多因素房价预测分析案例
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/121125433(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 数据来源
本案例中的项目数据是在https://www.kaggle.com/camnugent/california-housing-prices上,该数据集是进行机器学习算法的极好入门资料,具有基本的数据分析清洗和易于理解的变量列表,并且数据量适中。
数据包含加州湾区房产信息。所提供的Zillow Zestimate数据集可以帮助我们预测当前的房价,可以用于向学员介绍机器学习的基础知识。
2 数据加载和基本的ETL
2.1 模块导入和数据加载
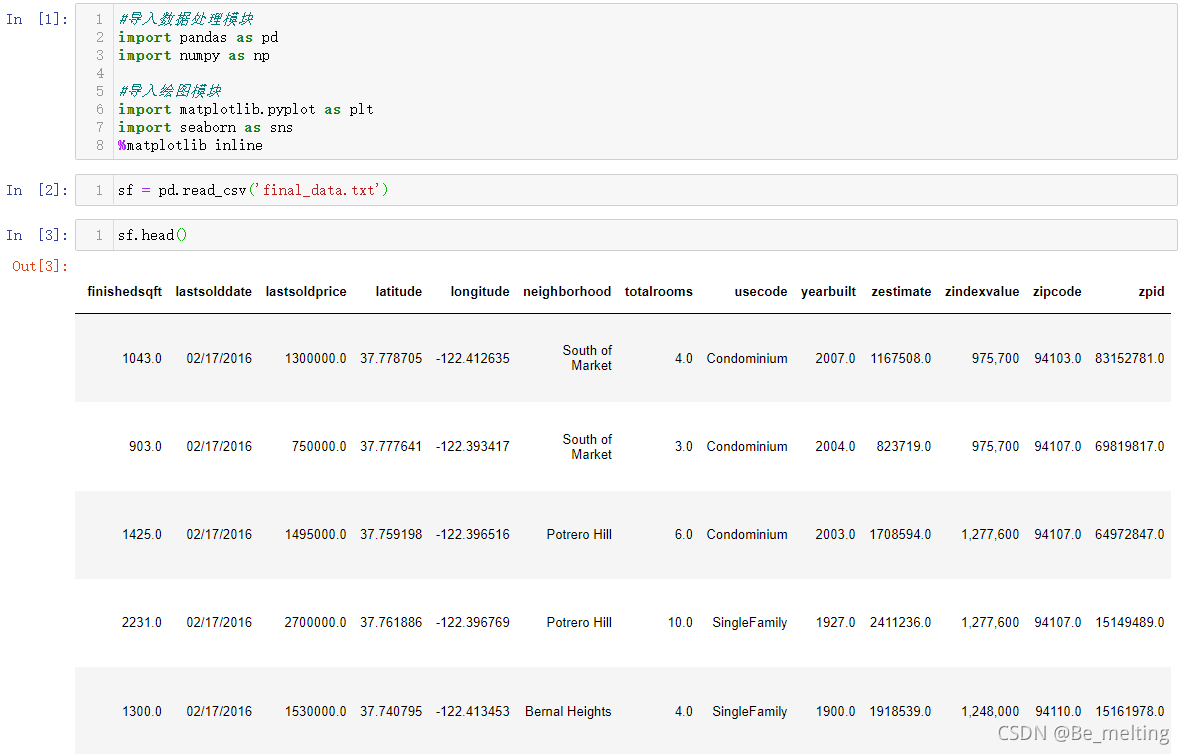
在jupyter notebook中的第一个cell中导入后续要使用的模块,然后进行数据的导入并查看数据的前五行。
2.2 数据清洗
首先对于一些没有实用意义的字段可以进行删除。通过进行数据集的字段名称查看,然后删除不需要的字段信息,可以直接指定删除字段的名称字符串,也可以指定字段对应的索引,默认是从0开始。

通过info()方法查看各字段的数据类型
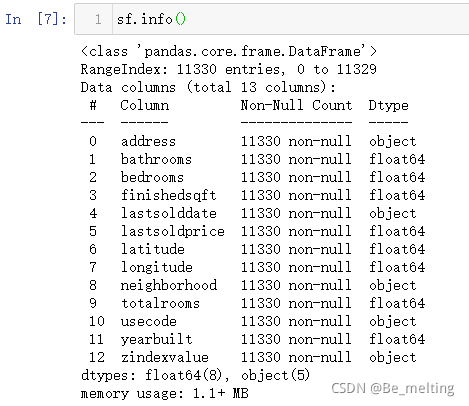
