Flink 状态计算
一、概述
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/state.html
Flink是⼀个基于状态计算的流计算服务。Flink将所有的状态分为两⼤类: keyed state与 operatorstate.所谓的keyed state指的是Flink底层会给每⼀个Key绑定若⼲个类型的状态值,特指操作KeyedStream中所涉及的状态。所谓operator state指的是⾮keyed stream中所涉及状态称为operatorstate,所有的operator state会将状态和具体某个操作符进⾏绑定。⽆论是 keyed state 还是 operator state flink将这些状态管理底层分为两种存储形式:Managed State和Raw State。
- Managed State- 所谓的Managed State,指的是
由Flink控制状态存储结构,例如:状态数据结构、数据类型等,由于是Flink⾃⼰管理状态,因此Flink可以更好的针对于管理状态做内存的优化和故障恢复。 - Raw State - 所谓的Raw state,指的是
Flink对状态的信息和结构⼀⽆所知,Flink仅仅知道该状态是⼀些⼆进制字节数组,需要⽤户⾃⼰完成状态序列化和反序列化。,因此Raw State Flink不能够针对性的做内存优化,也不⽀持故障状态的恢复。因此在Flink实战项⽬开发中,⼏乎不使⽤Raw State.
二、Managed Keyed State
| 类型 | 使用场景 | 方法 |
|---|---|---|
| ValueState | 该状态主要⽤于存储单⼀状态值。 | T value() update(T) clear() |
| ListState | 该状态主要⽤于存储单集合状态值。 | add(T) addAll(List) update(List) Iterableget() clear() |
| MapState<uk,uv> | 该状态主要⽤于存储⼀个Map集合 | put(UK, UV) putAll(Map) get(UK) entries() keys() values() clear() |
| ReducingState | 该状态主要⽤于存储单⼀状态值。该状态会将添加的元素和历史状态⾃动做运算,调⽤⽤户提供的ReduceFunction | add(T) T get() clear() |
| AggregatingState<in,out> | 该状态主要⽤于存储单⼀状态值。该状态会将添加的元素和历史状态⾃动做运算,调⽤⽤户提供的AggregateFunction,该状态和ReducingState不同点在于数据输⼊和输出类型可以不⼀致 | add(IN) OUT get() clear() |
| FoldingState<T,ACC> | 该状态主要⽤于存储单⼀状态值。该状态会将添加的元素和历史状态⾃动做运算,调⽤⽤户提供的FoldFunction,该状态和ReducingState不同点在于数据输⼊和中间结果类型可以不⼀致 | add(T) T get() clear() |
①.ValueState
package com.baizhi.state
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object ValueState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流
in.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
.map(new ValueMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class ValueMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var vs:ValueState[Int] = _
override def open(parameters: Configuration): Unit = {
//创建一个状态描述符
val valueStateDescriptor = new ValueStateDescriptor[Int]("valueWordCount",createTypeInformation[Int])
//获取运行时全文
val context = getRuntimeContext
//从全文中获取状态
vs = context.getState(valueStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//获取最新状态
vs.update(in._2+vs.value())
(in._1,vs.value())
}
}
②.ListState
package com.baizhi.state
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object ListState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.map(_.split("\\s+"))
.map(t=>(t(0)+":"+t(1),t(2)))
.keyBy(0)
.map(new ListMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class ListMapFunction extends RichMapFunction[(String,String),(String,String)]{
//创建一个状态对象
var vs:ListState[String] = _
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val listDescriptor = new ListStateDescriptor[String]("ListWoedCount",createTypeInformation[String])
//获取运行时上下文
val context = getRuntimeContext
//获取状态变量
vs = context.getListState(listDescriptor)
}
override def map(in: (String, String)): (String, String) = {
//获取原始状态
val list = vs.get().asScala.toList
//改变状态
val distinct = list.::(in._2).distinct
val javaList = distinct.asJava
vs.update(javaList)
//返回
(in._1,distinct.mkString("|"))
}
}
③.MapState
package com.baizhi.state
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object MapState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.map(_.split("\\s+"))
.map(t=>(t(0)+":"+t(1),t(2)))
.keyBy(0)
.map(new MapMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class MapMapFunction extends RichMapFunction[(String,String),(String,String)]{
//创建一个状态对象
var state:MapState[String,Int]=_
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val mapSteatDescriptor = new MapStateDescriptor[String,Int]("MapWordCount",createTypeInformation[(String)],createTypeInformation[Int])
//获取运行时全文
val context = getRuntimeContext
//从全文获取状态对象
state = context.getMapState(mapSteatDescriptor)
}
override def map(in: (String, String)): (String, String) = {
var count = 0 //设定value为0
//判断状态变量中是否存有现在的key
if(state.contains(in._2)){
//如果包含,获取原始值
count = state.get(in._2)
}
//状态更新
state.put(in._2,count+1)
//获取当前值(这是一个key-value的集合)
val list = state.entries().asScala.map(entry=>(entry.getKey,entry.getValue)).toList
//返回
(in._1,list.mkString("|"))
}
}
④.ReducingState
package com.baizhi.state
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.StateTtlConfig.{StateVisibility, UpdateType}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, StateTtlConfig, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.time.Time
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object ReduceState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.flatMap(_.split("\\s+"))
.map(t=>(t,1))
.keyBy(0)
.map(new ReduceMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class ReduceMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var state:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val reducingStateDescriptor = new ReducingStateDescriptor[Int]("reducingWordCount", new ReduceFunction[Int] {
override def reduce(t: Int, t1: Int): Int = {
t + t1
}
}, createTypeInformation[Int])
//创建一个状态的过期配置
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置过期时间 ,配置5秒的过期时间
.setUpdateType(UpdateType.OnCreateAndWrite) //设置更新类型 创建和修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //设置过期数据的可视化策略,从不返回过期数据
.build()
