转眼就到11月份了,本以为能在湖南过一个浪漫的秋天,但是没想到今年的湖南没有秋天,直接到了寒风刺骨的冬天。。。

于是,赶紧打开了Python,用它爬取并分析一波棉袄,找到一件最合适的棉袄给裹到身上。
数据采集
数据采集是数据可视化分析的第一步,也是最基础的一步,数据采集的数量和质量越高,后面分析的准确的也就越高,我们来看一下淘宝网的数据该如何爬取。
淘宝网站是一个动态加载的网站,我们之前可以采用解析接口或者用Selenium自动化测试工具来爬取数据,但是现在淘宝对接口进行了加密,使我们很难分析出来其中的规律,同时淘宝也对Selenium进行了反爬限制,所以我们要换种思路来进行数据获取。
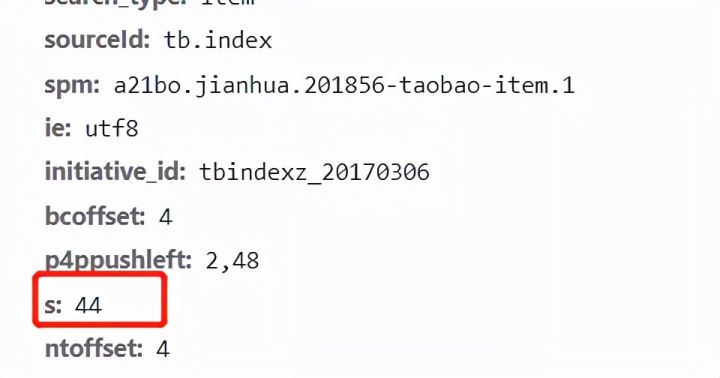
打开开发者模式,开始对网页进行观察后发现,淘宝商品的数据竟然在源网页中存储着。

我翻了几页网页之后发现,每翻一页,网页的params参数中的s参数就会增加44(初始值是0)。
经过以上分析,现在我们就可以开始构造爬虫程序了。
01
导入爬虫使用的库
import requests
import re
import time
import random
import openpyxl
02
发起请求
for page in range(1,101):
params = (
('q', '棉袄'),
('imgfile', ''),
('commend', 'all'),
('ssid', 's5-e'),
('search_type', 'item'),
('sourceId', 'tb.index'),
('spm', 'a21bo.jianhua.201856-taobao-item.2'),
('ie', 'utf8'),
('initiative_id', 'tbindexz_20170306'),
('hintq', '1'),
('s', str(page*44)),
)
response = requests.get(url, params=params)
03
数据存储
a = 0
b = 0
for i in range(44):
try:
sheet.append([dianpumingcheng[i],shangpinming[i],float(jiage[i]),fahuodi[i],fukuanrenshu[i]])
except:
a+=1
if a>30:
print(f"第{page}页数据未爬取......")
wb.save('棉袄.xlsx')
# 把xxx改成你想要的存储的名称即可
b = 1
break
if b == 1:
break
print(f"已爬取完第{page}页数据......")
time.sleep(random.randint(3,5))
print(f'共爬取{page}页数据......')
02
数据清洗
数据采集后,要对其进行清洗,剔除脏数据,用以提高分析的准确性。
01
导入商品数据
用pandas读取爬取后的商品数据并预览。
import pandas as pd
df = pd.read_excel('棉袄.xlsx',names=['店铺名称','商品名','价格','产地','付款人数'])
print(df.head())