各字段的数据类型查看完毕后,可以对一些我们常见的或者觉得有误的数据类型进行转化,一般是需要进行一些数据处理的工作,比如这里的zindexvalue字段,理应属于数值信息,但是结果输出上面确实object字符串数据,因此需要进行清洗。观察该字段中都存在这逗号,可以进行替换为空,然后再使用转换数值的函数操作,输出结果如下。

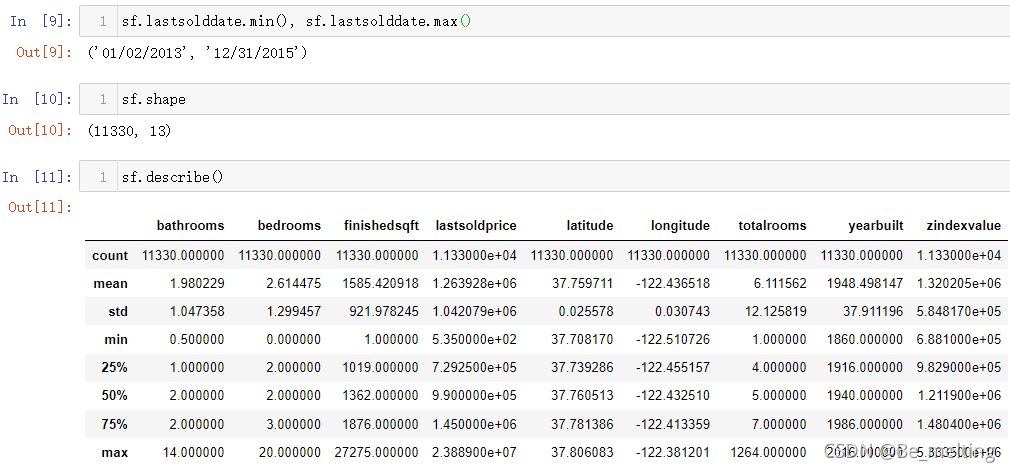
除此之外可以查看一下数据的维度,某字段的取值范围或者数据基本的分布情况,输出结果如下。
除了describe()方法进行数据分布的查看外,还可以通过绘制直方图进行直观的数据感受,代码输出如下。世界使用sf.hist()方法,结果会自动将数据集中的数值字段信息进行直方图的分布显示。

(1)对输出的结果为例进行解析,发现bathroom字段的信息每2个取值被划分为4个区域,比如0-2,划分结果为0-0.5,0.5-1,1-1.5,1.5-2,图形输出结果中0.5-1和1.5-2的区域数据分布最多,可以单独把这个字段拿出来进行计数统计,看一下详细的分布,操作及输出结果如下。绘制直方图只是为了让我们对数据的分布有一个粗略的认知,具体的数量,还是要进行value_counts()后才能知道。
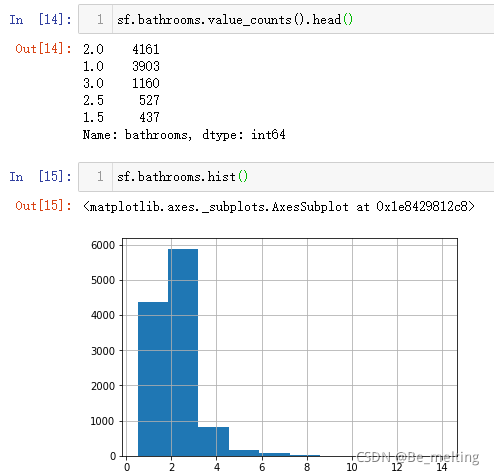
(2)对于bedrooms,也可以采用类似的方式进行分析,最终可知床的数量大多在1-4个之间,甚至还有没有床的房间以及数量超过20个床位的房间。