//开启失效配置
reducingStateDescriptor.enableTimeToLive(stateTtlConfig)
//获取全文对象
val context = getRuntimeContext
//从全文中获取状态
state = context.getReducingState(reducingStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//更新状态
state.add(in._2)
//返回
(in._1,state.get())
}
}
⑤.AggregatingState
package com.baizhi.state
import org.apache.flink.api.common.functions.{AggregateFunction, ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor, ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object AggregateState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.map(_.split("\\s+"))
.map(t=>(t(0)+":"+t(1),t(2).toDouble))
.keyBy(0)
.map(new AggregateMapFuntion)
.print()
//4.执行
env.execute("word count")
}
}
class AggregateMapFuntion extends RichMapFunction[(String,Double),(String,Double)]{
//创建一个状态对象
var state:AggregatingState[Double,Double]=_
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val aggregatingStateDescriptor = new AggregatingStateDescriptor[Double, (Int, Double), Double]("aggregateWordCount", new AggregateFunction[Double, (Int, Double), Double] {
override def createAccumulator(): (Int, Double) = {
//创建累加器
(0, 0.0)
}
override def add(in: Double, acc: (Int, Double)): (Int, Double) = {
//添加
(acc._1 + 1, acc._2 + in)
}
override def getResult(acc: (Int, Double)): Double = {
//获取结果
acc._2 / acc._1
}
override def merge(acc: (Int, Double), acc1: (Int, Double)): (Int, Double) = {
//合并
((acc._1 + acc1._1), (acc._2 + acc1._2))
}
}, createTypeInformation[(Int, Double)])
aggregatingStateDescriptor
//获取运行时全文
val context = getRuntimeContext
//获取状态
state = context.getAggregatingState(aggregatingStateDescriptor)
}
override def map(in: (String, Double)): (String, Double) = {
//更新状态
state.add(in._2)
//输出
(in._1,state.get())
}
}
⑥.多个状态
package com.baizhi.state
import org.apache.flink.api.common.functions.{AggregateFunction, FoldFunction, ReduceFunction, RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor, FoldingState, FoldingStateDescriptor, ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object FoldState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.map(_.split("\\s+"))
.map(t=>(t(0)+":"+t(1),t(2).toDouble))
.keyBy(0)
.map(new FoldMapFuntion)
.print()
//4.执行
env.execute("word count")
}
}
class FoldMapFuntion extends RichMapFunction[(String,Double),(String,Double)]{
//创建2个状态对象
var state:FoldingState[Double,Double]=_ //用于储存值
var state2:ReducingState[Int]=_ //用于储存次数
override def open(parameters: Configuration): Unit = {
//创建状态描述器,存储值
val foldStateDescriptor = new FoldingStateDescriptor[Double, Double]("foldWordCount", 0.0, new FoldFunction[Double, Double] {
override def fold(t: Double, o: Double): Double = {
t + o
}
}, createTypeInformation[Double])
//创建第二个描述器,存储次数
val reduce2StateDescriptor = new ReducingStateDescriptor[Int]("reducing2WordCount", new ReduceFunction[Int] {
override def reduce(t: Int, t1: Int): Int = {
t + t1
}
}, createTypeInformation[Int])
//获取运行时全文
val context: RuntimeContext = getRuntimeContext
//获取状态对象
state = context.getFoldingState(foldStateDescriptor)
state2 = context.getReducingState(reduce2StateDescriptor)
}
override def map(in: (String, Double)): (String, Double) = {
//更新状态
state.add(in._2)
state2.add(1)
//返回
(in._1,state.get()/state2.get())
}
}
☆.State Time-To-Live (TTL)
Flink⽀持对上有的keyed state的状态指定TTL存活时间,配置状态的时效性,该特性默认是关闭。⼀旦开启该特性,Flink会尽最⼤努⼒删除过期状态。TTL⽀持单⼀值失效特性,同时也⽀持集合类型数据失效,例如MapState和ListState中的元素,每个元素都有⾃⼰的时效时间。
package com.baizhi.state
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.StateTtlConfig.{StateVisibility, UpdateType}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, StateTtlConfig, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.time.Time
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object ClearState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.flatMap(_.split("\\s+"))
.map(t=>(t,1))
.keyBy(0)
.map(new ReduceMap2Function)
.print()
//4.执行
env.execute("word count")
}
}
class ReduceMap2Function extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var state:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val reducingStateDescriptor = new ReducingStateDescriptor[Int]("reducingWordCount", new ReduceFunction[Int] {
override def reduce(t: Int, t1: Int): Int = {
t + t1
}
}, createTypeInformation[Int])
//创建一个状态的过期配置
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //①设置过期时间 ,配置5秒的过期时间
.setUpdateType(UpdateType.OnCreateAndWrite) //②设置更新类型 创建和修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //③设置过期数据的可视化策略,从不返回过期数据
.build()
//开启失效配置
reducingStateDescriptor.enableTimeToLive(stateTtlConfig)
//获取全文对象
val context = getRuntimeContext
//从全文中获取状态
state = context.getReducingState(reducingStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//更新状态
state.add(in._2)
//返回
(in._1,state.get())
}
}
①:该参数指定State存活时间,必须指定。
②:该参数指定State实效时间更新时机,默认值OnCreateAndWrite
- OnCreateAndWrite: 只有修改操作,才会更新时间
- OnReadAndWrite:只有访问读取、修改state时间就会更新
③:设置state的可⻅性,默认值NeverReturnExpired
- NeverReturnExpired:永不返回过期状态
- ReturnExpiredIfNotCleanedUp:如果flink没有删除过期的状态数据,系统会将过期的数据返回
注意::⼀旦⽤户开启了TTL特征,系统每个存储的状态数据会额外开辟8bytes(Long类型)的字节⼤⼩,⽤于存储state时间戳;系统的时效时间⽬前仅仅⽀持的是计算节点时间;如果程序⼀开始没有开启TTL,在服务重启以后,开启了TTL,此时服务在故障恢复的时候,会报错!
