这篇文章旨在用通俗的语言描述清楚这三个货到底有什么关系,具体功能不做细节解释。如有错误,理解万岁~~~。
分别描述
RDD:spark 1.0 时出现了 RDD (Resilient Distributed Dataset) 弹性分布式数据集,顾名思义这玩意是保存数据的,为何叫分布式?是因为当我们操作RDD实力时虽只写了一行代码实际上处理的是存储在几台甚至几十台服务器上的数据。至于弹性,当RDD中的数据丢失后还能重新计算出来,有一定的容错能力。RDD api 提供一些转换方法(map、filter、reduce)做数据处理,这些方法的返回结果依旧是个 rdd 实例。
RDD api 两个缺点:(1)没有内置优化引擎,当处理结构化数据时,RDD 不能很好的利用spark 高级的优化器,比如:catalyst optimizer 和 Tungsten execution engine,每个 RDD 优化全凭开发者自己努力。(2)它里面对于结构化数据的定义和表达都不是很人性化,可读性差。
DataFrame: spark 1.3 时出现了 DataFrame ,在原有 RDD 的功能基础上内置了优化器旨在提高 spark 的性能和可扩展性。DataFrame 实例使用表格形式存储结构化数据,就像关系型数据库表一样,大大增加了可读性。并且支持 Scala、Java、Python、R语言。前面提到,DF 保存结构化数据像 mysql 表一样可读性很高,但是当读取字段时它在编译器不对字段名做检查,这就很可能导致开发者大意写错了字段名,导致程序在运行时抛异常。还有个拉胯的点是 DF api 虽支持 Java、Python 但其语法风格更像 Scala。而 Scala 语法跟诡异,对新手不是很友好。
Datasets:spark 1.6 时出现了 Datasets,它是集上述两者之大成。RDD(函数式编程、类型安全) ,DataFrame (关系模型、查询优化、执行优化、存储和 shuffle)。语法上支持 Scala、Java,spark 2.0 开始支持 Python 和 R。DF 不支持的属性检查,DataFrame 也支持了。
总体关系
从上面可以看出三者都有弹性分布式数据集的功能,时随时间不短更新的产物。下面贴两张图展示他们之间关系。
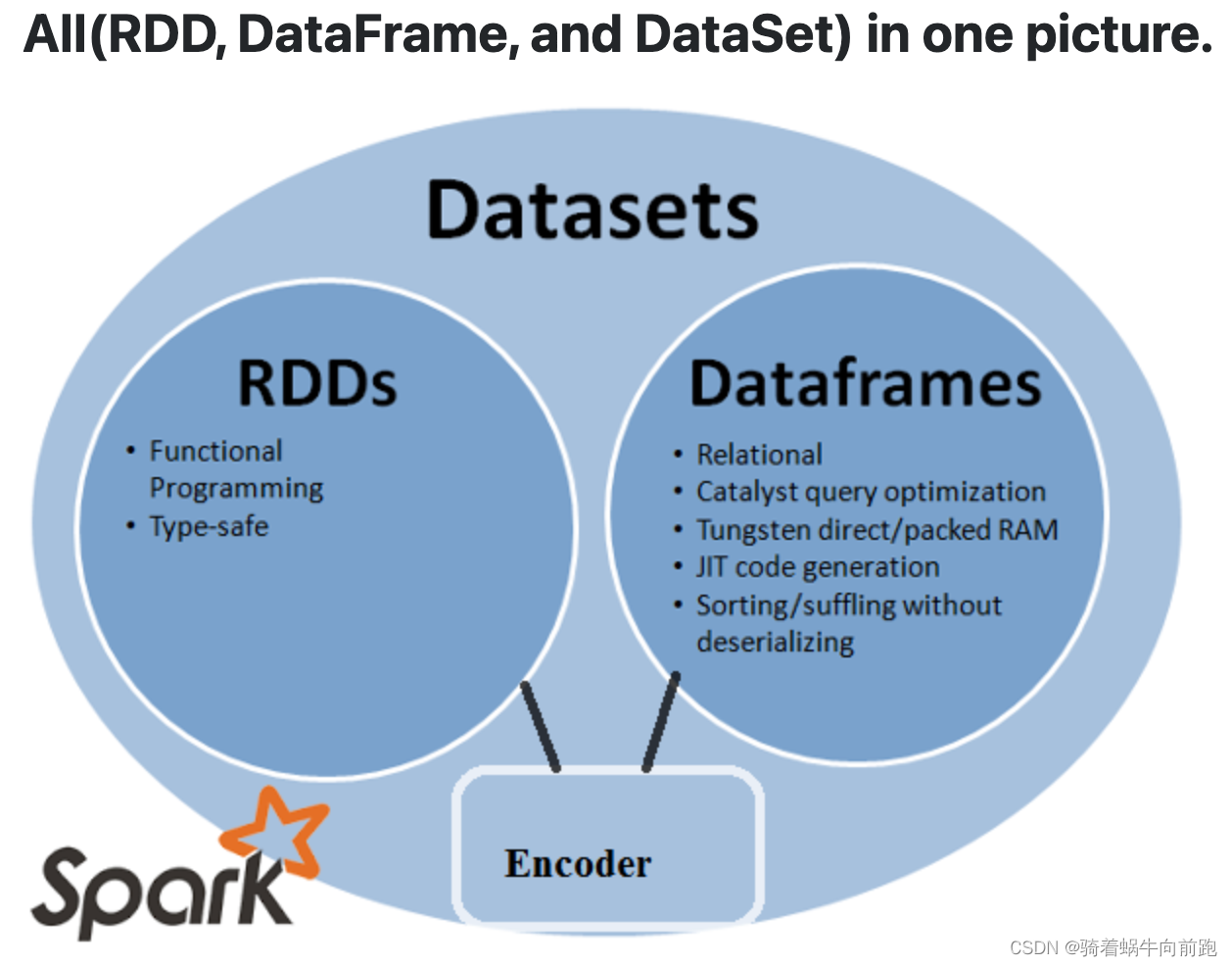
从这张图看起来现在应该使用 Datasets 的多,但在代码中看到大多数场景中使用的 DataFrame。

从这张图看出,DataFrame、Dataset 都是按照一系列规则转化成 RDD 才执行操作。在一定程度上可以说这两个都是基于 RDD 的功能封装。
参考链接
https://stackoverflow.com/questions/31508083/difference-between-dataframe-dataset-and-rdd-in-spark