(3)对于房屋面积字段绘制的图形,显然图形中大部分的分布是在左侧,有少量的极值数据影响着数据的分布,对比前面的房间数量的分布,超多20个床位的房间,自然房屋的面积也相应很大,超过了25000美刀。
(4)房屋的价格自然和房屋的面积成正相关,这个是常识性的问题,所以也就可以直接解释两者的图形分布样式基本一致。最便宜的可以是免费的住房,最贵的甚至超过了 1.5 ∗ 1 0 7 1.5*10^7 1.5∗107 美刀
(5)对于经纬度数据,单独看各自的分布,就是只能看到一个范围,在数据可视化的过程中这两个字段通常是用来绘制地图的底图,稍后会进行呈现。
(6)totalrooms这里由于部分房子过大,里面的总共房间有超过1200间的现象,所以导致普遍存在1-5间的房子展示出鹤立鸡群的感觉。
(7)房屋建造的年代,主要分布在1880-2020年之间。
(8)zindexvalue字段表示房屋的评估价格,会和房屋的价格或者房屋的面积相关。
3 数据可视化
3.1 地理可视化
对于经纬度数据,可以直接拿过来使用,比如绘制散点图,操作及输出结果如下。图形绘制过程中可以指定多种参数的组合,绘制出想要的样式。其中dpi可以指定图形的分辨率,这个参数赋值越大,图像越高清,保存时候占用的内存空间也就越大。
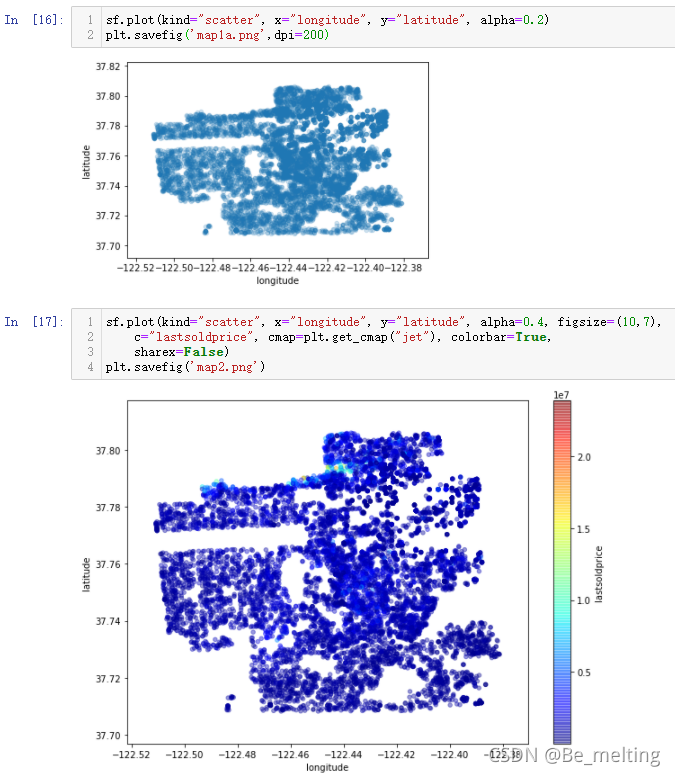
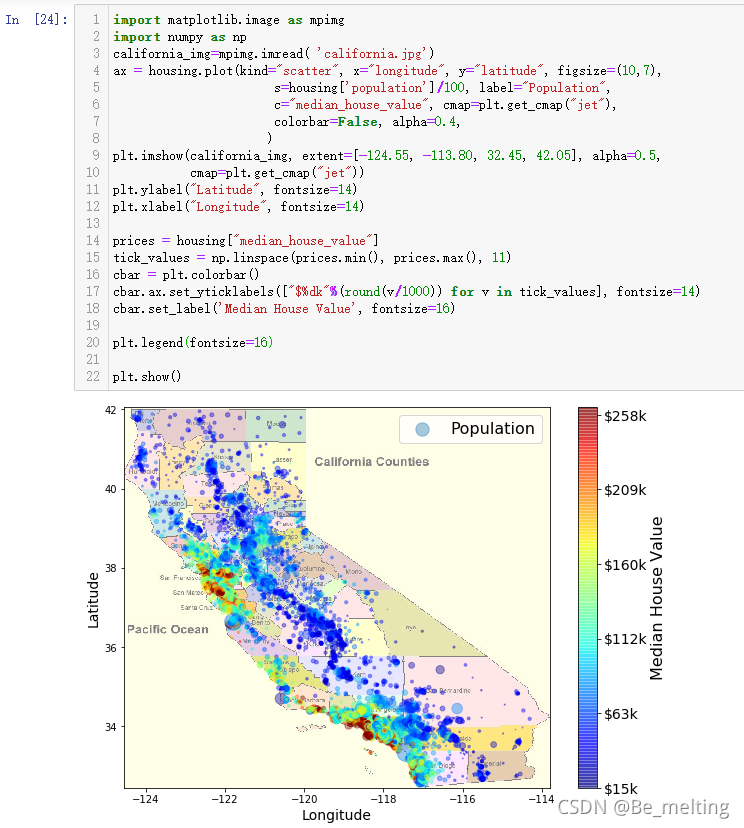
