泰坦尼克号生还者预测案例
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/120632569(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 数据
1.1 数据下载
本数据集来自于kaggle网站,具体网址:泰坦尼克号生还者预测,数据所在地址:数据集下载界面,对应的界面如下

点击Download All后会跳出弹窗,指定文件的保存路径后就会自动下载文件压缩包,下载完成后解压,文件夹中一共有三个文件,如下
1.2 数据字段介绍
train.csv文件中的字段介绍见如下表格
| 字段名称 | 描述 | 取值 |
|---|---|---|
| PassengerId | 人员编号 | |
| Survived | 人员存活状况 | 0 = 死亡, 1 = 存活 |
| Pclass | 票价等级 | 1 = 一等, 2 = 二等, 3 = 三等 |
| Name | 人员姓名 | |
| Sex | 人员性别 | |
| Age | 人员年龄 | |
| SibSp | 人员兄弟姐妹/配偶 | |
| Parch | 人员父母/孩子 | |
| Ticket | 票号 | |
| Fare | 旅客票价 | |
| Cabin | 救生艇数量 | |
| Embarked | 登船港口 | C = 瑟堡, Q = 皇后镇, S = 南安普敦 |
test.csv文件中不包含人员存活的情况
2 数据加载和基本的ETL
2.1 模块导入和数据加载
在jupyter notebook中的第一个cell中导入后续要使用的模块,分为数据处理、数据绘图、数据建模和数据加载四部分,操作及输出如下

2.2 数据清洗
数据清洗之前需要明确要处理数据的字段类型,浏览上面输出的结果,共有11个字段(PassengerId和Ticket作为编号可以去除,不需考虑),剩余10个字段可以分为四类,如下:
- 数字类特征: 年龄,票价,兄弟姐妹配偶数量,父母小孩数量
- 类别特征: 性别,港口,船舱等级,是否存活
- 包含数字和字符的特征: 船票和船舱
- 文字类特征: 姓名
2.2.1 缺失值处理
获取数据的维度和查询各字段缺失值情况

通过缺失值的查询,发现Age字段缺失大约到了20%,可以采用填充的方式进行处理,而Cabin字段的缺失值高达77%,可以直接删除,最后就是登船港口只有2条数据缺失可以直接删除也可以进行填充。接下来逐步进行缺失值处理
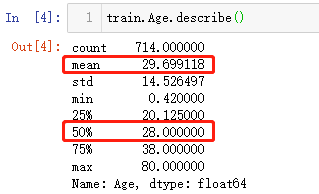
首先是对于年龄字段,填充的具体方式可以查看数据的分布,一般对于年龄的分布都是属于右偏分布(就是均值大于中位数),可以通过describe()方法查询,输出结果如下:(可以发现均值比50%处的中位数大一点,稍稍右偏,可以采用中位数填充,也可以考虑使用均值填充)
假定使用中位数进行填充,操作代码及输出结果如下:(注意使用的sklearn的版本,如果是最新的版本第一行的导入方式就可以按照下面红色提醒的方式进行替换,操作成功后可以删除原来的缺失字段,并查看缺失值)

接着就是对于一些不需要考虑和缺失值较多的字段进行删除,操作及输出结果如下:

最后就是对于Enbarked字段的缺失值进行删除操作后,整个缺失值的清洗工作就完成了,输出结果如下:

2.2.2 分类数据独热编码和数值数据分箱
对于类别数据进行独热编码操作,输出结果如下:(可以使用乘客的ID作为索引)

对于数值数据可以采用分箱的操作,方便机器学习模型的训练,而且也有利于统计分析,具体可以按照一定的范围进行划分(这个范围可以参考前人的研究工作,也可以自己根据实际的业务场景进行自定义划分)
首先对于票价的字段,分箱操作及输出结果如下:(低于7.91标记为0,在7.91-14.454之间标记为1,1.454-31之间标记为2,31以上标记为3)

对于年龄字段进行分箱,操作及输出结果如下:(低于16标记为0,16-32之间标记为1,32-48之间标记为2,48-64之间标记为3,64以上标记为4)

3 数据探索式分析
3.1 生存概率
直接对于Survived字段进行计数统计,然后除于总人数即可求出生存概率,操作及输出结果如下:
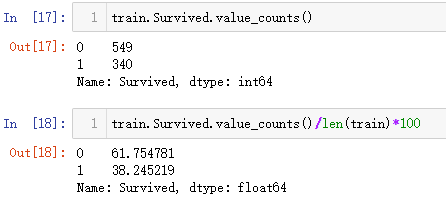
除了这种方式之外,还可以直接使用describe()进行,由于Survived字段只有0和1,所以均值的结果就代表着生存概率,这也是很多场景为啥要把二分类变量归为0和1的原因,输出如下