02
删除重复数据

df.drop_duplicates()
删除重复数据后,还有2008条数据。
03
数据类型转换
我们发现付款人数是字符串类型,我们需要将其转换成整数类型。
wb = openpyxl.load_workbook('棉袄.xlsx')
int_list = []
sheet = wb['Sheet']
for i in range(2,2008):
str = sheet[f'E{i}'].value
if '万+' in str:
int_list.append(int(int(str[:-2])*random.uniform(1,2)*10000))
elif '+' in str:
int_list.append(int(int(str[:-1])+random.random()*1000))
else:
int_list.append(int(str))
for i in range(2,2008):
sheet.cell(i,5).value = int_list[i-2]
wb.save('3.xlsx')
04
查看数据类型
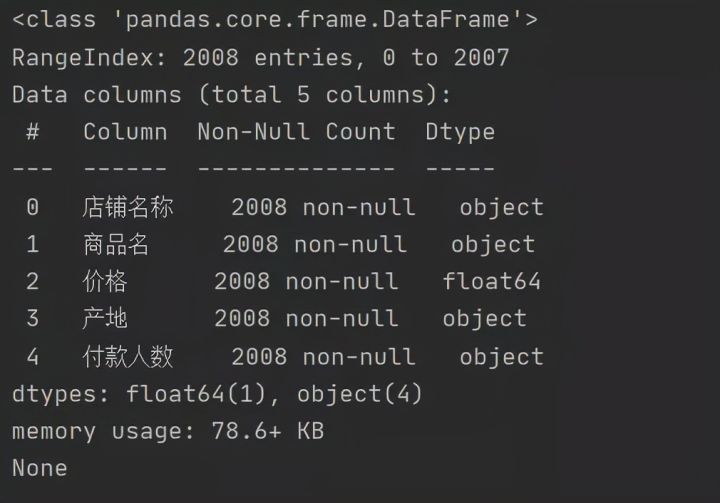
查看字段类型和缺失值情况,符合分析需要,无需另做处理。
df.info()
03
可视化分析
我们来对这2008家棉袄商品数据进行可视化分析。可视化图是由Python、Tableau和Excel共同绘制而来。
01
在售棉袄特点
通过对棉袄的商品名称进行词云图绘制,我们发现,今年棉袄的样式以宽松、潮流、韩版、短款类居多。

制作代码如下:
from imageio import imread
import jieba
from wordcloud import WordCloud, STOPWORDS
with open("1.txt",'r',encoding='utf-8') as f:
job_title_1 = f.read()
contents_cut_job_title = jieba.cut(job_title_1)
contents_list_job_title = " ".join(contents_cut_job_title)
wc = WordCloud(stopwords=STOPWORDS.add("一个"), collocations=False,
background_color="white",
font_path=r"K:\msyh.ttc",
width=400, height=300, random_state=42,
mask=imread('棉袄.jpg', pilmode="RGB")
)
wc.generate(contents_list_job_title)
wc.to_file("推荐语.png")
02
各省产量分布图
通过对各商品的产地数据进行统计并绘制了全国地图,我们发现浙江、广东和福建这三个地方生产棉袄最多,分别是914家、261家和203家。

制作代码如下:
import openpyxl
from collections import Counter
from pyecharts import Map
wb = openpyxl.load_workbook('棉袄.xlsx')
sheet = wb['Sheet']
a = []
for i in range(2,1960):
D = sheet[f'D{i}']
a.append(D.value)
province_distribution = dict(Counter(a))
provice = list(province_distribution.keys())
values = list(province_distribution.values())
map = Map("中国地图",width=1200, height=600)
map.add("", provice, values, visual_range=[0, 50], maptype='china', is_visualmap=True,
visual_text_color='#000',is_label_show=True)
map.render(path="地图.html")
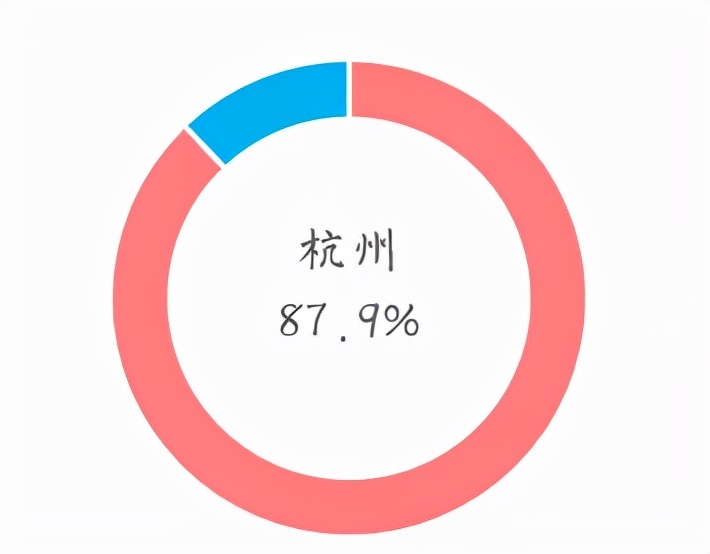
我们进一步对浙江省的产地数据进行分析发现,杭州的棉袄商家最多,占全省的40%。
03
棉袄价格区间分布
我们对棉袄价格以100为分点,进行可视化后发现,价格在100-200的棉袄商品最多,有869家,其次是价格在201-300之间的,有501家。看来棉袄的价格还是相对便宜的~

04
棉袄月销量top20商家
销量最高的竟然不是旗舰店,是一个李广森的自制时尚女装店,志斌打开她们家的店铺看了看,感觉还不错,可以给对象入手一套~