直接绘制的散点图可以展现出来不同经纬度下的房间的价格分布,但是还是缺少一个地理信息,因此最终可视化图形是要把数据(散点)放在地图上。绘制的代码及操作输出如下。此时绘制图形的数据就是直接从网上进行爬取,覆盖了整个加州,出来的图形中,散点的分布明显有一个地图样式。
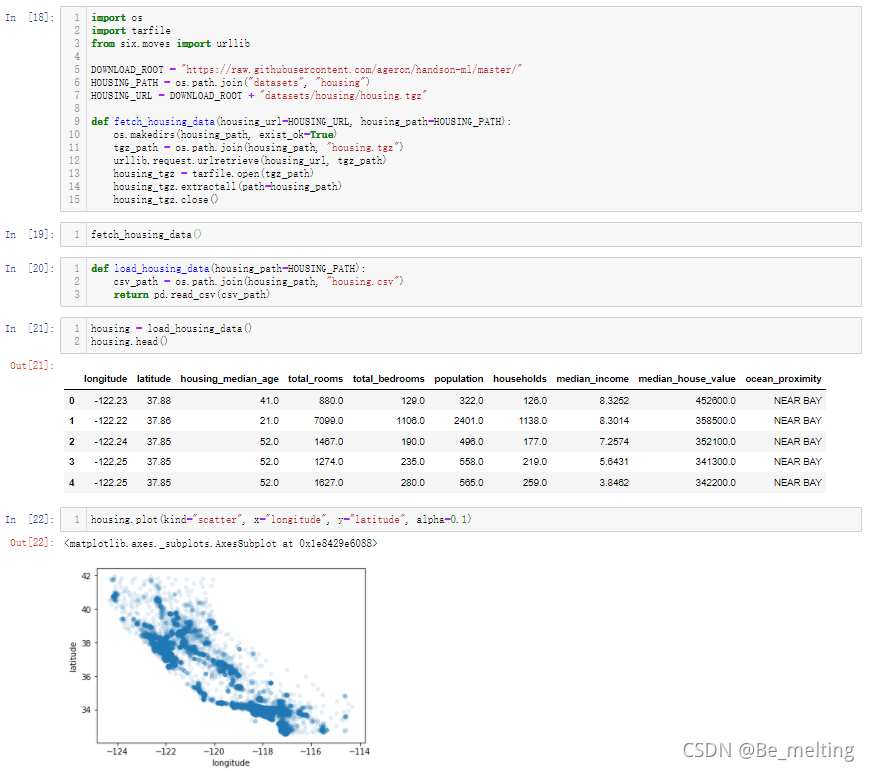
也可以按照之前的步骤,结合不同的参数使得图形更有层次感,包含更多的信息,输出结果如下。
最后一步添加数据的地理信息底图,需要自己在网上进行寻找。执行如下代码后,就可以将最终的散点数据投射上地图,完成地理可视化的操作。
3.2 关系矩阵和热力图
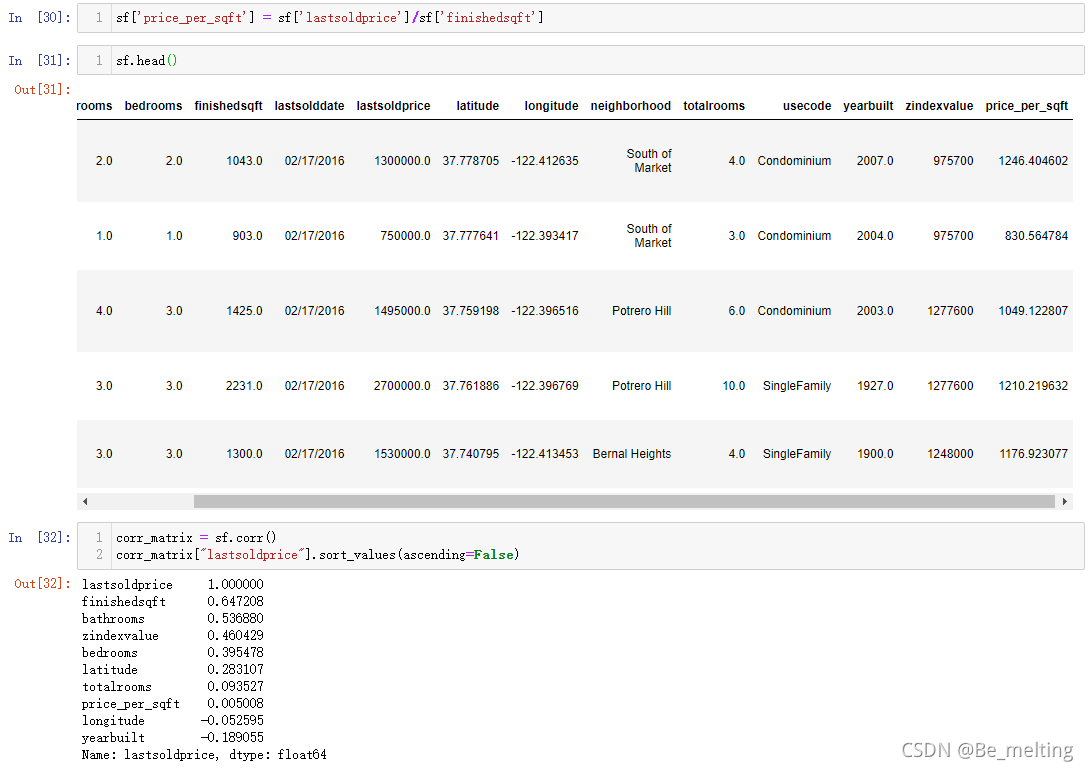
回归到本地的示例数据,可以直接绘制关系矩阵,输出结果如下。对于要研究的因素,可以进行单独选取后排序输出,可以快速的知道哪些因素与要研究的房价有密切的关系。
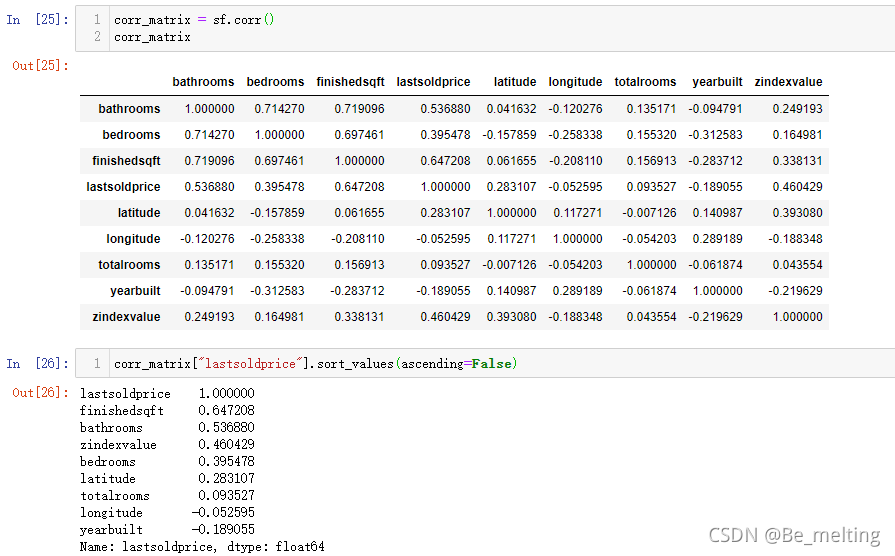
关系矩阵通常配合着热力图一块进行使用,图形的颜色深浅更进一步的展示出各因素与房价之间的关系强弱。

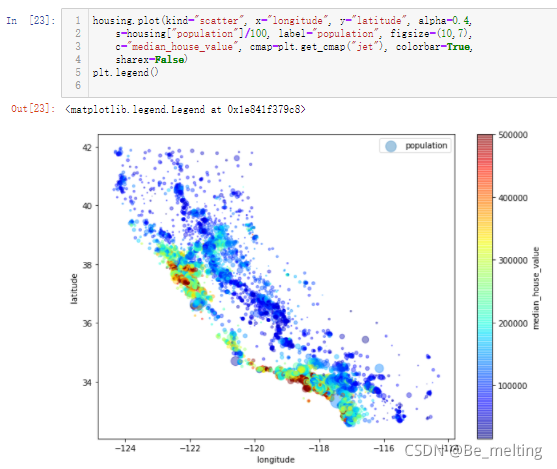
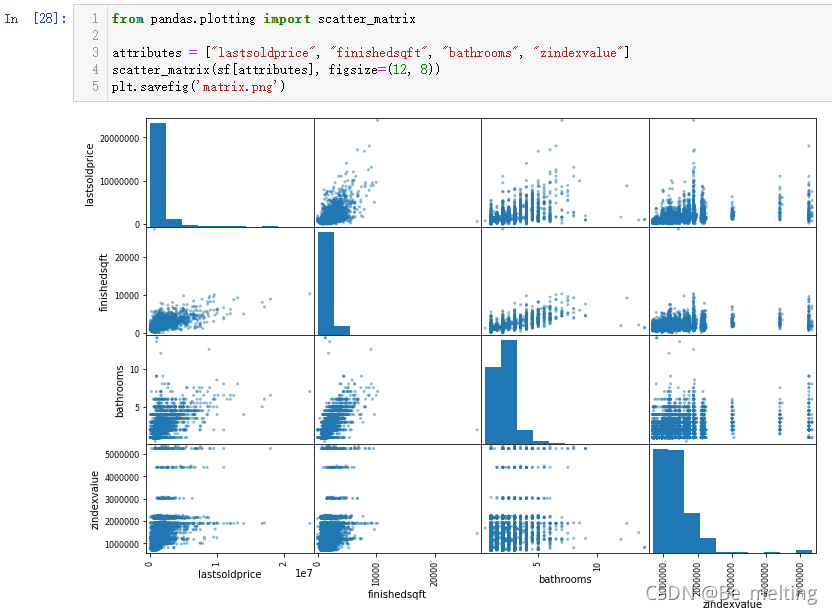
基于关系矩阵和热力图就可以初步判断与房价相关的因素,进一步可以提取这些因素单独与房价进行绘制图形,绘制散点矩阵图形,代码及输出结果如下。
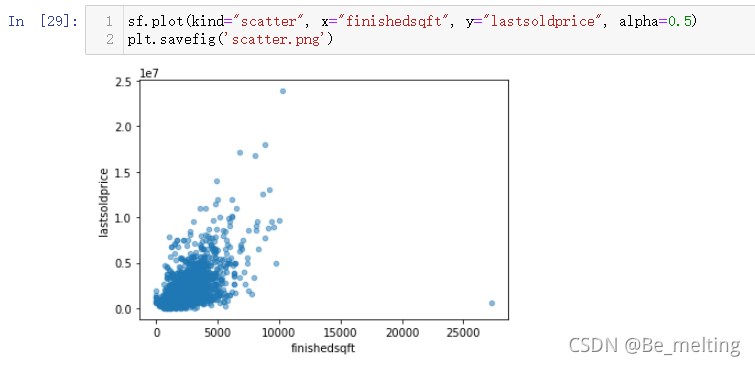