☆. 清除过期状态
Cleanup Of Expired State
在1.9.x之前Flink默认仅仅当⽤户读状态的时候,才会去检查状态数据是否失效,如果失效将失效的数据⽴即删除。但就会导致系统在⻓时间运⾏的时候,会存在很多数据已经过期了,但是系统⼜没有去读取过期的状态数据,该数据⼀直驻留在内存中。
在flink-1.10版本中,系统可以根据State backend配置,定期在后台收集失效状态进⾏删除。⽤户可以通过调⽤以下API关闭⾃动清理。
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.disableCleanupInBackground()
.build()
△.Cleanup in full snapshot
在快照中清除模式
可以通过配置Cleanup in full snapshot机制,在系统恢复的时候或者启动的时候, 系统会加载状态数据,此时会将过期的数据删除。也就意味着系统只⽤在重启或者恢复的时候才会加载状态快照信息。
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupFullSnapshot()
.build()
缺点:需要定期的关闭服务,进⾏服务重启,实现内存释放。
△.Incremental cleanup
增量清除模式
⽤户还可以使⽤增量清理策略。在⽤户每⼀次读取或者写⼊状态的数据的时候,该清理策略会运⾏⼀次。系统的state backend会持有所有状态的⼀个全局迭代器。每⼀次当⽤⽤户访问状态,该迭代器就会增量迭代⼀个批次数据,检查是否存在过期的数据,如果存在就删除。
//设置TTL实效性
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupIncrementally(100,true)//1.表示⼀次检查key的数⽬ 2.表示有数据的数据就触发检查
.build()
第二个参数如果为false,表示只有在状态访问或者修改的时候才会触发检查
- 如果没有状态访问或者记录处理,过期的数据依旧不会删除,会被持久化。
- 增量检查state,会带来记录处理延迟。
- ⽬前增量式的清理仅仅在⽀持
Heap state backend,如果是RocksDB该配置不起作⽤。
△.Cleanup during RocksDB compaction
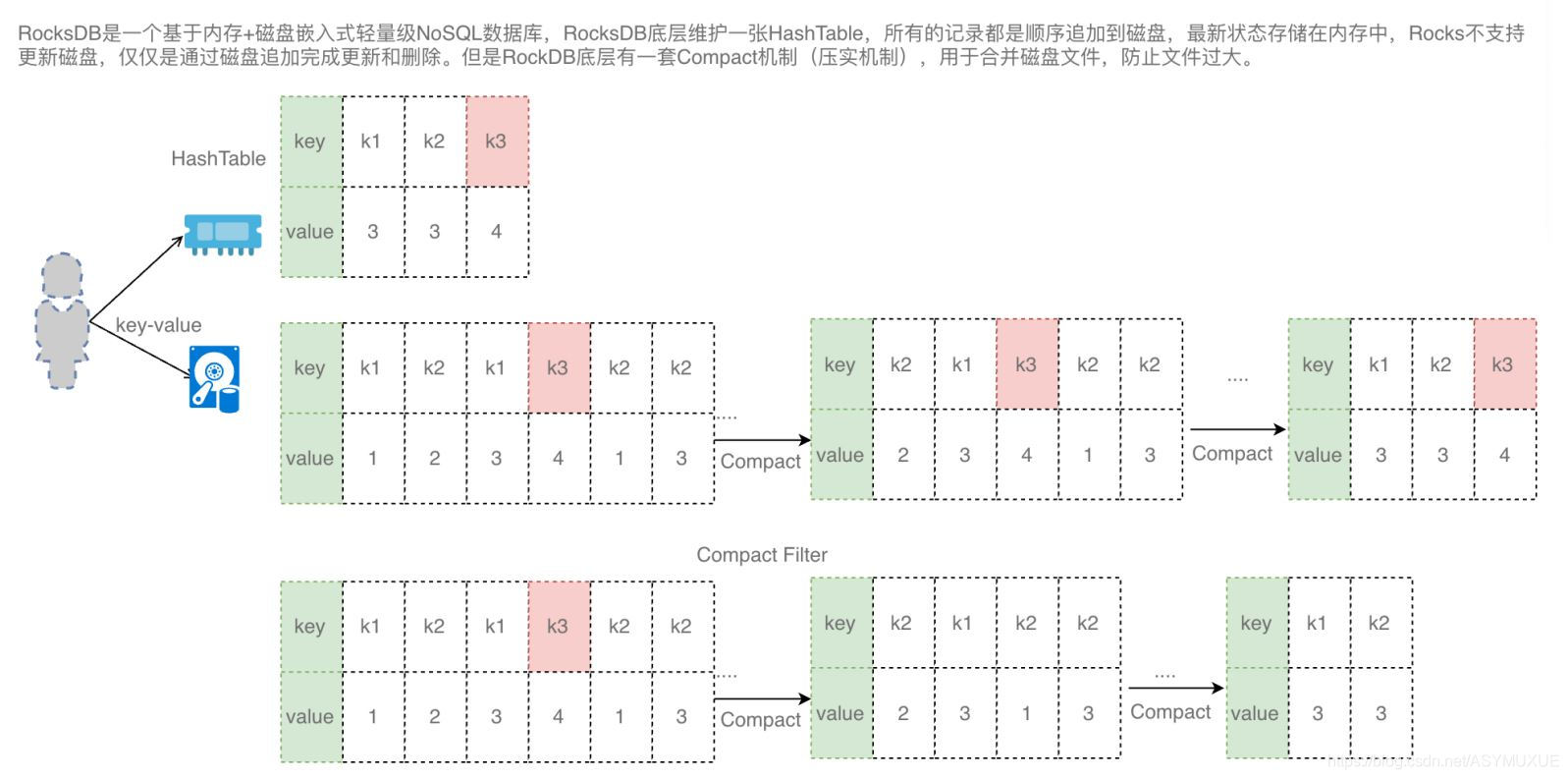
通过压实RocksDB的数据清除
如果⽤户使⽤的是RocksDB作为状态后端实现,⽤户可以在RocksDB在做Compation的时候加⼊Filter,对过期的数据进⾏检查。删除过期数据。
val stateTtlConfig = StateTtlConfig.newBuilder(Time.seconds(5)) //设置存活时间5s
.setUpdateType(UpdateType.OnCreateAndWrite) //创建、修改重新更新时间
.setStateVisibility(StateVisibility.NeverReturnExpired) //永不返回过期数据
.cleanupInRocksdbCompactFilter(1000)//进⾏合并扫描多少条记录之后,执⾏⼀次查询,将过期数据删除
.build()
更频繁地更新时间戳可以提⾼清除速度,但由于使⽤本地代码中的JNI调⽤,因此会降低压缩性能。每次处理1000个条⽬时,RocksDB后端的默认后台清理都会查询当前时间戳。
- 在flink-1.10版本之前,RocksDB的Compact Filter特性是关闭的,需要额外的开启,⽤户只需在
flink-conf.yaml中添加如下配置
state.backend.rocksdb.ttl.compaction.filter.enabled: true
三、检查点机制
由于Flink是⼀个有状态计算的流服务,因此状态的管理和容错是⾮常重要的。为了保证程序的健壮性,Flink提出Checkpoint机制,该机制⽤于持久化计算节点的状态数据,继⽽实现Flink故障恢复。所谓的Checkpoint机制指的是Flink会定期的持久化的状态数据。
