有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状 态,然后在新流入数据的基础上不断更新状态。
SparkStreaming 在状态管理这块做的不好, 很多时候需要借助于外部存储(例如 Redis)
来手动管理状态, 增加了编程的难度。
Flink 的状态管理是它的优势之一。
(1)什么状态
在流式计算中有些操作一次处理一个独立的事件(比如解析一个事件), 有些操作却需 要记住多个事件的信息(比如窗口操作)。
那些需要记住多个事件信息的操作就是 有状态 的。
流式计算分为 无状态计算和有状态计算两种情况
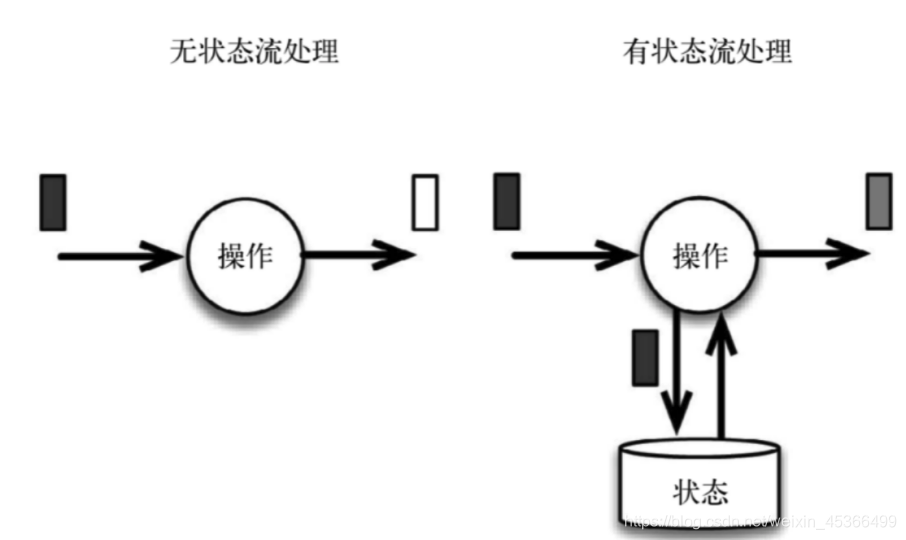
- 无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应 用程序从传感器接收水位数据,并在水位超过指定高度时发出警告。
- 有状态的计算则会基于多个事件输出结果。以下是一些例子。例如,计算过去一小
时的平均水位,就是有状态的计算。所有用于复杂事件处理的状态机。例如,若在 一分钟内收到两个相差 20cm以上的水位差读数,则发出警告,这是有状态的计算。 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状 态的计算。
传统的流处理架构:

有状态的流处理架构:

(2)为什么需要状态管理
下面的几个场景都需要使用流处理的状态功能:
去重: 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应 用,当新数据流入时,根据已流入过的数据来判断去重。
检测: 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下 来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
聚合: 对一个时间窗口内的数据进行聚合分析,分析一个小时内水位的情况。
更新机器学习模型: 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
(3)Flink中状态的分类
Flink 包括两种基本类型的状态 Managed State 和 Raw State
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime 托管, 自动存储, 自动恢复, 自 动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink 提供多种常用数据结构, 例如:ListState, MapState 等 | 字节数组: byte[] |
| 使用场景 | 绝大数 Flink 算子 | 所有算子 |
注意:
-
从具体使用场景来说,绝大多数的算子都可以通过继承 Rich 函数类或其他 提供好的接口类,在里面使用 Managed State。Raw State 一般是在已有算子和 Managed State 不够用时,用户自定义算子时使用。
-
在我们平时的使用中 Managed State 已经足够我们使用, 下面重点学习 Managed State
(4)Managed State 的分类
对 Managed State 继续细分,它又有两种类型
-
Keyed State(键控状态)
-
Operator State(算子状态)
| Operator State | Keyed State | |
|---|---|---|
| 适用用算子类型 | 可用于所有算子: 常 用于 source, 例如 FlinkKafkaConsumer | 只适用于 KeyedStream 上 的算子 |
| 状态分配 | 一个算子的子任务对 应一个状态 | 一个 Key 对应一个 State: 一个算子会处理多个 Key, 则 访问相应的多个 State |
| 创建和访问方式 | 实现 CheckpointedFunction 或 ListCheckpointed(已经过时) 接口 | 重写 RichFunction, 通过里面的RuntimeContext 访问 |
| 横向扩展 | 并发改变时有多重重写分配方 式可选: 均匀分配和合并后每个得到全量 | 并发改变, State 随着 Key 在实例 间迁移 |
| 支持的数据结构 | ListState 和 BroadCastState | ValueState, ListState,MapState ReduceState, AggregatingState |

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!