如果对于单个字段绘制与房价的关系图形,可以另外进行绘制,直接选取对应的字段进行绘制就可,比如选取的是房屋的面积字段,代码及输出的结果如下。
3.3 添加衍生字段
前面的两个案例中都没有涉及到衍生字段的知识,这里的衍生字段就是就是利用已有的字段信息,通过不同字段直接操作产生出一个新的字段信息。比如这里通过房屋的总价和房屋的面积字段,计算得到每平米的房屋价钱字段。
需要留意的是往往添加的衍生字段的信息是觉得可能和要预测的房价之间存在着相关关系,根据最终的计算结果判断是否真的存在相关关系,通过上面的输出结果可知,添加的平均价格字段并没有达到想象中的目的,但是这个并不想象重要的相关关系的提取。
3.4 字符串字段的可视化
数据集中包含了一个neighborhood字段信息,表示房屋所在的社区信息,通过统计,就可以知道社区的数量,并对社区和房间进行分组计算就可以知道每个社区对应的房屋价格信息。
比如第一步,了解数据中共有多少个社区,然后计算一个每个社区中具有的房屋数量,代码及输出结果如下。
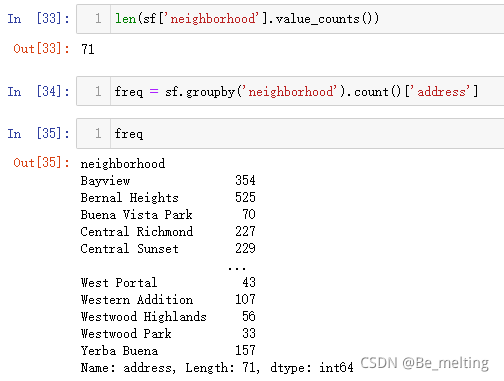
如果想要查看那个社区的房屋数量最多,可以进行一个排序输出。sort_values()默认是对统计的结果进行正序排列输出,可以通过指定ascending参数为False,改为逆序输出。
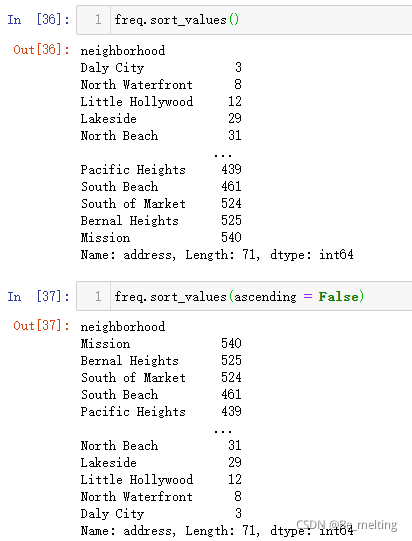
