本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于志斌的python笔记 ,作者 志斌
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542 Python学习交流群:1039649593
前言
要说最近哪种水果最火,那就不得不说说菠萝了。随着“每3个中国菠萝就有1个来自徐闻”的话题登上各大平台热搜。徐闻菠萝迅速成为消费市场的热门商品。
随着徐闻菠萝高铁的开通大大降低了菠萝的运输成本和时间成本,这意味着我们可以以更低的价格吃上更新鲜的菠萝。在这种情况下,你还会担心网购的不新鲜吗?
数据获取
本文利用Python详细采集了淘宝网1774个商家菠萝的销售数据,获取到菠萝的店铺名称、商品名称、价格、产地、销量等数据,由于之前的文章已经详细介绍过淘宝网商家数据采集方法(不懂的看这篇文章用Requests+Cookie,轻松获取淘宝商品数据!),所以这里我们直接上代码:
response = requests.get('https://s.taobao.com/search', headers=headers, params=params)
shangpinming = re.findall('"raw_title":"(.*?)"',response.text)
jiage = re.findall('"view_price":"(.*?)"',response.text)
fahuodi = re.findall('"item_loc":"(.*?)"',response.text)
fukuanrenshu = re.findall('"view_sales":"(.*?)人付款"',response.text)
dianpumingcheng = re.findall('"nick":"(.*?)"',response.text)数据处理

我们打开Excel文件对数据进行观察,发现有很多重复的数据,如图:
可能是因为某些店铺数据在不同页面中也存在导致的,我们可以采用pandas对数据进行清洗,但是这里我们可以用一种更简单的方式来对重复数据进行清洗,那就是Excel,它自带有删除重复项的功能,如图:

数据处理后,数据预览:
数据可视化
本文采取Excel进行菠萝数据可视化,因为在绘图方面Excel甚至强于Python!
菠萝价格分布图
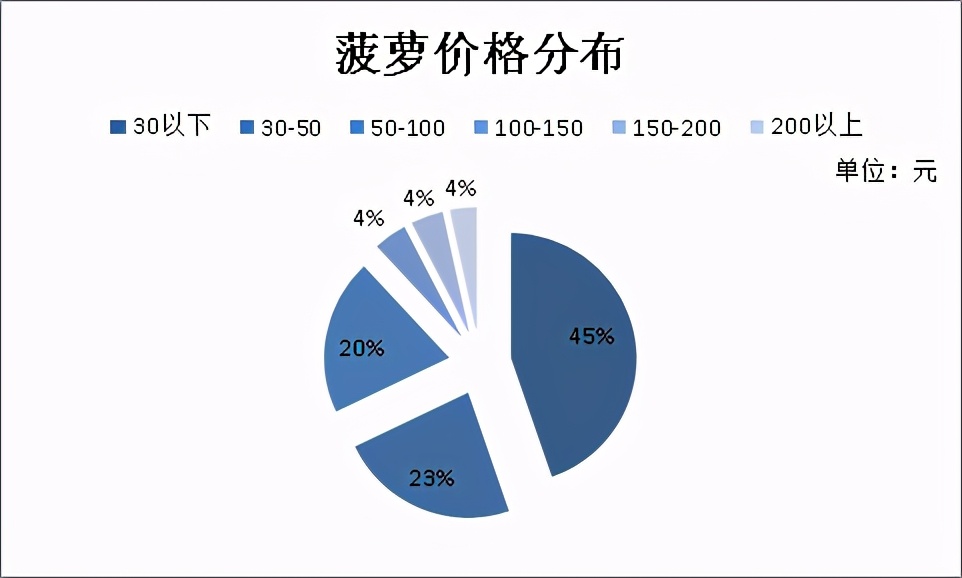
从图中可得菠萝的价格45%在30元以下,绝大多数的在100元以下,根据国家统计局公布的全国人均可支配收入来看,实现菠萝自由还是挺简单的。

