小白学Pytorch系列–Torch.nn API Sparse Layers(12)

| 方法 | 注释 |
|---|---|
| nn.Embedding | 一个简单的查找表,存储固定字典和大小的嵌入。 |
| nn.EmbeddingBag | 计算嵌入的“bags”的总和或方法,而不实例化中间嵌入。 |
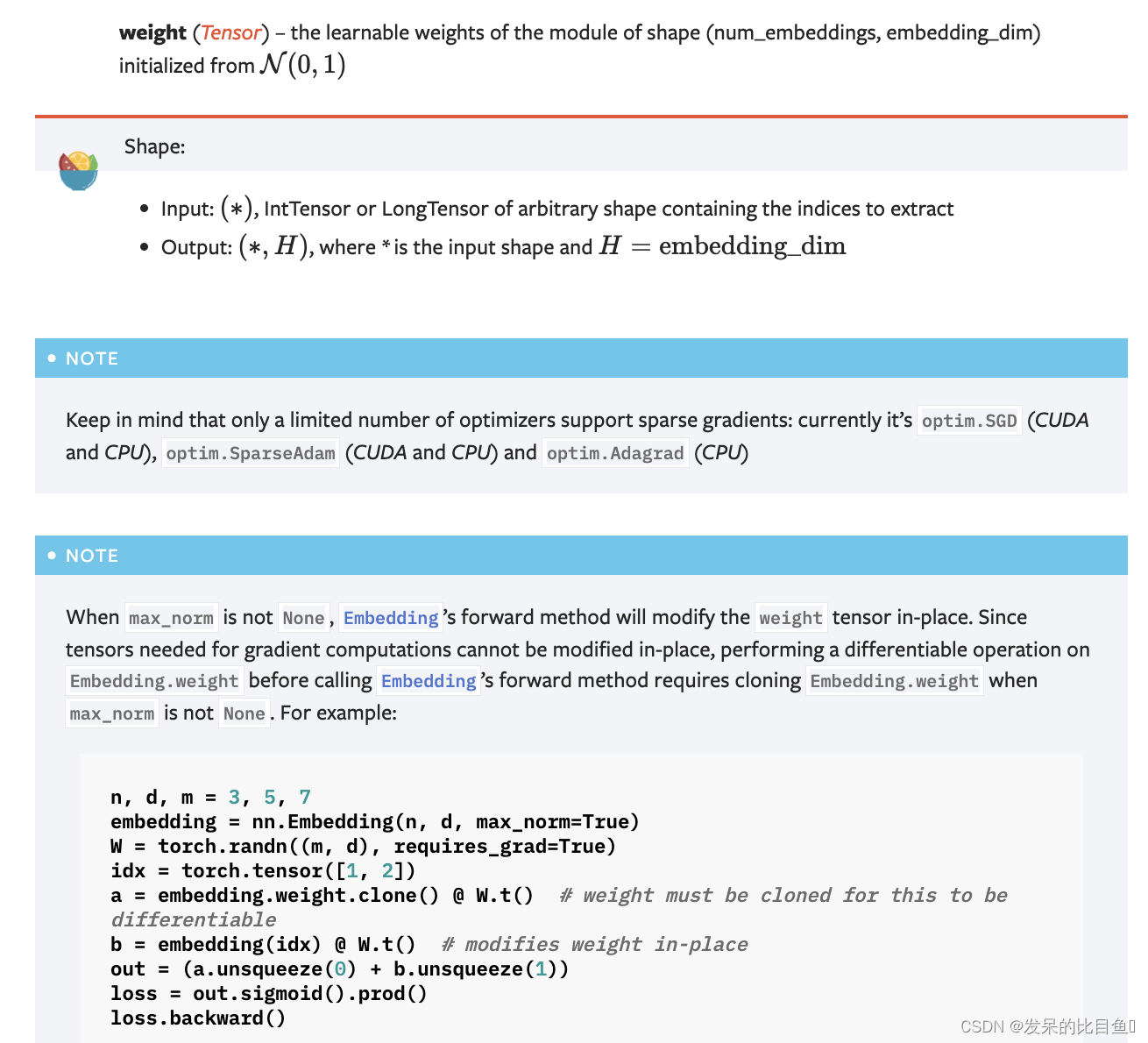
nn.Embedding
一个简单的查找表,用于存储固定字典和大小的嵌入。
该模块通常用于存储单词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的单词嵌入。