接着就可以探究不同社区房屋的平均价格,并按照价格的高低进行排序输出。最贵的社区房屋是在Lakeside旁边。
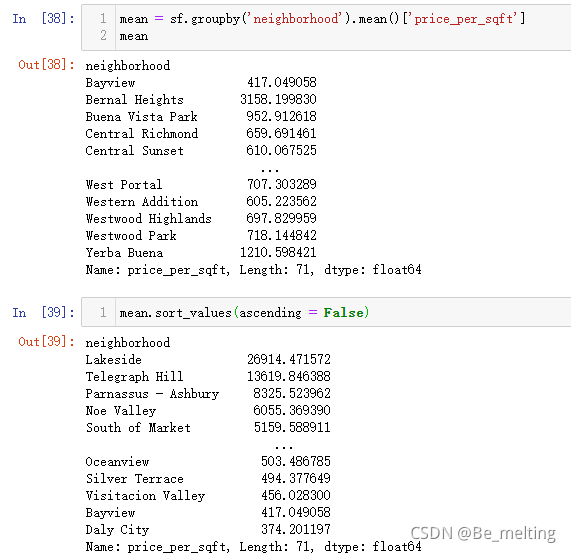
接着直接将输出的结果进行数据可视化,但是需要将上面的结果转化为DataFrame数据类型,然后再进行绘图,代码及输出结果如下。图形中很显然有一个类别的条状图值特别大,然后x轴的标签信息严重重叠,这也说明字符串字段的数据可视化说明的问题(标签踩踏,可以考虑之前词云图的绘制)
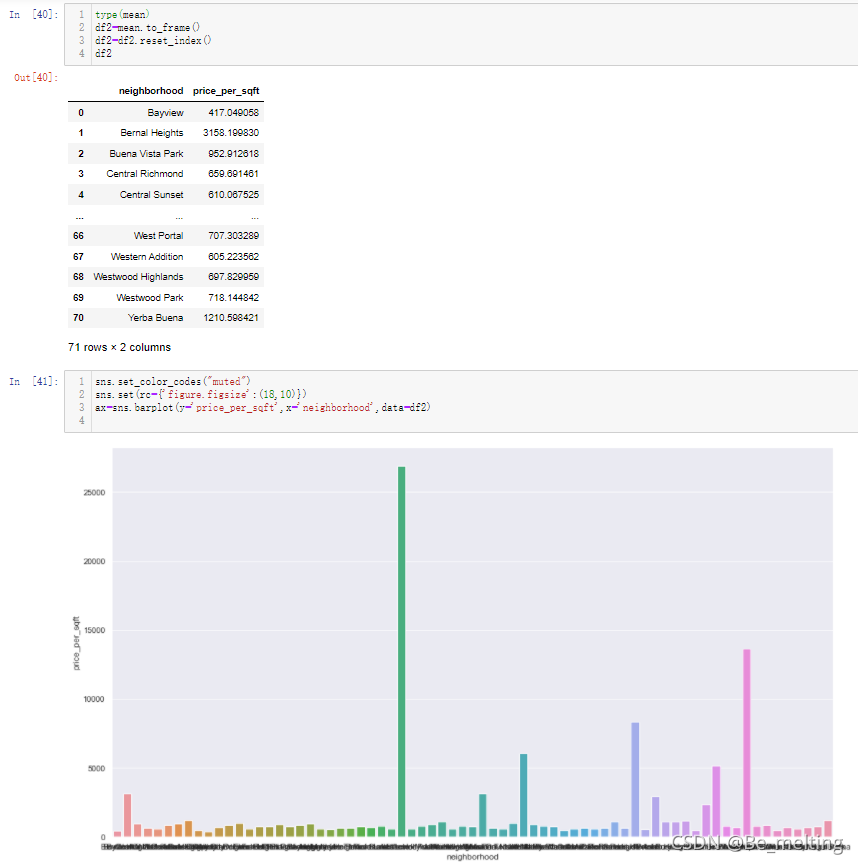
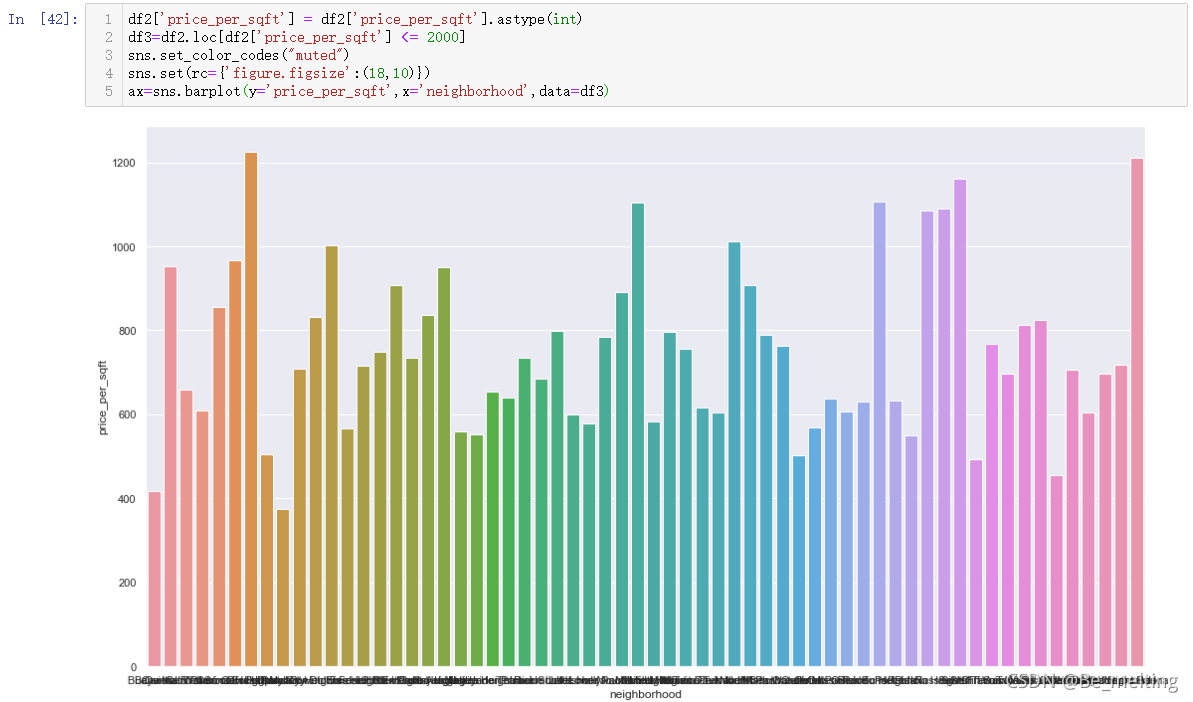
对于异常数据,可以通过指定的范围区间进行筛选去除,然后看一下普通的房屋大概的价格区间,代码及输出结果如下。过滤后的数据输出结果显示,普通房屋的均价是在400-1200美刀之间。
4 机器学习
4.1 特征工程
前面进行了一些基础字段的处理和可视化,接着就是新建三个字段记录社区中的房屋数量和均价以及社区名称
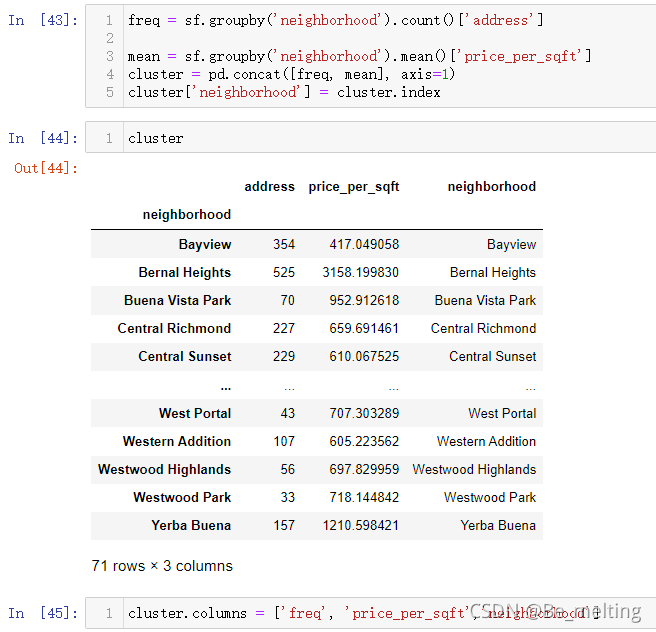
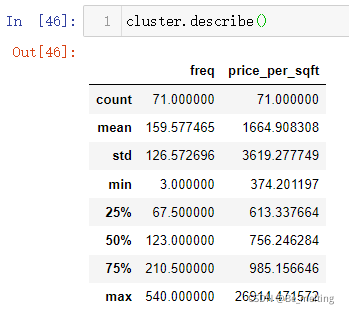
通过describe()可以快速查看社区中的房源的数量和均价的分布情况,输出结果如下。
然后按照这个输出的均值创建筛除后的字段,代码及输出结果如下。