将状态数据持久化到远程⽂件系统(取决于State backend),例如HDFS,该检查点协调或者发起是由JobManager负责实施。JobManager会定期向下游的计算节点发送Barrier(栅栏),下游计算节点收到该Barrier信号之后,会预先提交⾃⼰的状态信息,并且给JobManage以应答,同时会继续将接收到的Barrier继续传递给下游的任务节点,⼀次内推,所有的下游计算节点在收到该Barrier信号的时候都会做预提交⾃⼰的状态信息。等到所有的下游节点都完成了状态的预提交,并且JobManager收集完成所有下游节点的应答之后,JobManager才会认定此次的Checkpoint是成功的,并且会⾃动删除上⼀次检查点数据。
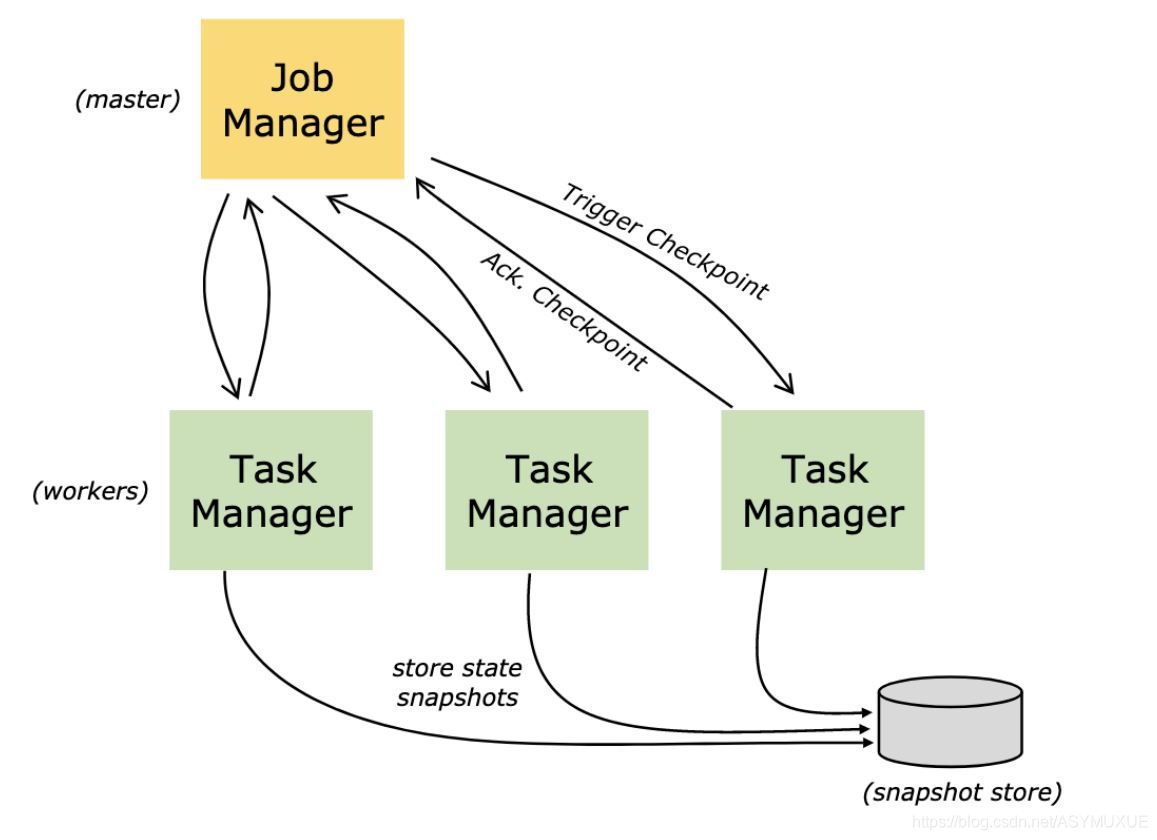
- 所谓的Checkpoint指的是程序在执⾏期间,程序会定期在⼯作节点上快照并产⽣Checkpoint。为了进⾏恢复,仅需要获取最后⼀次完成的Checkpoint即可,并且可以在新的Checkpoint完成后⽴即安全地丢弃较旧的Checkpoint。
- Savepoint是
⼿动触发的Checkpoint,Savepoint为程序创建快照并将其写到State Backend。Savepoint依靠常规的Checkpoint机制。 - Savepoint与这些定期Checkpoint类似,Savepoint由⽤户触发并且更新的Checkpoint完成时不会⾃动过期。⽤户可以使⽤命令⾏或通过
API取消作业时创建Savepoint
由于Flink 中的Checkpoint机制默认是不开启的,需要⽤户通过调⽤以下⽅法开启检查点机制。
env.enableCheckpointing(1000);
完整案例:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.memory.MemoryStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object CheckPoint {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//设置状态后端 1.路径
env.setStateBackend(new RocksDBStateBackend("hdfs:///03_10/RocksDBstateBackend",true))
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流
in.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
.map(new ValueMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class ValueMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var vs:ValueState[Int] = _
override def open(parameters: Configuration): Unit = {
//创建一个状态描述符
val valueStateDescriptor = new ValueStateDescriptor[Int]("valueWordCount",createTypeInformation[Int])
//获取运行时全文
val context = getRuntimeContext
//从全文中获取状态
vs = context.getState(valueStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//获取最新状态
vs.update(in._2+vs.value())
(in._1,vs.value())
}
}
四、状态后端
Flink指定多种State Backend实现,State Backend指定了状态数据(检查点数据)存储的位置信息。配置Flink的状态后端的⽅式有两种:
- 代码中定义,每个计算使用独立的状态后端
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStateBackend(...)
- 设置全局
flink-conf.yaml中配置
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# <class-name-of-factory>.