那些店铺的销量较好
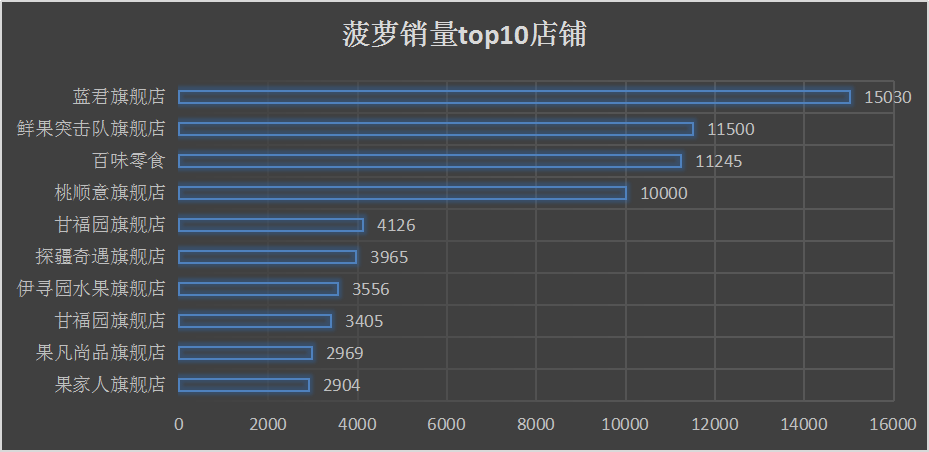
从图中我们可以看出,销量前十的店铺9个都是旗舰店,看来当价格较低时,人们更加的注重商品质量。
价格与销量之间的关系
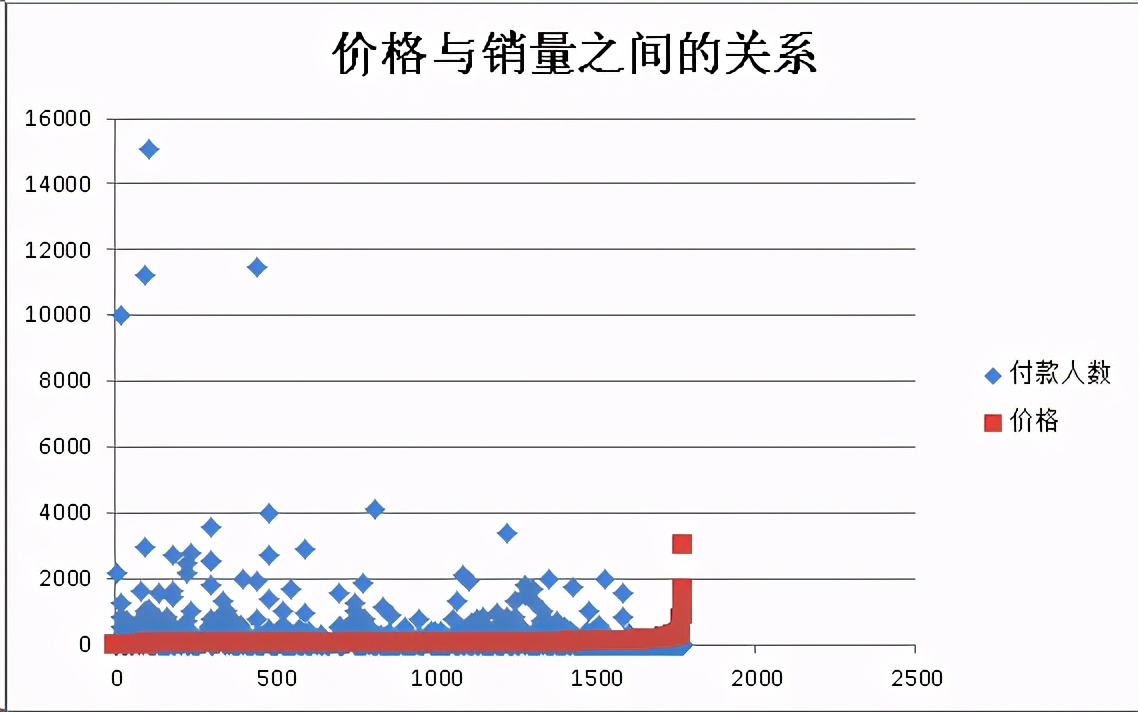
从散点图中我们可以看到,价格和销量基本上成反比,即价格越低,销量越高。
有三个点较高,可能是因为店铺的名气较大所导致的。
国内哪里盛产菠萝
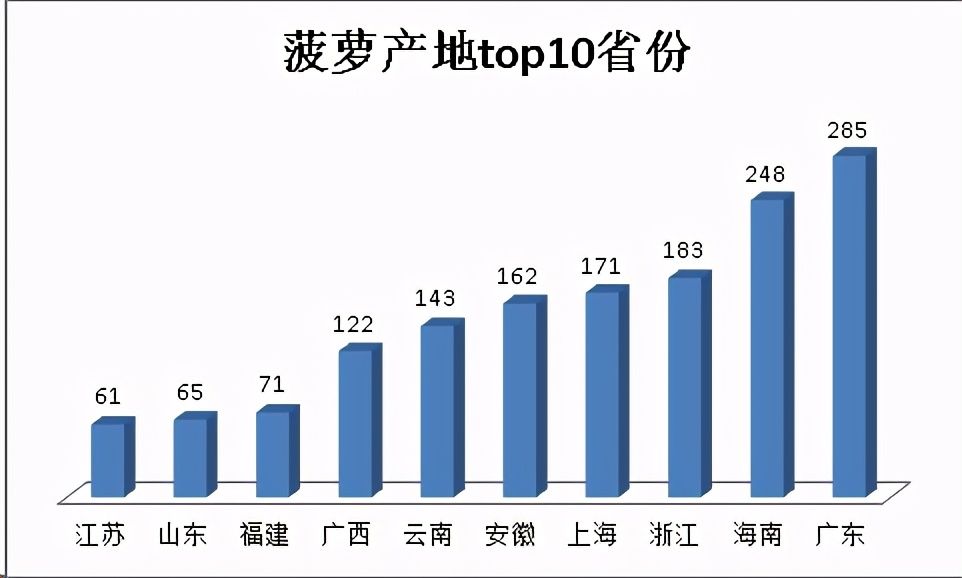
对淘宝店铺所在地进行可视化发现,大部分店铺集中在广东、海南、浙江这些沿海地区,我专门上网搜了一下菠萝生产的条件:

在售菠萝的特点

我们将所有的商品名称做成词云图,从词云图中我们可以看出,菠萝商品数据的关键字有:新鲜、凤梨、罐头、零食、海南。整箱、包邮等等。