然后利用上述的结果进行不同的社区属性的划分,分别为:低价格房屋、高价格但是低数量房屋、高价格高数量房屋。创建一个函数进行快速处理,代码及操作结果输出如下。
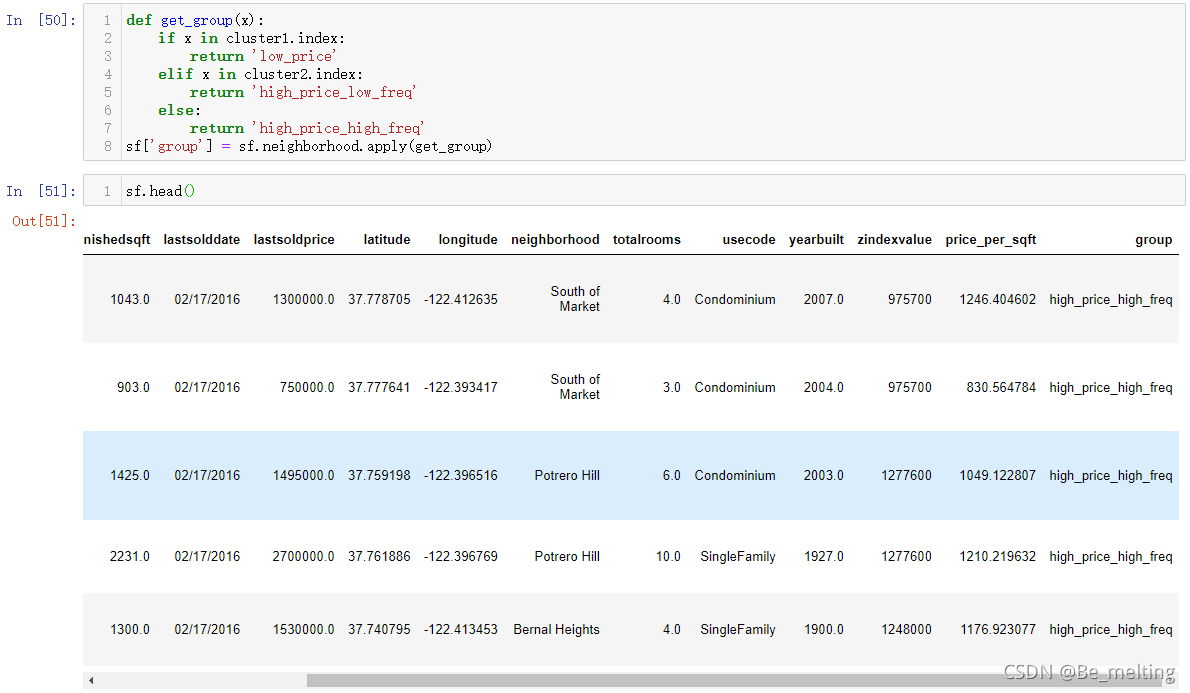
删除无用字段和字段重排序。并不是所有数据都是相关的数据,因此在进行建模之前需要删除部分不需要的字段,然后为了习惯上数据切分,往往是要把要预测的变量放在最后一个字段。代码操作及输出结果如下。
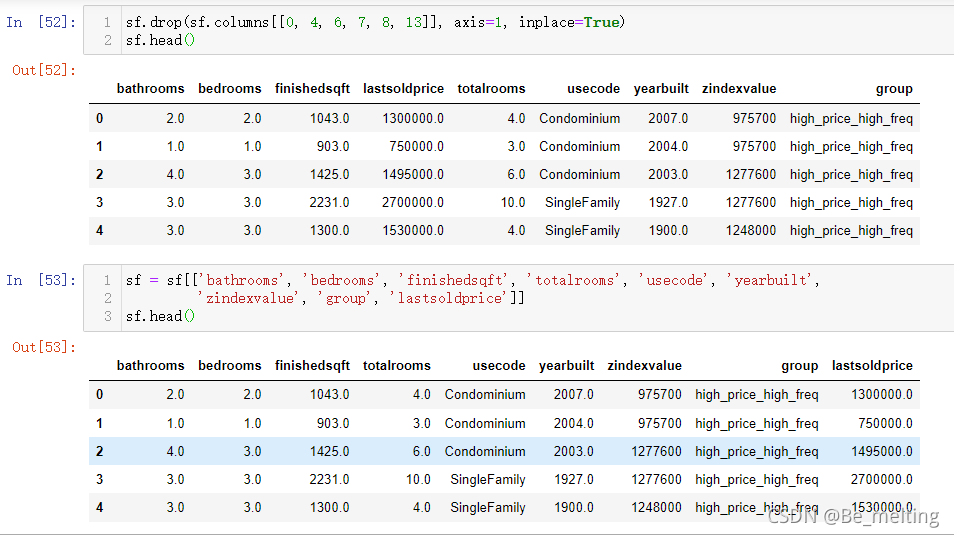
接着就是对于X和Y数据集的划分,需要注意这里的group和usecode都是字符串数据类型,需要先转化为独热编码后再传入模型,比如先处理一下group字段,代码及输出结果如下。
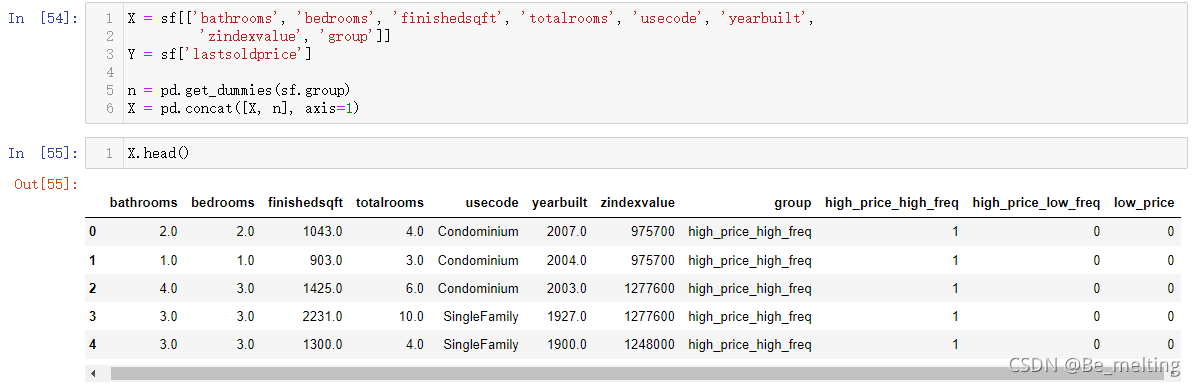
同理再处理usecode字段,最终对于转化前的变量进行删除后得到想要的X数据
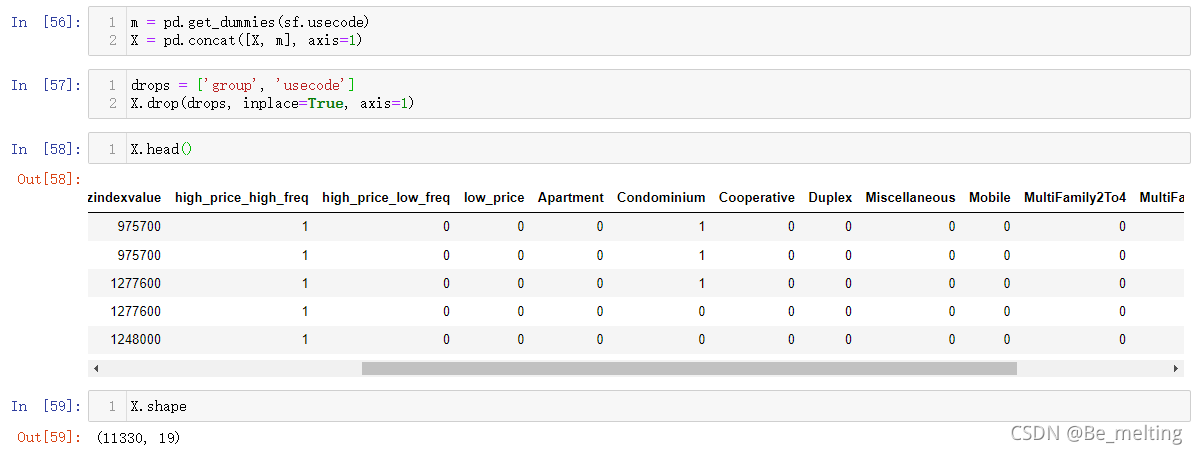
数据标准化。对于数值字段,可以发现不同的字段中具体的数度量范围不一致,可以采用标准化的方法,将其转化为一致。
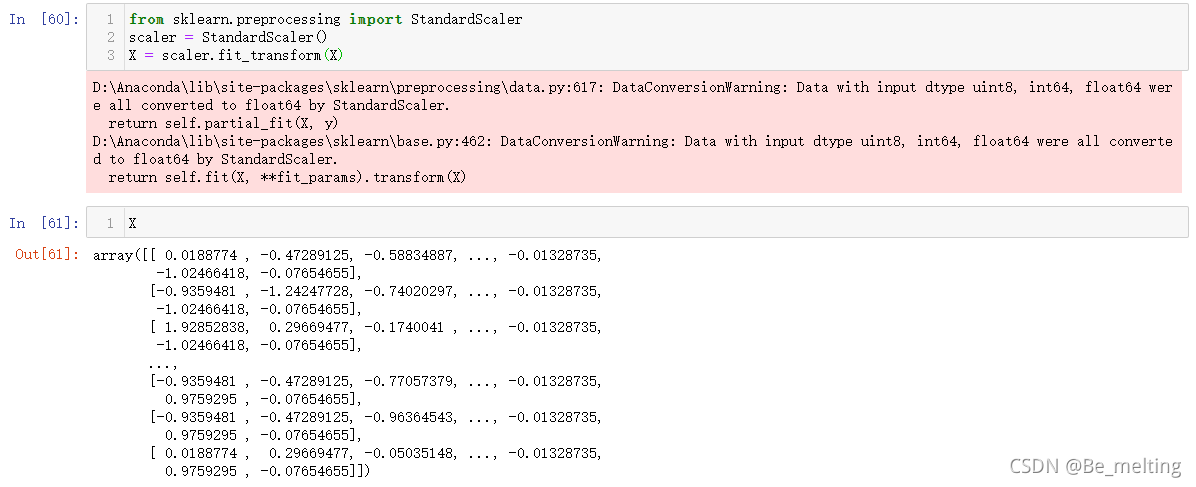
数据集划分。按照7:3比例进行训练集和测试集的划分,代码操作如下。

4.2 模型选择
4.2.1 线性回归模型
数据划分好后,模型的创建就很简单,代码操作如下。

数据预测。直接使用训练好的模型进行预测,首先使用 R 2 R2 R2进行模型拟合情况的判断,输出的结果如下。

