
PyTorch | 一文学会 torch.nn 工具包 - Containers(容器)
- 一、class torch.nn.Parameter
- 二、class torch.nn.Module
-
- 2.1 构建模型
- 2.2 为模型添加子模型:add_module(name, module)
- 2.3 获取模型子模型:children()
- 2.4 获取模型子模型的名字和子模型本身:named_children()
- 2.5 获取所有模型的迭代器:modules()
- 2.6 获取所有模型的名字和模型本身的迭代器:named_modules()
- 2.7 获取模型参数的迭代器:parameters(recurse=True)
- 2.8 获取模型参数名字和参数本身的迭代器:named_parameters(prefix='', recurse=True)
- 2.9 获取模型缓冲区的迭代器:buffers(recurse=True)
- 2.10 获取模型缓冲区名字和缓冲区本身的迭代器:named_buffers(prefix='', recurse=True)
- 2.11 移动模型 parameters 和 buffer
- 2.12 转换数据类型
- 2.13 调整模型模式
- 2.14 前向传播函数 forward(*input)
- 2.15 梯度归 0 函数 zero_grad(set_to_none=False)
- 2.16 parameter、buffer 的创建与获取
- 2.17 hook 相关方法
- 三、class torch.nn.Sequential(* args)
- 四、class torch.nn.ModuleList(modules=None)
- 五、class torch.nn.ParameterList(parameters=None)
- 六、class torch.nn.ParameterDict(parameters=None)
t o r c n . n n \qquad torcn.nn torcn.nn 是一种专门为神经网络设计的模块化接口,里面包括了卷积,池化, R N N RNN RNN 等计算,以及其他如 L o s s Loss Loss 计算,可以把 t o r c h . n n torch.nn torch.nn 包内的各个类想象成神经网络的一层。
t o r c n . n n \qquad torcn.nn torcn.nn 里面的大部分类都是继承了父类 t o r c h . n n . M o d u l e s torch.nn.Modules torch.nn.Modules,即本质上所有 t o r c h . n n torch.nn torch.nn 中的层(如卷积、池化)都是 t o r c h . n n . M o d u l e s torch.nn.Modules torch.nn.Modules。
一、class torch.nn.Parameter
- c l a s s t o r c h . n n . P a r a m e t e r ( d a t a , r e q u i r e s _ g r a d ) class\ \ torch.nn.Parameter(data, requires\_grad) class torch.nn.Parameter(data,requires_grad):
示例:torch.nn.Parameter(torch.tensor(20211012.1139))data:参数的张量。requires_grad:是否需要计算梯度,默认为True。
\qquad torch.nn.Parameter是继承自torch.Tensor的子类,其主要作用是作为torch.nn.Module中的可训练参数使用。它与torch.Tensor的区别就是torch.nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而torch.nn.Module中非torch.nn.Parameter的普通tensor是不在parameter()这个迭代器中的。
注 \qquad 注 注:torch.nn.Parameter对象的requires_grad属性默认值是True,即是可被训练的,这与torth.Tensor对象的默认值相反。
二、class torch.nn.Module
\qquad torch.nn.Module是所有神经网络的基类,这个类的内部有多达48个函数,我们创建的任何模型都应该继承这个类。在pytorch里面一般是没有层的概念,层也是被当成一个模型来处理的,因此Module也可以包含其它的Module,即子模型,一个torch.nn.Module(例如:LeNet) 可以包含很多个子Module(例如:卷积层、池化层等),可以将子模块赋值给模型属性。
2.1 构建模型
\qquad 我们在定义自已的神经网络的时候,需要继承torch.nn.Module类,并重新实现__init__构造函数和forward方法。一般我们把神经网络中具有可学习参数的层(如:全连接层、卷积层等)放在__init__构造函数中;将不具有可学习参数的层(如:ReLU、dropout、BatchNormanation层等)可以放在__init__构造函数中,也可选择不放,若不放在构造函数__init__里,可在forward方法中使用torch.nn.functional进行代替。注:虽然dropout没有可学习参数,但建议还是使用nn.Dropout而不是nn.functional.dropout,因为dropout在训练和测试两个阶段的行为有所差别,使用nn.Module对象能够通过model.eval操作加以区分。
\qquad torch.nn.functional是一个很常用的类,nn.Module中的大多数layer在functional中都有一个与之对应的函数。functional中的函数与torch.nn.Module类的区别是:Module实现的层(layer)是一个特殊的类,都是由class Layer(nn.Module)定义,会自动提取可学习的参数;functional中的函数更像是纯函数,由def functional(input)定义。
\qquad 当我们将具有可学习参数的层放在构造函数中后,我们可以通过torch.nn.Parameter函数使得可学习参数以parameters的形式存在于torch.nn.Module中,并且可以通过parameters()函数或者named_parameters()函数以迭代器的方式返回可学习参数。所有放在构造函数__init__里面的层的都是这个模型的“固有属性”。下面我们继承torch.nn.Module类来建立一个简单的神经网络模型。
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 建立2个卷积子模型
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
# 构建前向计算过程
x = F.relu(self.conv1(x))
y = F.relu(self.conv2(x))
return y
model = Model()
print(model)
输出:

\qquad 上述代码就构建了一个神经网络模型Model,这个模型中含有两个子模型(Submodules):conv1,conv2,通过上面方式赋值的子模型会被注册。当调用.cuda()的时候,子模型的参数也会转换为cuda Tensor。
\qquad
2.2 为模型添加子模型:add_module(name, module)
\qquad 将一个子模型(Submodules)添加到当前模型module。可以通过给定的name属性对子模型(Submodules)进行访问。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
# 通过add_module添加子模型与2.1中self.conv1 = nn.Conv2d(1, 20, 5)这个增加module的方式等价
self.add_module("conv1", nn.Conv2d(1, 20, 5))
model = Model()
print(model)
输出:

通过给定的name属性 c o n v 1 conv1 conv1 对子模型(Submodules)进行访问:model.conv1

2.3 获取模型子模型:children()
\qquad 返回当前模型子模型的迭代器,重复的模型只被返回一次。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.children()) # generator迭代器类型 <generator object Module.children at 0x7f55e005cb30>
# for 循环子模型的迭代器
for sub_module in model.children():
print(sub_module)
输出:

2.4 获取模型子模型的名字和子模型本身:named_children()
\qquad 返回当前模型子模型名字和子模型本身的迭代器,重复的模型只被返回一次。与children()方法不同,named_children()方法还会返回子模型对应的name。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.named_children()) # generator迭代器类型 <generator object Module.named_children at 0x7f56d3056820>
# for 循环子模型名字和子模型本身的迭代器
for name, sub_module in model.named_children():
print("name:{}, sub_module:{}".format(name,sub_module))
输出:

2.5 获取所有模型的迭代器:modules()
\qquad 返回当前模型所有模型的迭代器,重复的模型只被返回一次。与children()方法不同,modules()方法还会返回当前模型module。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
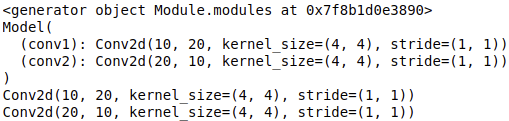
print(model.modules()) # generator迭代器类型 <generator object Module.modules at 0x7f8b1d0e3890>
for module in model.modules():
print(module)
输出:
2.6 获取所有模型的名字和模型本身的迭代器:named_modules()
\qquad 返回当前模型所有模型的迭代器,重复的模型只被返回一次。与named_children()方法不同,named_modules()方法还会返回当前模型module的名字和模型本身。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
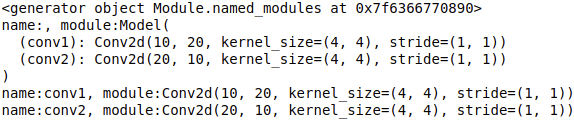
print(model.named_modules()) # generator迭代器类型 <generator object Module.modules at 0x7f6366770890>
for name, module in model.named_modules():
print("name:{}, module:{}".format(name,module))
输出:
2.7 获取模型参数的迭代器:parameters(recurse=True)
\qquad 如果rescue是True,那么返回一个包含当前模块及该模块子模块所有参数的迭代器;如果rescue是False,那么只返回一个包含当前模块所有参数的迭代器。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.parameters()) # generator迭代器类型 <generator object Module.modules at 0x7f4f279487b0>
for param in model.parameters():
print(type(param), param.size())
输出:

2.8 获取模型参数名字和参数本身的迭代器:named_parameters(prefix=’’, recurse=True)
\qquad 如果rescue是True,那么返回一个包含当前模块及该模块子模块所有参数名字和参数本身的迭代器;如果rescue是False,那么只返回一个包含当前模块所有参数名字和参数本身的迭代器。prefix表示添加到所有参数名字前方的前缀。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.add_module("conv2", nn.Conv2d(20 ,10, 4))
model = Model()
print(model.named_parameters()) # generator迭代器类型 <generator object Module.modules at 0x7f407c0257b0>
for name, param in model.named_parameters(prefix='dong'):
print("name:{}, | {}, | {}".format(name, type(param), param.size()))
输出:

2.9 获取模型缓冲区的迭代器:buffers(recurse=True)
\qquad 如果rescue是True,那么返回一个包含当前模块及该模块子模块所有缓冲区的迭代器;如果rescue是False,那么只返回一个包含当前模块所有缓冲区的迭代器。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.register_buffer("buffer1", torch.randn([2,3])) # register_buffer方法在之后会详细讲到
self.register_buffer("buffer2", torch.randn([2,3]))
model = Model()
print(model.buffers()) # generator迭代器类型 <generator object Module.modules at 0x7f2591cea970>
for buf in model.buffers():
print(type(buf), buf.size())
输出:

2.10 获取模型缓冲区名字和缓冲区本身的迭代器:named_buffers(prefix=’’, recurse=True)
\qquad 如果rescue是True,那么返回一个包含当前模块及该模块子模块所有缓冲区名字和缓冲区本身的迭代器;如果rescue是False,那么只返回一个包含当前模块所有缓冲区名字和缓冲区本身的迭代器。prefix表示添加到所有参数名字前方的前缀。举例来说:
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.register_buffer("buffer1", torch.randn([2,3])) # register_buffer方法在之后会详细讲到
self.register_buffer("buffer2", torch.randn([2,3]))
model = Model()
print(model.named_buffers()) # generator迭代器类型 <generator object Module.modules at 0x7f2591cea6d0>
for name, buf in model.named_buffers(prefix='dong'):
print("name:{}, | {}, | {}".format(name, type(buf), buf.size()))
输出:

2.11 移动模型 parameters 和 buffer
2.11.1 cpu()
\qquad 将所有的模型参数(parameters)和buffers移动到CPU,是一种in-place操作,即不经过复制操作,而是直接对原值进行修改。
2.11.2 xpu(device=None)
\qquad 将所有的模型参数(parameters)和buffers移动到XPU,是一种in-place操作,即不经过复制操作,而是直接对原值进行修改。如果指定device的话,所有的模型参数都会移动到指定的设备上。
2.11.3 cuda(device=None)
\qquad 将所有的模型参数(parameters)和buffers移动到GPU,是一种in-place操作,即不经过复制操作,而是直接对原值进行修改。如果指定device的话,所有的模型参数都会移动到指定的设备上。下面列举一些其他与GPU相关的方法:
torch.cuda.is_available():判断GPU是否可以使用。