#设置检查后端的方式
state.backend: rocksdb
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
#设置检查点目录
state.checkpoints.dir: hdfs:///flink-checkpoints
# Default target directory for savepoints, optional.
#设置手动检查点目录
state.savepoints.dir: hdfs:///flink-savepoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#是否使用增量的检查模式
state.backend.incremental: false
另外,由于状态后端需要将数据同步到HDFS,因此Flink必须能够连接HDFS,所以需要在~/.bashrc配置 HADOOP_CLASSPATH
JAVA_HOME=/usr/java/latest
HADOOP_HOME=/usr/hadoop-2.9.2
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export CLASSPATH
export PATH
export HADOOP_HOME
#这里是~号
export HADOOP_CLASSPATH=`hadoop classpath`
执行命名
source .bashrc
①.MemoryStateBackend
MemoryStateBackend 使⽤内存存储内部状态数据,将状态数据存储在在Java的heap堆中。在Checkpoint时候,此状态后端将对该状态进⾏快照,并将其作为检查点确认消息的⼀部分发送给JobManager(主服务器),该JobManager也将其存储在其堆中。
val env = StreamExecutionEnvironment.getExecutionEnvironment()
//设置此种状态后端1.状态的大小 默认 5M; 2.是否异步的进行快照
env.setStateBackend(new MemoryStateBackend(MAX_MEM_STATE_SIZE, true))
限制:
- 默认情况下,每个状态的大小限制为5 MB。这个值可以在memorystateback的构造函数中增加。
- 不管配置的最大状态大小如何,状态都不能大于
akka帧的大小 - 聚合状态必须适合于JobManager内存。
使用场景:
- 本地部署进⾏debug调试的可以使⽤
- 不仅涉及太多的状态管理
②.FsStateBackend
该种状态后端实现是将数据的状态存储在TaskManager(计算节点)的内存。在执⾏检查点的时候后会将TaskManager内存的数据写⼊远程的⽂件系统。⾮常少量的元数据信息会存储在JobManager的内存中。
val env = StreamExecutionEnvironment.getExecutionEnvironment()
//1.检查点目录:2.是否异步的进行快照
env.setStateBackend(new FsStateBackend("hdfs:///flink-checkpoints",true))
使用场景:
- 当⽤户有⾮常⼤的状态需要管理
- 所有⽣产环境
③.RocksDBStateBackend
该种状态后端实现是将数据的状态存储在TaskManager(计算节点)的本地的RocksDB数据⽂件中。在执⾏检查点的时候后会将TaskManager本地的RocksDB数据库⽂件写⼊远程的⽂件系统。⾮常少量的元数据信息会存储在JobManager的内存中。
- 引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.10.0</version>
</dependency>
//1.创建流计算执⾏环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//1.检查点目录 2.是否开启增量的检查
env.setStateBackend(new RocksDBStateBackend("hdfs:///flink-rocksdb-checkpoints",true))
限制:
- 由于RocksDB的JNI桥API基于byte[],所以每个键和每个值支持的最大大小为2 ^ 31个字节。
使用场景:
- 当⽤户有超⼤的状态需要管理
- 所有⽣产环境
五、Managed Operator State
Flink提供了基于keyed stream操作符状态称为keyedstate,对于⼀些⾮keyed stream的操作中使⽤的状态统称为Operator State,如果⽤户希望使⽤Operator State需要实现通⽤的CheckpointedFunction接⼝或者ListCheckpointed。
- 当前,Operator State⽀持list-style的Managed State。该状态应为彼此独⽴的可序列化对象的列表,因此在系统故障恢复的时候才有可能进⾏重新分配。⽬前Flink针对于Operator State分配⽅案有以下
两种:
Ⅰ.Even-split redistribution - 每⼀个操作符实例都会保留⼀个List的状态,因此Operator State逻辑上是将该Operator的并⾏实例的所有的List状态拼接成⼀个完成的List State。
- 当系统在恢复、重新分发状态的时候,系统会根据当前Operator实例并⾏度,对当前的状态进⾏
均分。例如,如果在并⾏度为1的情况下,Operator的检查点状态包含元素element1和element2,则在将Operator并⾏度提⾼到2时,element1可能会分配给Operator Instance 0,⽽element2将进⼊Operator Instance 1.
Ⅱ.Union redistribution: -
- 在还原/重新分发状态时,每个Operator实例都会获得状态元素的
完整列表。
①.CheckpointedFunction
其中CheckpointedFunction接⼝提供non-keyed state的不同状态分发策略。⽤户在实现该接⼝的时候需要实现以下两个⽅法:
public interface CheckpointedFunction {
//当系统进⾏Checkpoint的时候,系统回调⽤该⽅法,将持久化的状态数据存储到状态中
void snapshotState(FunctionSnapshotContext context) throws Exception;
//进⾏状态初始化。或者系统在故障恢复的时候进⾏状态的恢复。
void initializeState(FunctionInitializationContext context) throws Exception;
}
实例:
定义一个实现了CheckpointedFunction的类
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.runtime.state.{FunctionInitializationContext, FunctionSnapshotContext}
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction
import org.apache.flink.streaming.api.functions.sink.SinkFunction
import org.apache.flink.api.scala._
import scala.collection.JavaConverters._
import scala.collection.mutable.ListBuffer
//定义一个阈值
class MydefinedCheckPointFunction(threshlod:Int=0) extends SinkFunction[(String,Int)] with CheckpointedFunction{
//创建一个状态对象,@transient 不对此对象进行序列化
@transient
private var state:ListState[(String,Int)]=_
//创建一个buffer对象
private var listBuffer = ListBuffer[(String,Int)]()
//此方法实现写出逻辑
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
//添加最新的值
listBuffer += value
//当缓冲超过阈值时,输出
if(listBuffer.size >= threshlod){
for(e <- listBuffer){
print("这里是invoke的缓冲输出"+e+"/t")
}
//输出后,清空此缓冲区
listBuffer.clear()
}
}
//进行状态的存储
override def snapshotState(functionSnapshotContext: FunctionSnapshotContext): Unit = {
println("快照中...")
