1. 问题
【问题一】 如何删除缺失值占比超过25%的列?
# 构建一个DataFrame
df = pd.DataFrame({
'a':[1, 2, 3, 4], 'b':[5, 6, np.nan, 8], 'c':[9, np.nan, np.nan, 10], 'd':[11, np.nan, np.nan, np.nan]})
# 其中df为输入的DataFrame, n为百分比
def drop_nan(df, n):
list_drop = []
df_list = list(df.columns)
for i in df_list:
if ((df[i].isna().sum())/df.shape[0] >= n):
list_drop.append(i)
return list_drop
a = drop_nan(df, 0.25)
a
结果为
['b', 'c', 'd']
删掉b, c, d列就好了
【问题二】 什么是Nullable类型?请谈谈为什么要引入这个设计?
Nullable类型就是pandas里面的一种新的数据类型,可用于处理缺失类型,具有鲁棒性。
目的就是为了(在若干版本后)解决之前出现的null混乱局面,统一缺失值处理方法¶
【问题三】 对于一份有缺失值的数据,可以采取哪些策略或方法深化对它的了解?
info()这个是最直接的,我本人也是拿到数据先用这个看一看
isna()可以对于单列来说来看它是否是缺失值
2. 练习
【练习一】现有一份虚拟数据集,列类型分别为string/浮点/整型,请解决如下问题:
(a)请以列类型读入数据,并选出C为缺失值的行。
df = pd.read_csv('../data/Missing_data_one.csv').convert_dtypes()
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 30 entries, 0 to 29
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 30 non-null string
1 B 30 non-null float64
2 C 25 non-null Int64
dtypes: Int64(1), float64(1), string(1)
memory usage: 878.0 bytes
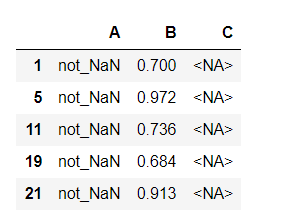
df[df['C'].isna()]
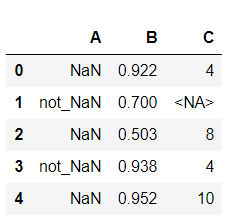
(b)现需要将A中的部分单元转为缺失值,单元格中的最小转换概率为25%,且概率大小与所在行B列单元的值成正比。
# np.random.rand() 返回一个0-1分布
# 要求最小的概率达到25%
df_min = df['B'].min()
df['A'] = pd.Series(list(zip(df['A'].values, df['B'].values))).apply(lambda x: x[0] if np.random.rand() >= (x[1] * 0.25 / df_min) else np.nan)
df.head()
【练习二】 现有一份缺失的数据集,记录了36个人来自的地区、身高、体重、年龄和工资,请解决如下问题:
(a)统计各列缺失的比例并选出在后三列中至少有两个非缺失值的行。
def nan_proportion(df):
dict_pro = {
}
list_name = list(df.columns)
for name in list_name:
dict_pro[name] = df[name].isna().sum() / df.shape[0]
return dict_pro
dict_pro = nan_proportion(df_2)
dict_pro
{
'编号': 0.0,
'地区': 0.0,
'身高': 0.0,
'体重': 0.2222222222222222,
'年龄': 0.25,
'工资': 0.2222222222222222}
df_2.loc[df_2.iloc[:, -3:].isna().sum(1)<=1]

(b)请结合身高列和地区列中的数据,对体重进行合理插值。
# 按地区分组,然后再按身高排序进行线性插值
for _, group in df_2.groupby('地区'):
df_2.loc[group.index, '体重'] = group[['身高', '体重']].sort_values(by='身高')['体重'].interpolate()
df_2['体重'] = df_2['体重'].round(decimals=2)
df_2
