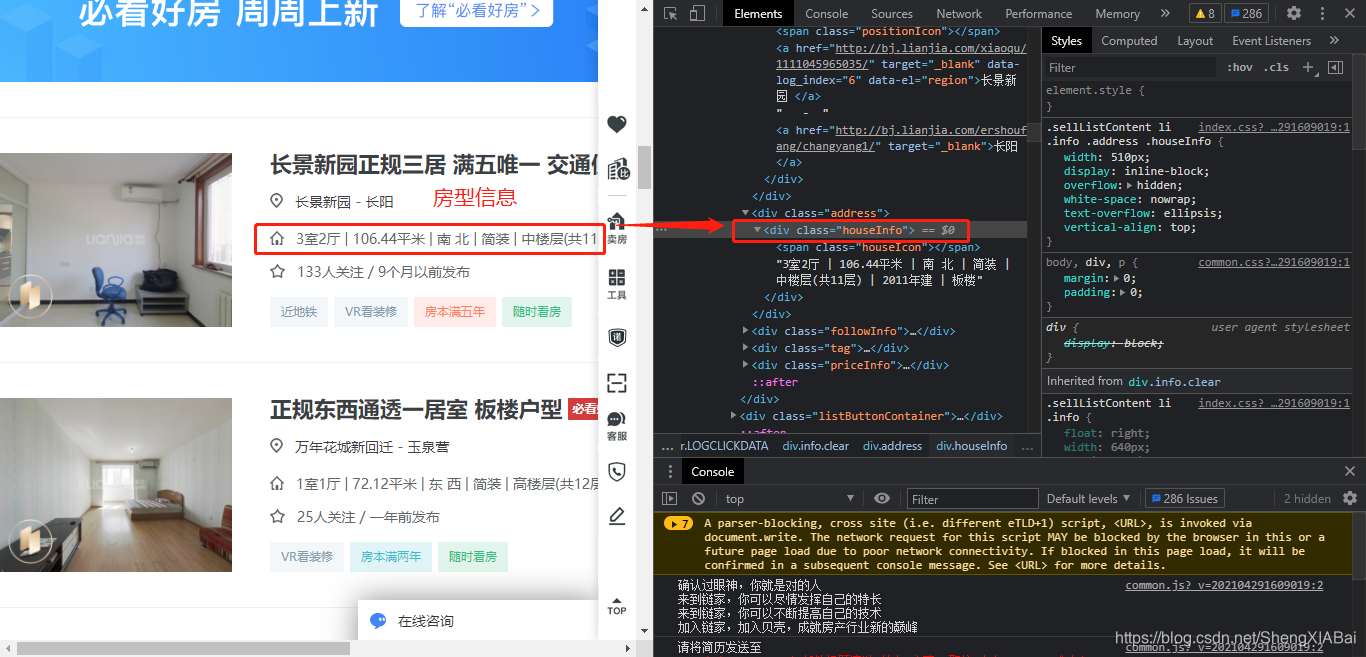
位置信息
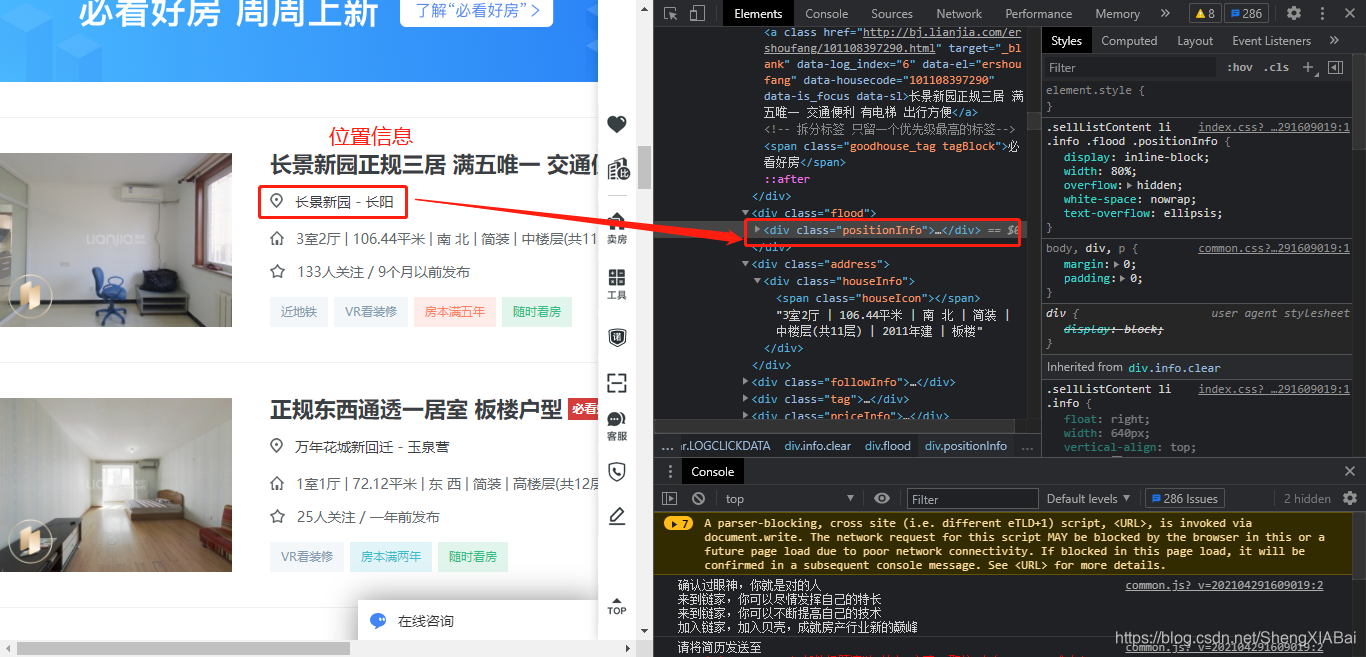
房屋售价

每平单价

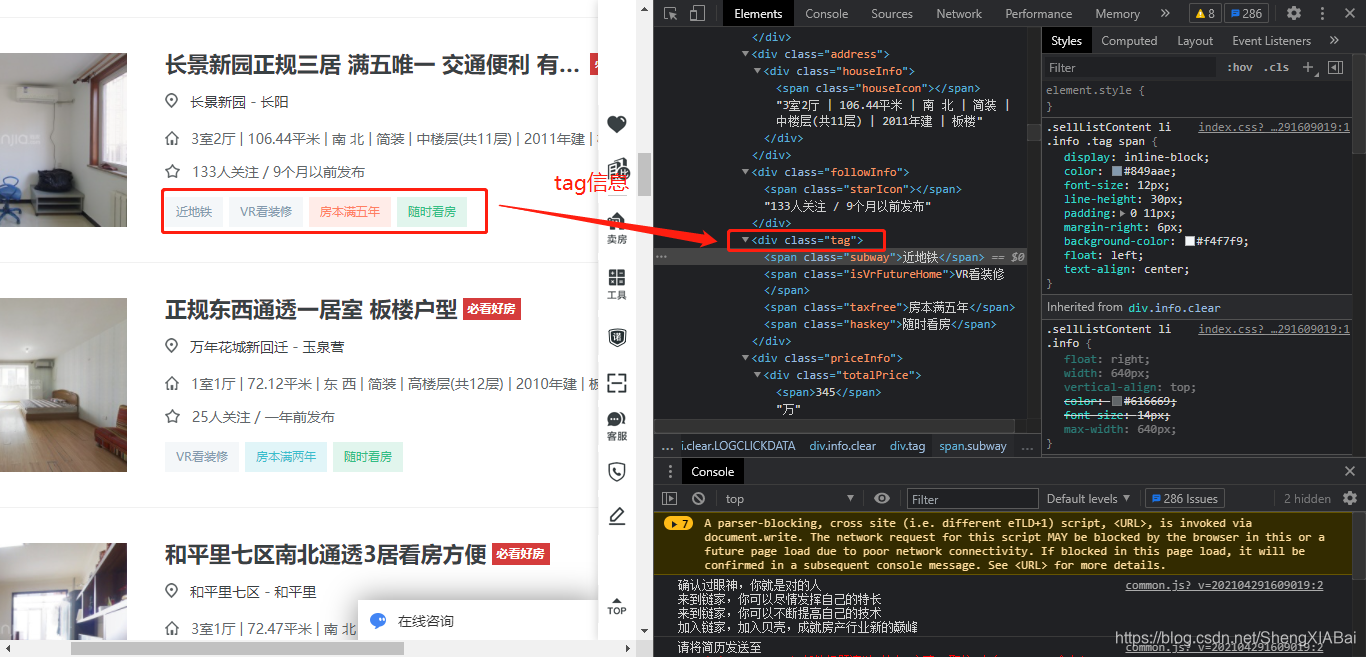
关注人数/发布时间

标签信息
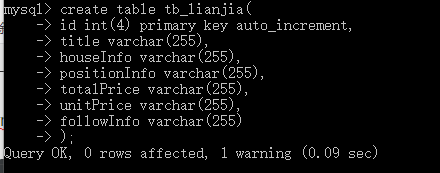
MySQL中创建数据表
pycharm中创建SQL文件

具体实现代码
import requests
from bs4 import BeautifulSoup
import pymysql
class LianJiaSpider():
# 打开数据库连接
db = pymysql.connect(host='localhost', port=3306, user='root', password='123456', db='test', charset='utf8')
# 使用cursor()方法获取操作游标
cursor = db.cursor()
def __init__(self):
self.url = 'http://bj.lianjia.com/ershoufang/pg{0}/' #{
0}表示字符串的格式化
self.heasers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36'}
def send_requests(self,url):
'''发送请求'''
resp = requests.get(url,headers=self.heasers)
if resp.status_code == 200: #判断响应状态码,200时正常返回数据
return resp
def parse_html(self,resp):
'''解析数据'''
lst = [] #用于存放数据
html = resp.text
bs = BeautifulSoup(html,'lxml')
ul = bs.find('ul',class_='sellListContent')
li_list = ul.find_all('li')
#print(len(li_list)) #检查是否获取到数据
for item in li_list:
title = item.find('div',class_='title').text #循环获得标题的文本内容
houseInfo = item.find('div',class_='houseInfo').text #获取每套房子的房型信息
positionInfo = item.find('div',class_='positionInfo').text #获取每套房子的位置信息
totalPrice = item.find('div',class_='totalPrice').text #获取每套房子的销售总价
unitPrice = item.find('div',class_='unitPrice').text #获取每套房的单价
followInfo = item.find('div',class_='followInfo') #获得每套房的关注信息
if followInfo != None: #去除空值数据
followInfo = followInfo.text
else:
followInfo = ''
#print(title) #输出房名
#print(houseInfo) #输出房型信息
#print(positionInfo) # 输出位置信息
#print(totalPrice) #输出销售总价
#print(unitPrice) #输出房屋单价信息
#print(followInfo) #输出每套房的关注信息
lst.append((title,houseInfo,positionInfo,totalPrice,unitPrice,followInfo))
#print(lst)
self.save(lst) #调用save函数存储数据
def save(self,lst):
'''存储数据'''
#print(self.db) #连接成功提示:<pymysql.connections.Connection object at 0x00000249256C4E48>
sql = 'insert into tb_lianjia (title,houseInfo,positionInfo,totalPrice,unitPrice,followInfo) values (%s,%s,%s,%s,%s,%s)'
self.cursor.executemany(sql,lst)
self.db.commit()
print(self.cursor.rowcount,'插入成功')
def start(self):
'''启动爬虫程序'''
for i in range(1,2): #当前只爬取一页数据,若为多页修改range函数范围即可
full_url = self.url.format(i) #完整URL的拼接
resp = self.send_requests(full_url) #拼接后发送请求
#print(resp.text)
self.parse_html(resp)
if __name__ == '__main__':
lianjia = LianJiaSpider()
lianjia.start()
结果