//在每次更新状态前,先清除之前的状态
state.clear()
//更新状态
state.update(listBuffer.asJava)
}
//状态初始化,或者恢复时的状态恢复
override def initializeState(functionInitializationContext: FunctionInitializationContext): Unit = {
//创建一个状态描述器
val descriptor = new ListStateDescriptor[(String,Int)]("operatorCheckPointFunction",createTypeInformation[(String,Int)])
//从全文获取状态
state = functionInitializationContext.getOperatorStateStore.getListState(descriptor) //默认均分⽅式恢复
//如果这个全文是恢复的
if(functionInitializationContext.isRestored){
//就继续向缓冲区写入检查点的数据
listBuffer.appendAll(state.get().asScala.toList)
println("这里是状态恢复点------>>>>>>>>>>>>>>>>>"+listBuffer.mkString(","))
}
}
}
测试:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.memory.MemoryStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object CheckPointFunctionTest {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置状态后端 1.路径
env.setStateBackend(new RocksDBStateBackend("hdfs:///03_10/RocksDBstateBackend/OperatorState_01",true))
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流
val count = in.flatMap(_.split("\\s+"))
.map(x => (x, 1))
.keyBy(0)
.map(new ValueMapFunction)
.uid("ValueState_01") //设置uid,为了使得故障恢复时,程序DAG不变的情况下,并行度改变仍可用
//设置数据沉降的阈值
count.addSink(new MydefinedCheckPointFunction(3))
.uid("DefinedCheckPointFunction_01")
//4.执行
env.execute("word count")
}
}
class ValueMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var vs:ValueState[Int] = _
override def open(parameters: Configuration): Unit = {
//创建一个状态描述符
val valueStateDescriptor = new ValueStateDescriptor[Int]("valueWordCount",createTypeInformation[Int])
//获取运行时全文
val context = getRuntimeContext
//从全文中获取状态
vs = context.getState(valueStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//获取最新状态
vs.update(in._2+vs.value())
(in._1,vs.value())
}
}
②.ListCheckpointed
ListCheckpointed接⼝是CheckpointedFunction的更有限的变体写法。因为该接⼝仅仅⽀持list-style state的Even Split分发策略。
public interface ListCheckpointed {
//在做系统检查点的时候,⽤户只需要将需要存储的数据返回即可
List snapshotState(long checkpointId, long timestamp) throws Exception;
//直接提供给⽤户需要恢复状态
void restoreState(List state) throws Exception;
}
实例:
定义一个实现了 ListCheckpointed的类
import org.apache.flink.streaming.api.checkpoint.ListCheckpointed
import org.apache.flink.streaming.api.functions.source.{RichParallelSourceFunction, SourceFunction}
import java.lang.{Long => JLong}
import java.util
import java.util.Collections
import scala.collection.JavaConverters._
//因为需要序列化的特性,所有第二个泛型传递的是java中的Long
class MyDefinedListCheckPoint extends RichParallelSourceFunction[Long] with ListCheckpointed[JLong]{
//定义一个运行时变量
@volatile//防止线程拷贝变量
private var isRunning:Boolean=true
//定义一个Long类型的偏移量
private var offset:Long = 0
//此方法在检查点时,直接返回需要存储的数据
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[JLong] = {
println("快照中...."+offset)
//返回一个不可拆分的集合
Collections.singletonList(offset)
}
//恢复状态,直接提供需要恢复的状态
override def restoreState(state: util.List[JLong]): Unit = {
println("状态恢复中"+state.asScala)
//获取储存的偏移量
offset = state.asScala.head
}
//输入源开启后,怎么输入
override def run(sourceContext: SourceFunction.SourceContext[Long]): Unit = {
//获取源的锁对象
val lock = sourceContext.getCheckpointLock
while (isRunning){
//线程休息一秒
Thread.sleep(1000)
//当在读取的时候,不允许写
lock.synchronized({
//输入这个源
sourceContext.collect(offset)
//每秒offset+1
offset += 1
})
}
}
override def cancel(): Unit = {
//停止流
isRunning = false
}
}
测试:
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.memory.MemoryStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object ListCheckPoint {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置状态后端 1.路径
env.setStateBackend(new RocksDBStateBackend("hdfs:///03_10/RocksDBstateBackend/OperatorState_02",true))
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.获取输入源
val in = env.addSource(new MyDefinedListCheckPoint).uid("DefinedListCheckPoint_01")
in.print("偏移量是")
//4.执行
env.execute("word count")
}
}
六、广播状态
Broadcast State Pattern
⼴播状态是Flink提供的第三种状态共享的场景。通常需要将⼀个吞吐量⽐较⼩的流中状态数据进⾏⼴播给下游的任务,另外⼀个流可以以只读的形式读取⼴播状态。
①. DataStream ++ BroadcastStream
import org.apache.flink.api.common.state.MapStateDescriptor
import org.apache.flink.streaming.api.datastream.BroadcastStream
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
//datastream BroadcaseStream 链接
object RulerStream {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(4)
//获取一个高吞吐量流
val stream1: DataStream[String] = env.socketTextStream("hbase",9999)
//定义一个状态描述器
val broadCaseMapDes = new MapStateDescriptor[String,String]("broadCaseMapDes",
createTypeInformation[String],
createTypeInformation[String])
//获取一个广播流
val stream2: BroadcastStream[String] = env
.socketTextStream("hbase",8888)
.broadcast(broadCaseMapDes) //将这个广播流加上一个包装器
//定义一个输出标签
val tag = new OutputTag[String]("不匹配")
//链接2个流 1.标签 2.流状态描述器
val value: DataStream[String] = stream1.connect(stream2).process(new MyDefinedBroadCastProcessFunction(tag,broadCaseMapDes))
value.print("符合条件:")
value.getSideOutput(tag).print("不合条件的:")
env.execute("Ruler Match")
}
}
class MyDefinedBroadCastProcessFunction(tag:OutputTag[String],descriptor:MapStateDescriptor[String,String]) extends BroadcastProcessFunction[String,String,String]{
//处理一般流
override def processElement(in1: String, readOnlyContext: BroadcastProcessFunction[String, String, String]#ReadOnlyContext, collector: Collector[String]): Unit = {
//从状态描述器中获取这个广播流的状态
val readOnlyStreamState = readOnlyContext.getBroadcastState[String,String](descriptor)
//如果这个广播流中有定义的规则,则执行以下逻辑
if(readOnlyStreamState.contains("ruler")){
//获取这个规则值
val matchvalue = readOnlyStreamState.get("ruler")
//如果输入中包含此规则,那么输出
if(in1.contains(matchvalue)){
collector.collect(matchvalue+"\t"+in1)
}else{
//如果不含有此规则字符,则边输出
readOnlyContext.output(tag,in1)
}
}else{
//如果没有规则,也边输出
readOnlyContext.output(tag,in1)
}
}
//处理广播流
override def processBroadcastElement(in2: String, context: BroadcastProcessFunction[String, String, String]#Context, collector: Collector[String]): Unit = {
//从状态描述器中获取这个广播流的状态
val broadState = context.getBroadcastState[String,String](descriptor)
//向广播流中写入规则 1.key 为 ruler 2.value 为 in2,即流输入数据
broadState.put("ruler",in2)
}
}
②.KeyedStream ++ BroadcastStream
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{BroadcastState, MapStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.datastream.BroadcastStream
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction
import org.apache.flink.streaming.api.scala._
import org.apache.flink.util.Collector
//定义一个订单对象
case class Order(id:String,name:String,category:String,num:Int,price:Double)
//定义一个规则对象
case class Rule(shop:String,price:Double)
//定义一个用户对象
case class User(id:String,name:String)
object RewardStream {
def main(args: Array[String]): Unit = {
//获取流执行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(4)
//获取一般输入流 1 张三 电脑 1 5000
val stream1: KeyedStream[Order, String] = env.socketTextStream("hbase", 9999)
.map(_.split("\\s+"))
.map(x => Order(x(0), x(1), x(2), x(3).toInt, x(4).toDouble))
.keyBy(order => order.id + ":" + order.category)
//定义一个状态描述器 电脑 6000
val broadcastMapDescriptor: MapStateDescriptor[String, Double] =
new MapStateDescriptor[String,Double](
"BroadcastMapDescriptor",
createTypeInformation[String],
createTypeInformation[Double])
//获取广播流 //包装一个状态描述器
val stream2: BroadcastStream[Rule] = env.socketTextStream("hbase", 8888)
.map(_.split("\\s+"))
.map(x => Rule(x(0), x(1).toDouble))
.broadcast(broadcastMapDescriptor)
//拼接2个流
stream1.connect(stream2)
.process(new MydefinedKeyBroadcastProcessFunction(broadcastMapDescriptor))
.print("目标达成!!")