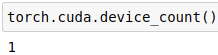
torch.cuda.device_count():返回可用的GPU数量。
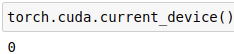
torch.cuda.current_device():返回当前所选设备的id。
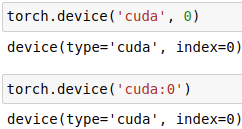
torch.device('cuda', 0)/torch.device('cuda:0'):指定GPU加速。
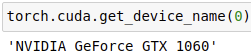
torch.cuda.get_device_name(0):获取id为0的GPU名称。
2.12 转换数据类型
2.12.1 double()
\qquad 将module模型中所有数据类型为浮点型的parameters和buffers转换成double数据类型。
2.12.2 float()
\qquad 将module模型中所有数据类型为浮点型的parameters和buffers转换成float数据类型。
2.12.3 half()
\qquad 将module模型中所有数据类型为浮点型的parameters和buffers转换成half数据类型。
2.12.4 bfloat16()
\qquad 将module模型中所有数据类型为浮点型的parameters和buffers转换成bfloat16数据类型。
\qquad
2.13 调整模型模式
\qquad 在构建好神经网络模型时,module都必须先要train,所以总是在训练状态,但如果是下载好别人已经训练好的模型module而不需要自己训练时,神经网络模型就应该变为evaluation评估模式。对于一些含有BatchNorm,Dropout等层的模型,在训练和验证时使用的forward在计算上不太一样,需要在forward的过程中指定当前模型是在训练还是在验证。
2.13.1 eval()
\qquad 将模型module调整为evaluation评估模式。等效于self.train(False) 。
2.13.2 train(mode=True)
\qquad 将该模块设置为train训练模式。默认值:True。
\qquad
2.14 前向传播函数 forward(*input)
\qquad forward方法定义了神经网络每次调用时都需要执行的前向传播计算,所有的子类都必须要重写这个方法。
\qquad
2.15 梯度归 0 函数 zero_grad(set_to_none=False)
\qquad 将所有模型参数的梯度设置为零。set_to_none=True会让内存分配器来处理梯度,而不是主动将它们设置为0,这样会适度加速。
\qquad
2.16 parameter、buffer 的创建与获取
\qquad 神经网络模型中需要保存下来的参数包括两种:一种是反向传播需要被优化器optimizer更新的,称之为parameter;另一种是反向传播不需要被优化器optimizer更新的,称之为buffer。pytorch一般情况下,是将网络中的参数保存成 OrderedDict 形式的。
2.16.1 parameter
1. 创建 parameter
- 通过成员变量创建
\qquad 我们可以直接将模型的成员变量self.****通过nn.Parameter()创建,会被自动注册到parameters中,并且通过这种方式创建的参数会被自动保存到OrderedDict中。self.my_param = nn.Parameter(torch.randn(5, 5)) # 模型的成员变量 register_parameter(name, param)
\qquad 我们可以通过nn.Parameter()创建普通的Parameter对象,不作为模型的成员变量,然后通过register_parameter函数注册Parameter对象,注册后的参数同样会被自动保存到OrderedDict中,通过指定的名字name可以访问该参数。param = nn.Parameter(torch.randn(5, 5)) # 普通 Parameter 对象 module.register_parameter("my_param", param)
2. 获取 parameter
get_parameter(target)
\qquad 根据给定target获取指定参数,如果存在则返回target对应的参数,否则抛出错误。
2.16.2 buffer
1. 创建 buffer
register_buffer(name, tensor, persistent=True)
\qquad 将tensor通过register_buffer进行注册,如果此缓冲区需要添加到OrderedDict则persistent需要设置为True,注册完成后buffer会自动保存到OrderedDict中,通过指定的名字name可以访问该缓冲区。
2. 获取 buffer
get_buffer(target)
\qquad 根据给定target获取指定缓冲区,如果存在则返回target对应的缓冲区,否则抛出错误。
2.16.3 get_submodule(target)
\qquad 根据给定target获取指定子模型,如果存在则返回target对应的子模型,否则抛出错误。
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.add_module("conv1", nn.Conv2d(10, 20, 4))
self.register_buffer("buffer1", torch.randn([2,3])) # register_buffer方法在之后会详细讲到
model = Model()
print(model.get_buffer("buffer1"))
print(model.get_parameter("conv1.weight").shape)
print(model.get_submodule("conv1"))
输出:

2.17 hook 相关方法
\qquad 钩子编程(hooking),也称作“挂钩”,是计算机程序设计术语,指通过拦截软件模块间的函数调用、消息传递、事件传递来修改或扩展操作系统、应用程序或其他软件组件的行为的各种技术。处理被拦截的函数调用、事件、消息的代码,被称为钩子(hook)。
\qquad 为了节省显存(内存),pytorch在计算过程中不保存中间变量,包括中间层的特征图和非叶子张量的梯度等。但是,正是因为pytorch计算图动态图的机制,所以才会有hook函数,如果我们对神经网络进行分析时需要查看或修改这些中间变量,就需要注册hook来导出需要的中间变量。利用它,我们可以不必改变网络输入输出的结构,方便地获取、改变网络中间层变量的值和梯度。hook相关的方法有四种:
torch.Tensor.register_hook()torch.nn.Module.register_forward_hook()torch.nn.Module.register_backward_hook()torch.nn.Module.register_forward_pre_hook()
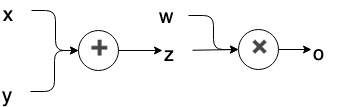
\qquad 在PyTorch的计算图(computation graph)中,只有叶子结点(leaf nodes)的变量会保留梯度。而所有中间变量的梯度只被用于反向传播,一旦完成反向传播,中间变量的梯度就将自动释放,从而节约内存。现在使用下方代码和计算图来进行演示,如下方计算图所示,x,y,w为叶子节点,而z为中间变量。
import torch
x = torch.Tensor([0, 1, 2, 3]).requires_grad_()
y = torch.Tensor([4, 5, 6, 7]).requires_grad_()
w = torch.Tensor([1, 2, 3, 4]).requires_grad_()
z = x + y
# z.retain_grad()
o = w.matmul(z)
# o.retain_grad()
o.backward()
print('x.requires_grad:', x.requires_grad)
print('y.requires_grad:', y.requires_grad)
print('z.requires_grad:', z.requires_grad)
print('w.requires_grad:', w.requires_grad)
print('o.requires_grad:', o.requires_grad)
print()
print('x.grad:', x.grad)
print('y.grad:', y.grad)
print('w.grad:', w.grad)
print('z.grad:', z.grad)
print('o.grad:', o.grad)
计算图:
输出:
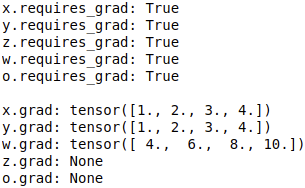
\qquad 由于z和o为中间变量(并非直接指定数值的变量,而是由别的变量计算得到的变量),它们虽然requires_grad的参数都是True,但是反向传播后,它们的梯度并没有保存下来,而是直接删除了,因此是None。
\qquad 如果想在反向传播之后保留它们的梯度,则需要特殊指定:把上面代码中的z.retain_grad()和o.retain_grad的注释去掉,可以得到它们对应的梯度,运行结果如下所示:
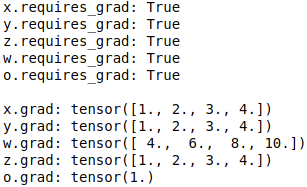
\qquad 但是,这种加retain_grad()的方案会增加内存占用,并不是个好办法,对此的一种替代方案,就是用hook保存中间变量的梯度(注:这种方式的梯度也并没有直接保存下来,只能在hook方法中对梯度进行操作,例如:打印、修改)。
2.17.1 torch.Tensor.register_hook(hook_fn)
\qquad 注册一个反向传播hook函数hook_fn,register_hook函数接收一个输入参数hook_fn,为自定义函数名称。在每次调用backward函数之前都会先调用hook_fn函数。hook_fn函数同样接收一个输入参数,为torch.Tensor张量的梯度。使用方法如下所示:
import torch
# x,y 为leaf节点,也就是说,在计算的时候,PyTorch只会保留此节点的梯度值
x = torch.tensor([3.], requires_grad=True)
y = torch.tensor([5.], requires_grad=True)
# a,b,c 均为中间变量,在计算梯度时,此部分会被释放掉
a = x + y
b = x * y
c = a * b
# 新建列表,用于存储hook函数保存的中间梯度值
a_grad = []
def hook_grad(grad):
a_grad.append(grad)
# register_hook的参数为一个函数
handle = a.register_hook(hook_grad)
c.backward()
# 只有leaf节点才会有梯度值
print('gradient:', x.grad, y.grad, a.grad, b.grad, c.grad)
# hook函数保留中间变量a的梯度值
print('hook函数保留中间变量a的梯度值:', a_grad[0])
# 移除hook函数
handle.remove()
2.17.2 torch.nn.Module.register_forward_hook(hook_fn)
\qquad 功能:用来导出指定子模型的输入输出张量,只能修改输出output的值,不能修改输入input的值(修改input值也无效),需要使用return返回修改后的output值使操作生效,register_forward_hook函数返回值默认赋值给output,常用来导出或修改卷积特征图。
\qquad 用法:在神经网络模型module上注册一个forward_hook函数hook_fn,register_forward_hook函数接收一个输入参数hook_fn,为自定义函数名称。注:在调用hook_fn函数的那个模型(层)进行前向传播并计算得到结果之后才会执行hook_fn函数,因此修改output值仅会对后续操作产生影响。hook_fn函数接收三个输入参数:module,input,output,其中module为当前网络层,input为当前网络层输入数据,output为当前网络层输出数据。下面代码执行的功能是 3 × 3 3 \times 3 3×3 的卷积和 2 × 2 2 \times 2 2×2 的池化。我们使用register_forward_hook函数记录中间卷积层输入和输出的feature map。
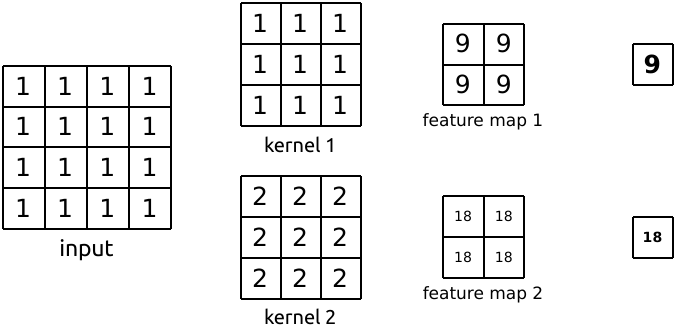
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
print("-------------执行forward函数-------------")
print("卷积层输入:",x)
x = self.conv1(x)
print("卷积层输出:",x)
x = self.pool1(x)
print("池化层输出:",x)
print("-------------结束forward函数-------------")
return x
# module为net.conv1
# data_input为net.conv1层输入
# data_output为net.conv1层输出
def forward_hook(module, data_input, data_output):
print("-------------执行forward_hook函数-------------")
input_block.append(data_input)
fmap_block.append(data_output)
#print("修改前的卷积层输出:{}".format(data_output))
#data_output = torch.rand((1, 1, 4, 4))
#print("修改后的卷积层输出:{}".format(data_output))
print("-------------结束forward_hook函数-------------")
#return data_output
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
handle = net.conv1.register_forward_hook(forward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
handle.remove()
# 观察
print("神经网络模型输出:\noutput shape: {}\noutput value: {}\n".format(output.shape, output))
输出:

2.17.3 torch.nn.Module.register_forward_pre_hook(hook_fn)
\qquad 功能:用来导出或修改指定子模型的输入张量,需要使用return返回修改后的output值使操作生效。
\qquad 用法:在神经网络模型module上注册一个forward_pre_hook函数hook_fn,register_forward_pre_hook函数接收一个输入参数hook_fn,为自定义函数名称。注:在调用hook_fn函数的那个模型(层)进行前向传播操作之前会先执行hook_fn函数,因此修改input值会对该层的操作产生影响,该层的运算结果被继续向前传递。hook_fn函数接收两个输入参数:module,input,其中module为当前网络层,input为当前网络层输入数据。下面代码执行的功能是 3 × 3 3 \times 3 3×3 的卷积和 2 × 2 2 \times 2 2×2 的池化。我们使用register_forward_pre_hook函数修改中间卷积层输入的张量。
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
print("-------------执行forward函数-------------")
print("卷积层输入:",x)
x = self.conv1(x)
print("卷积层输出:",x)
x = self.pool1(x)
print("池化层输出:",x)
print("-------------结束forward函数-------------")
return x
# module为net.conv1
# data_input为net.conv1层输入
def forward_pre_hook(module, data_input):
print("-------------执行forward_pre_hook函数-------------")
input_block.append(data_input)
#print("修改前的卷积层输入:{}".format(data_input))
#data_input = torch.rand((1, 1, 4, 4))
#print("修改后的卷积层输入:{}".format(data_input))
print("-------------结束forward_pre_hook函数-------------")
#return data_input
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
input_block = list()
handle = net.conv1.register_forward_pre_hook(forward_pre_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
handle.remove()
# 观察
print("神经网络模型输出:\noutput shape: {}\noutput value: {}\n".format(output.shape, output))
输出:

2.17.4 torch.nn.Module.register_backward_hook(hook)
\qquad 网络在进行反向传播时,可以通过register_backward_hook来获取中间层的梯度输入和输出,常用来实现特征图梯度的提取。示例:未完待续
三、class torch.nn.Sequential(* args)
\qquad torch.nn.Sequential是一个继承自Module类的容器,Sequential容器内部实现了forward函数,Sequential容器会按照构造函数中神经网络模块被传递的顺序依次将其添加到计算图中进行执行,并将每一层以0,1,2,3...来命名。另外,Sequential容器也可以接收一个有序字典OrderedDict。
3.1 Sequential类的实现方式
3.1.1 构造函数
\qquad Sequential是一个有顺序的容器,将特定的神经网络模块按照传入构造函数的顺序依次添加到计算图中执行。示例如下:
import torch.nn as nn
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
print(model)
print(model[2]) # 利用索引获取指定层
输出:

3.1.2 有序字典 OrderedDict
\qquad 将特定的神经网络模块以有序字典(OrderedDict)参数的形式传入Sequential类。通过此种方式可以为每一个层赋予名称,并能够通过名称直接获取指定层。示例如下:
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
print(model)
# 利用索引获取指定层
print(model[0])
print(model[2])
# 利用名称获取指定层
print(model.conv1)
print(model.conv2)
输出:

3.1.3 添加层 add_module
\qquad add_module是Sequential类继承自父类Module的方法,可以为一个神经网络模型添加子模型。
import torch.nn as nn
from collections import OrderedDict
model = nn.Sequential()
model.add_module("conv1",nn.Conv2d(1,20,5))
model.add_module('relu1', nn.ReLU())
model.add_module('conv2', nn.Conv2d(20,64,5))
model.add_module('relu2', nn.ReLU())
print(model)
print(model[2]) # 利用索引获取指定层
输出:

四、class torch.nn.ModuleList(modules=None)
\qquad ModuleList是Module的子类,是一个储存不同module,并自动将每个module的parameter添加到网络中的容器。当添加ModuleList作为Module对象的一个成员时(即当我们添加模块到我们的网络时),所有ModuleList内部的Module的parameter也被添加作为我们网络的parameter。
4.1 创建 ModuleList
import torch.nn as nn
class net_modlist(nn.Module):
def __init__(self):
super(net_modlist, self).__init__()
# 创建 ModuleList
self.modlist = nn.ModuleList([
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
])
def forward(self, x):
for m in self.modlist:
x = m(x)
return x
net_modlist = net_modlist()
print(net_modlist)
for param in net_modlist.parameters():
print(type(param.data), param.size())
输出:

4.2 extend和append方法
\qquad 创建ModuleList对象后,该对象拥有extend和append方法,用法和python中一样,extend是在ModuleList对象尾端一次性追加另一个ModuleList 的多个值,append是在ModuleList对象尾端添加另一个module。
import torch.nn as nn
class net_modlist(nn.Module):
def __init__(self):
super(net_modlist, self).__init__()
self.modlist = nn.ModuleList([
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
])
def forward(self, x):
for m in self.modlist:
x = m(x)
return x
net_modlist = net_modlist()
print(net_modlist)
net_modlist.modlist.extend([nn.Conv2d(1, 10, 5),nn.ReLU(),nn.Conv2d(10, 64, 5),nn.ReLU()])
net_modlist.modlist.append(nn.Conv2d(1, 10, 10))
for param in net_modlist.parameters():
print(type(param.data), param.size())
输出:

4.3 Sequential 与 ModuleList 的区别
4.3.1 forward 函数实现与否
\qquad Sequential内部实现了forward函数,因此可以不用重写forward函数。而ModuleList则没有实现内部forward函数,需要重写forward函数。
4.3.2 赋予网络层名称
\qquad Sequential可以使用OrderedDict对每层进行命名,ModuleList则只能采用默认的命名。
4.3.3 层级关系
\qquad Sequential里面的模块是按照顺序进行排列的,执行顺序也是按照排列顺序进行的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而ModuleList并没有定义一个网络,它只是将不同的模块储存在一起,ModuleList中的模块不能直接在forward中运行,并且这些模块之间没有先后顺序,模块的执行顺序是根据forward函数决定的。
五、class torch.nn.ParameterList(parameters=None)
\qquad ParameterList的作用是在列表中保存参数。ParameterList可以像普通Python列表一样进行索引、追加等操作,但是它所包含的参数要求是已经被Module正确注册,并且被所有的Module方法都可见。
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule,self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4,4)) for i in range(4)])
self.params.extend([nn.Parameter(torch.randn(3,3)),nn.Parameter(torch.randn(2,2))])
self.params.append(nn.Parameter(torch.randn(5,5)))
def forward(self,x):
for i in range(len(self.params)):
x = torch.mm(x,self.params[i])
return x
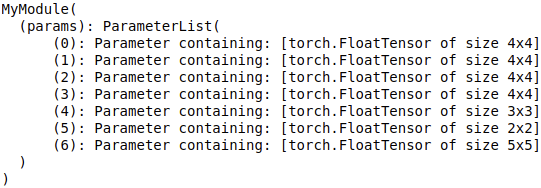
net = MyModule()
print(net)
输出:
六、class torch.nn.ParameterDict(parameters=None)
\qquad ParameterDict的作用是在字典中保存参数。ParameterDict可以像普通Python字典一样进行索引、删除等操作,但是它所包含的参数要求是已经被Module正确注册,并且被所有的Module方法都可见。
import torch
import torch.nn as nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.params = nn.ParameterDict({
'left': nn.Parameter(torch.randn(5, 10)),
'right': nn.Parameter(torch.randn(5, 10))
})
def forward(self, x, choice):
x = self.params[choice].mm(x)
return x
net = MyModule()
print(net)
输出:
