写在前面:我是「云祁」,一枚热爱技术、会写诗的大数据开发猿。昵称来源于王安石诗中一句
[ 云之祁祁,或雨于渊 ],甚是喜欢。
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对数据中台、数据建模、数据分析以及Flink/Spark/Hadoop/数仓开发感兴趣,可以关注我的动态 https://blog.csdn.net/BeiisBei ,让我们一起挖掘数据的价值~
每天都要进步一点点,生命不是要超越别人,而是要超越自己! (ง •_•)ง
文章目录
一、前言
流式计算分为无状态和有状态两种情况。无状态的计算观察每个独立事件,并根据最后一个事件输出结果。例如,流处理应用程序从传感器接收温度读数,并在温度超过 90 度时发出警告。有状态的计算则会基于多个事件输出结果。以下是一些例子。
- 所有类型的窗口。例如,计算过去一小时的平均温度,就是有状态的计算。
- 所有用于复杂事件处理的状态机。例如,若在一分钟内收到两个相差 20 度以上的温度读数,则发出警告,这是有状态的计算。
- 流与流之间的所有关联操作,以及流与静态表或动态表之间的关联操作,都是有状态的计算。
下图展示了无状态流处理和有状态流处理的主要区别。无状态流处理分别接收每条数据记录(图中的黑条),然后根据最新输入的数据生成输出数据(白条)。有状态流处理会维护状态(根据每条输入记录进行更新),并基于最新输入的记录和当前的状态值生成输出记录(灰条)。

上图中输入数据由黑条表示。无状态流处理每次只转换一条输入记录,并且仅根据最新的输入记录输出结果(白条)。有状态流处理维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录(灰条)反映的是综合考虑多个事件之后的结果。
尽管无状态的计算很重要,但是流处理对有状态的计算更感兴趣。事实上,正确地实现有状态的计算比实现无状态的计算难得多。旧的流处理系统并不支持有状态的计算,而新一代的流处理系统则将状态及其正确性视为重中之重。
二、有状态的算子和应用程序
Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据。例如: ProcessWindowFunction会缓存输入流的数据,ProcessFunction 会保存设置的定时器信息等等。

在 Flink 中,状态始终与特定算子相关联,为了使运行时的Flink了解算子的状态,算子需要预先注册其状态。总的来说,有两种类型的状态:
- 算子状态(operator state)
- 键控状态(keyed state)
2.1 算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。算子状态不能由相同或不同算子的另一个任务访问。
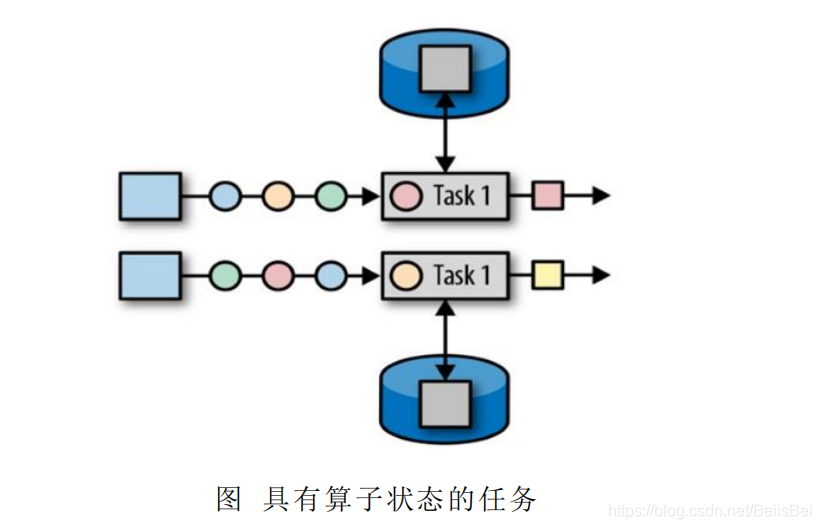
Flink 为算子状态提供三种基本数据结构:
- 列表状态(List state)
将状态表示为一组数据的列表。 - 联合列表状态(Union list state)
也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。 - 广播状态(Broadcast state)
如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
2.2 键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。因此,具有相同 key 的所有数据都会访问相同的状态。Keyed State 很类似于一个分布式的 key-value map 数据结构,只能用于KeyedStream(keyBy 算子处理之后)。


Flink 的 Keyed State 支持以下数据类型:
-
值状态 ValueState[T] 保存单个的值,值的类型为 T。
- get 操作: ValueState.value()
- set 操作: ValueState.update(value: T)
-
列表状态 ListState[T] 保存一个列表,列表里的元素的数据类型为 T。
- ListState.add(value: T)
- ListState.addAll(values: java.util.List[T])
- ListState.get()返回 Iterable[T]
- ListState.update(values: java.util.List[T])
-
映射状态 MapState[K, V] 保存 Key-Value 对。
- MapState.get(key: K)
- MapState.put(key: K, value: V)
- MapState.contains(key: K)
- MapState.remove(key: K)
-
聚合状态 讲状态表示为一个用于聚合操作的列表。
- ReducingState[T]
- AggregatingState[I, O]
State.clear()是清空操作。
2.3 键控状态的使用

2.4 状态后端(State Backends)
- 每传入一条数据,有状态的算子任务都会读取和更新状态
- 由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问。
- 状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
- 状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
2.5 选择一个状态后端
-
MemoryStateBackend
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中
- 特点:快速、低延迟,但是不稳定 。所以实际生产中不会使用。
-
FsStateBackend
- 将 checkpoint 存储到远程的持久化文件系统 (FileSystem)上,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上
- 同时拥有内存级的本地访问速度,和更好的容错保证
-
RocksDBStateBackend
- 将所有状态序列化后,存入本地的 RocksDB 中存储。
注意:RocksDB 的支持并不直接包含在 flink 中,需要引入依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.2</version>
</dependency>
设置状态后端为 FsStateBackend:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val checkpointPath: String = ???
val backend = new RocksDBStateBackend(checkpointPath)
env.setStateBackend(backend)
env.setStateBackend(new FsStateBackend("file:///tmp/checkpoints"))
env.enableCheckpointing(1000)
// 配置重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60, Time.of(10,
TimeUnit.SECONDS)))
三、状态编程
val sensorData: DataStream[SensorReading] = ...
val keyedData: KeyedStream[SensorReading, String] = sensorData.keyBy(_.id)
val alerts: DataStream[(String, Double, Double)] = keyedData
.flatMap(new TemperatureAlertFunction(1.7))
class TemperatureAlertFunction(val threshold: Double) extends
RichFlatMapFunction[SensorReading, (String, Double, Double)] {
private var lastTempState: ValueState[Double] = _
override def open(parameters: Configuration): Unit = {
val lastTempDescriptor = new ValueStateDescriptor[Double]("lastTemp",classOf[Double])
lastTempState = getRuntimeContext.getState[Double](lastTempDescriptor)
}
override def flatMap(reading: SensorReading,out: Collector[(String, Double, Double)]): Unit = {
val lastTemp = lastTempState.value()
val tempDiff = (reading.temperature - lastTemp).abs
if (tempDiff > threshold) {
out.collect((reading.id, reading.temperature, tempDiff))
}
this.lastTempState.update(reading.temperature)
}
}
通过 RuntimeContext 注册 StateDescriptor。StateDescriptor 以状态 state 的名字和存储的数据类型为参数。
在 open()方法中创建 state 变量。注意复习之前的 RichFunction 相关知识。
接下来我们使用了 FlatMap with keyed ValueState 的快捷方式 flatMapWithState
实现以上需求。
val alerts: DataStream[(String, Double, Double)] = keyedSensorData
.flatMapWithState[(String, Double, Double), Double] {
// 如果没有状态的话,也就是没有数据来过,那么就将当前的数据温度存入状态
case (in: SensorReading, None) => (List.empty, Some(in.temperature))
// 如果有状态,就应该与上次的温度值比较差值,如果大于阈值就输出报警
case (r: SensorReading, lastTemp: Some[Double]) =>
val tempDiff = (r.temperature - lastTemp.get).abs
if (tempDiff > 1.7) {
(List((r.id, r.temperature, tempDiff)),Some(r.temperature))
} else {
(List.empty, Some(r.temperature))
}
}