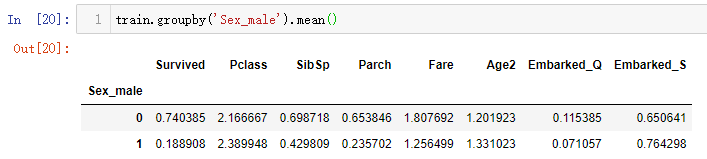
3.2 性别与存活率之间的关系
直接按照Sex_male字段进行分组求均值,就可以得到男性和女性之间存活率,输出结果如下:(总的生存率是38%,其中女性的存活率是74%,男性的存活率是19%。需要注意的是最后面的两个值的总和并不是100%,因为生存率+死亡率是100%,而男性+女性是100%,而男性生存率+女性生存率总和不一定是100%)
3.3 字段之间的关联分析
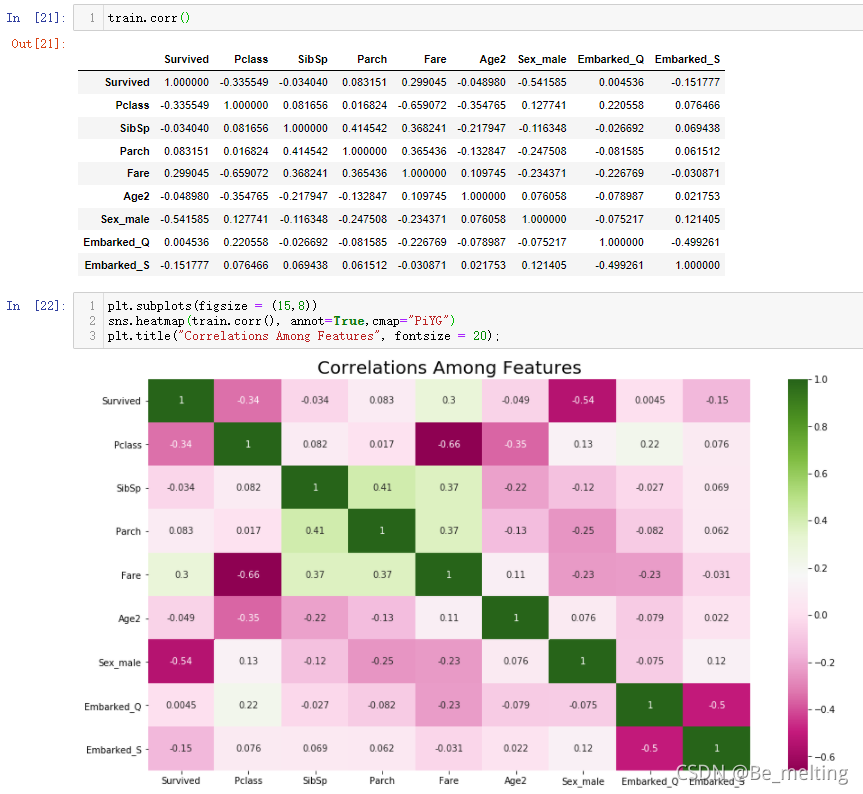
关联矩阵corr()和热力图heatmap()的展示,这种方式最为直观地进行字段之间相关性的探究,操作及输出结果如下:(只需要看一部分即可,图像是关于对角线对称,比如只看右上方的图像。其中正相关的部分最明显的是船票价格和生存率达到0.3;负相关部分,性别和生存率之间是 -0.54、 船票价格和船舱等级是 -0.66、船舱等级和生存率之间是 -0.34)
3.4 性别与生存率之间的关系
常见的图形就是分组条形图barplot(),对比不同组别的数值大小,来直观反映不同组别的差异情况,操作及输出结果如下:

更进一步可以进行细化,比如在条状图中分为存活率和死亡率,操作及输出结果如下:(countplot()结合hue分类参数,关于图例的单独设置也可以参照下面的方式)

3.5 船舱与生存率之间的关系
有了前面的代码基础,这里修改一下传入的字段名称后输出结果如下:(可以看出死亡最多的就是三等舱人员,而一等舱的死亡率最低,但是存活率最高)

除了条状图外,还可以使用其它样式的图形进行展示,比如使用阴影图kdeplot(),操作及输出如下:

3.6 票价和生存率之间的关系
绘制的代码与上图基本一致,传入的字段改变一下即可,输出如下:(红色代表着死亡,蓝色代表着存活,可以发现,票价约低死亡率越高,票价越高,存活率就越高)

3.7 年龄和生存率之间的关系
根据图形输出结果,可以发现死亡人员主要集中在16-32岁之间,而且在此年龄区间中,人员的死亡率要大于存活率,65岁以上的人员也是死亡率大于存活率,但是在16岁一下的人员存活率明显高绿死亡率,剩下两个年龄段的对比不明显

4 机器学习模型
由于数据比较简单,前面已经进行了数据的处理工作,下面直接就可以进行模型搭建,导入sklearn中常见的分类模型(如果显示模块不存在可以直接在Anaconda命令行进行安装)
构建分类器,放置各类模型

创建评分依据,这里使用准确度进行评分(首先创建一个空的DataFrame,里面就包含分类器个准确度评分,接着导入评分模块和数据切分模块,然后创建一个空字典用来存放每一个分类器的结果,最后就是依次训练模型进行预测)

运行结束后创建的acc_dict字典中就包含了分类器的名称和对应的评分,然后就可以利用创建的空的DataFrame将数据放置对应的字段中,方便图形的绘制,操作及结果输出如下:

图像输出上进行对比,发现有四个分类器的结果几乎一致,因此可以直接输出log这个DataFrame数据,可以直接看出哪个分类器比较适用于当前数据,输出结果如下:

明显XGBClassifier分类器表现最好,接下来就以此模型进行训练预测,操作如下:

最后的就是处理test数据,对于train数据怎么处理的流程,同样用在test数据中,数值数据先进行缺失值填充

核实处理后的结果(没有缺失值了)

然后就是分类数据独热编码和数值数据的分箱操作,步骤如下:(和之前处理的train数据步骤一致)

然后就是对字段顺序进行调整,操作如下:

最后就是用最好的模型进行预测了,输出结果如下:(项目整理完毕)