>>> # an Embedding module containing 10 tensors of size 3
>>> embedding = nn.Embedding(10, 3)
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
>>> embedding(input)
tensor([[[-0.0251, -1.6902, 0.7172],
[-0.6431, 0.0748, 0.6969],
[ 1.4970, 1.3448, -0.9685],
[-0.3677, -2.7265, -0.1685]],
[[ 1.4970, 1.3448, -0.9685],
[ 0.4362, -0.4004, 0.9400],
[-0.6431, 0.0748, 0.6969],
[ 0.9124, -2.3616, 1.1151]]])
>>> # example with padding_idx
>>> embedding = nn.Embedding(10, 3, padding_idx=0)
>>> input = torch.LongTensor([[0, 2, 0, 5]])
>>> embedding(input)
tensor([[[ 0.0000, 0.0000, 0.0000],
[ 0.1535, -2.0309, 0.9315],
[ 0.0000, 0.0000, 0.0000],
[-0.1655, 0.9897, 0.0635]]])
>>> # example of changing `pad` vector
>>> padding_idx = 0
>>> embedding = nn.Embedding(3, 3, padding_idx=padding_idx)
>>> embedding.weight
Parameter containing:
tensor([[ 0.0000, 0.0000, 0.0000],
[-0.7895, -0.7089, -0.0364],
[ 0.6778, 0.5803, 0.2678]], requires_grad=True)
>>> with torch.no_grad():
... embedding.weight[padding_idx] = torch.ones(3)
>>> embedding.weight
Parameter containing:
tensor([[ 1.0000, 1.0000, 1.0000],
[-0.7895, -0.7089, -0.0364],
[ 0.6778, 0.5803, 0.2678]], requires_grad=True)

>>> # FloatTensor containing pretrained weights
>>> weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
>>> embedding = nn.Embedding.from_pretrained(weight)
>>> # Get embeddings for index 1
>>> input = torch.LongTensor([1])
>>> embedding(input)
tensor([[ 4.0000, 5.1000, 6.3000]])
nn.EmbeddingBag
计算嵌入的“bags”的总和或平均值,而不实例化中间嵌入。



>>> # an EmbeddingBag module containing 10 tensors of size 3
>>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum')
>>> # a batch of 2 samples of 4 indices each
>>> input = torch.tensor([1, 2, 4, 5, 4, 3, 2, 9], dtype=torch.long)
>>> offsets = torch.tensor([0, 4], dtype=torch.long)
>>> embedding_sum(input, offsets)
tensor([[-0.8861, -5.4350, -0.0523],
[ 1.1306, -2.5798, -1.0044]])
>>> # Example with padding_idx
>>> embedding_sum = nn.EmbeddingBag(10, 3, mode='sum', padding_idx=2)
>>> input = torch.tensor([2, 2, 2, 2, 4, 3, 2, 9], dtype=torch.long)
>>> offsets = torch.tensor([0, 4], dtype=torch.long)
>>> embedding_sum(input, offsets)
tensor([[ 0.0000, 0.0000, 0.0000],
[-0.7082, 3.2145, -2.6251]])
>>> # An EmbeddingBag can be loaded from an Embedding like so
>>> embedding = nn.Embedding(10, 3, padding_idx=2)
>>> embedding_sum = nn.EmbeddingBag.from_pretrained(
embedding.weight,
padding_idx=embedding.padding_idx,
mode='sum')

>>> # FloatTensor containing pretrained weights
>>> weight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
>>> embeddingbag = nn.EmbeddingBag.from_pretrained(weight)
>>> # Get embeddings for index 1
>>> input = torch.LongTensor([[1, 0]])
>>> embeddingbag(input)
tensor([[ 2.5000, 3.7000, 4.6500]])