在进行回归模型的评估是 R 2 R2 R2是一个非常重要的指标 同时配合常见的MAE RMSE直接进行同步观察,接着可以输出MAE RMSE等评估指标。

单独看上述两个的指标评估结果没有任何意义,需要进行不同模型之间的指标评分结果对比。
4.2.2 随机森林模型
模型的创建与预测。经过几次模型的创建后,使用scikern进行建模基本步骤都是一致的,只是模型的名称不同,有时候会有不同参数的调整,这里创建的随机森林模型只需要保持随机种子一致即可(默认就是指定42,上述的线性回归模型也是)
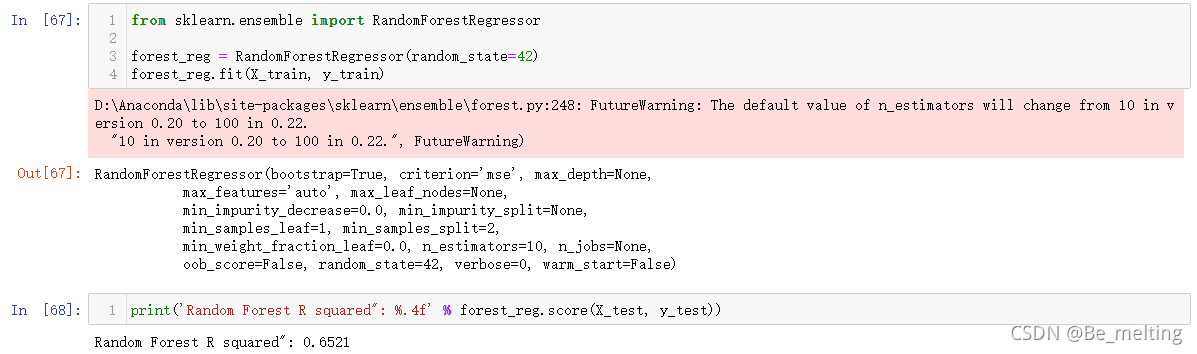
通过对比线性回归模型,可以发现随机森林模型比较好的拟合数据,同时查看MAE RMSE指标得分情况,两指标的输出结果均较小,可以说明随机森林模型适用当前数据较好。

4.2.3 梯度爆炸模型
模型的创建与预测,代码及输出结果如下,模型的拟合结果相较于随机森林模型好一点。

然后结合MAE RMSE指标得分情况,代码及输出结果如下,这里两个指标的得分与随机森林模型训练后的基本一致,但是相对稍微偏大。

最终结合前面三个模型的得分情况,采用梯度爆炸模型进行多因素的识别,代码及操作输出如下。
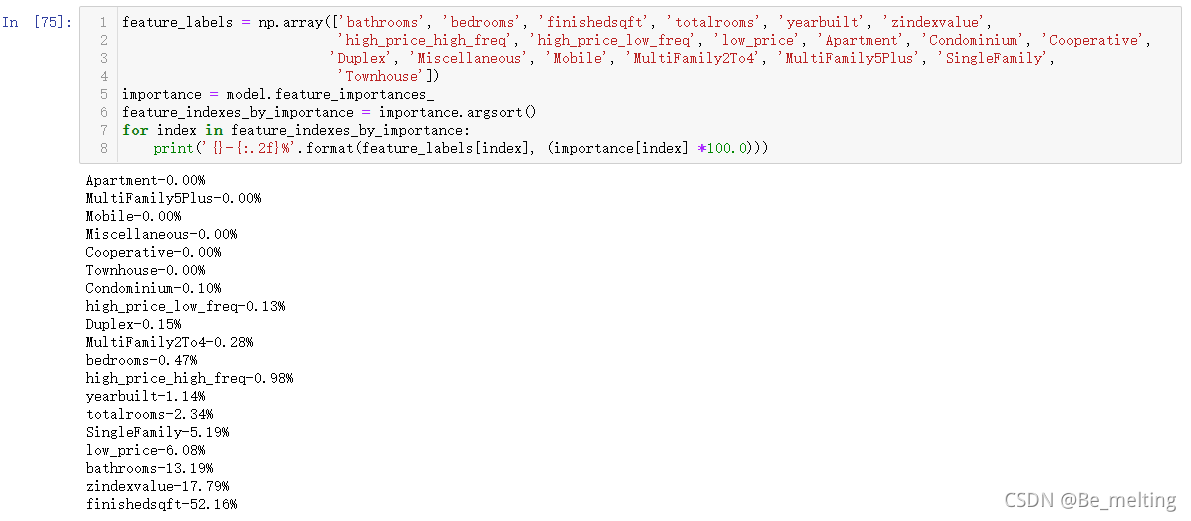
根据结果可以看出房屋面积、网站评估价值、卫生间数量、较低价格的社区、以及单个家庭的字段与房屋的价钱呈现相关性。