env.execute("BroadcastStream connect keyedStream")
}
}
// 参数1:key的类型 2.第一个流类型 3.第二个流类型 4.输出类型
class MydefinedKeyBroadcastProcessFunction(descroptor:MapStateDescriptor[String,Double]) extends KeyedBroadcastProcessFunction[String,Order,Rule,User]{
//定义一个状态变量,用于存储用户的消费金额
var accoun:ReducingState[Double]=_
//定义一个初始化状态的方法
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val accountDescriptor = new ReducingStateDescriptor[Double]("userAccountState", new ReduceFunction[Double] {
override def reduce(t: Double, t1: Double): Double = {
//返回和
t + t1
}
}, createTypeInformation[Double])
//获取运行时全文
val context = getRuntimeContext
//从全文获取此状态
accoun = context.getReducingState(accountDescriptor)
}
//处理正常流数据
override def processElement(in1: Order, readOnlyContext: KeyedBroadcastProcessFunction[String, Order, Rule, User]#ReadOnlyContext, collector: Collector[User]): Unit = {
//获取用户当前的消费金额
var money = in1.num * in1.price
//处理一次,状态更新一次
accoun.add(money)
//获取只读的广播流状态
val readOnlyState = readOnlyContext.getBroadcastState(descroptor)
//如果广播状态中含有值,并且状态中包含有用户购买的所对应类别
if(readOnlyState!=null && readOnlyState.contains(in1.category)){
//如果用户消费金额的状态值大于阈值,那么就给与奖励金
if(accoun.get()>=readOnlyState.get(in1.category)){
//清空消费金额的状态
accoun.clear()
collector.collect(User(in1.id,in1.name))
}else{
//如果消费金额不够,则直接打印
println(in1.id+"号用户\t"+in1.category+"\t消费金额不足奖励机制,距目标金额相差\t"+(readOnlyState.get(in1.category)-accoun.get())+"\tRMB")
}
}
}
//处理广播流数据
override def processBroadcastElement(in2: Rule, context: KeyedBroadcastProcessFunction[String, Order, Rule, User]#Context, collector: Collector[User]): Unit = {
//获取广播流流状态
val state: BroadcastState[String, Double] = context.getBroadcastState(descroptor)
//向流中更新数据
state.put(in2.shop,in2.price)
}
}
七、可查询的状态
Queryable State
①.架构
Client连接其中的⼀个代理服务区然后发送查询请求给Proxy服务器,查询指定key所对应的状态数据,底层Flink按照KeyGroup的⽅式管理Keyed State,这些KeyGroup被分配给了所有的TaskMnager的服务。每个TaskManage服务多个KeyGroup状态的存储。为了找到查询key所在的KeyGroup所属地TaskManager服务,Proxy服务会去询问JobManager查询TaskManager的信息,然后直接访问TaskManager上的QueryableStateServer服务器获取状态数据,最后将获取的状态数据返回给Client端。
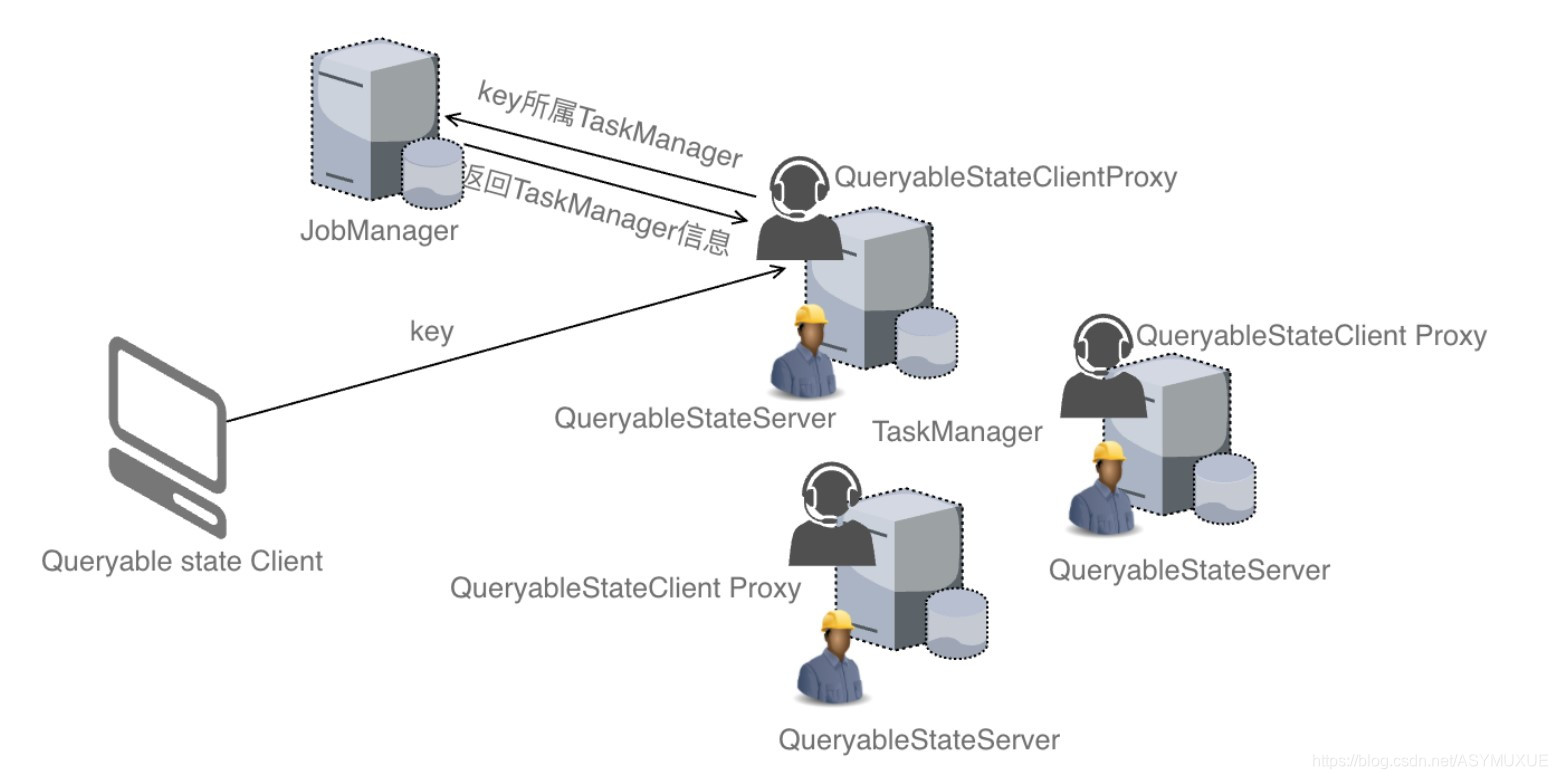
QueryableStateClient- 运⾏在Flink集群以外,负责提交⽤户的查询给Flink集群QueryableStateClientProxy- 运⾏在Flink集群中的TaskManager中的⼀个代理服务,负责接收客户端的查询,负责相应TaskManager获取请求的state,并将其state返回给客户端QueryableStateServer-运⾏在Flink集群中的TaskManager中服务,仅仅负责读取当前TaskManage主机上存储到状态数据。
②.配置开启可查询的状态
flink默认不开启 queryable state
-
cp opt/flink-queryable-state-runtime_2.11-1.10.0.jar lib/ #拷贝jar包到lib目录下 -
在Flink的flink-conf.yaml配置⽂件中添加以下配置
#任意位置即可,这里设置在 并行度的最后一行
queryable-state.enable: true
-
验证
启动 flink 服务,访问
8081,在任务节点的日志中出现Started Queryable State Server @ip:9069即成功配置
③.创建状态可见的流
2种方法:
- 创建QueryableStateStream,该QueryableStateStream充当⼀个Sink的输出,仅仅是将数据存储到state中。
- 或者stateDescriptor.setQueryable(String queryableStateName)⽅法使得我们的状态可查询。
特别注意:
目前只有keyed State支持查询。
另:
没有可查询的ListState接收器,因为它会导致一个不断增长的列表,这个列表可能不会被清除,因此最终会消耗太多的内存所有只有配置一个参数的 asQueryableState(String queryableStateName) 是显式使用ValueStateDescriptor变量的快捷方式
返回的QueryableStateStream可以看作是⼀个Sink,因为⽆法对QueryableStateStream进⼀步转换。在内部,QueryableStateStream被转换为运算符,该运算符使⽤所有传⼊记录来更新可查询状态实例。
使用asQueryableState:
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.{ReducingStateDescriptor, ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.contrib.streaming.state.RocksDBStateBackend
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.runtime.state.memory.MemoryStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object QueryableState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//定义一个状态描述器
val descript0 = new ReducingStateDescriptor[(String, Int)]("descript01", new ReduceFunction[(String, Int)] {
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
//返回此状态
(t._1, (t._2 + t1._2))
}
}, createTypeInformation[(String, Int)])
//3.处理流
in.flatMap(_.split("\\s+"))
.map(x=>(x,1))
.keyBy(0)
.asQueryableState("wordCount_1",descript0) //设置可查询的状态包装器
//4.执行
env.execute("word count")
}
}
使用 Keyedstate
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.StateTtlConfig.{StateVisibility, UpdateType}
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor, MapState, MapStateDescriptor, ReducingState, ReducingStateDescriptor, StateTtlConfig, ValueState, ValueStateDescriptor}
import org.apache.flink.api.common.time.Time
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object ReduceState {
def main(args: Array[String]): Unit = {
//1.获取流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.设置并行度
env.setParallelism(4)
//开启检查点
//每5秒检查一次,检查策略:精准一次
env.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
//设置检查点超时时间
env.getCheckpointConfig.setCheckpointTimeout(4000)
//设置检查点的最小间隔时间
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//设置检查点的失败策略 失败即退出任务
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(0)
//设置任务取消检查点策略
//取消任务,自动保留检查点数据
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//2.获取输入源
val in = env.socketTextStream("hbase",9999)
//3.处理流 01 zs apple
in.flatMap(_.split("\\s+"))
.map(t=>(t,1))
.keyBy(0)
.map(new ReduceMapFunction)
.print()
//4.执行
env.execute("word count")
}
}
class ReduceMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
//创建一个状态对象
var state:ReducingState[Int]=_
override def open(parameters: Configuration): Unit = {
//创建一个状态描述器
val reducingStateDescriptor = new ReducingStateDescriptor[Int]("reducingWordCount", new ReduceFunction[Int] {
override def reduce(t: Int, t1: Int): Int = {
t + t1
}
}, createTypeInformation[Int])
//设置可查询的状态属性
reducingStateDescriptor.setQueryable("queryableState_2")
//获取全文对象
val context = getRuntimeContext
//从全文中获取状态
state = context.getReducingState(reducingStateDescriptor)
}
override def map(in: (String, Int)): (String, Int) = {
//更新状态
state.add(in._2)
//返回
(in._1,state.get())
}
}
④.查询状态
以③中的 asQueryableState API 为基础
package com.baizhi.queryable
import java.util.concurrent.CompletableFuture
import java.util.function.Consumer
import org.apache.flink.api.common.JobID
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.queryablestate.client.QueryableStateClient
import org.apache.flink.api.scala._
object ReadQueryableState {
def main(args: Array[String]): Unit = {
//创建一个可查询客户端
val client = new QueryableStateClient("hbase",9069)
//设置jobID
val id = JobID.fromHexString("99e6f1a665271a471ce37c5355430ece")
//设置查询的状态名
val name = "wordCount_1"
//设置key的类型
val ty: TypeInformation[String] = createTypeInformation[String]
//创建一个状态描述器
val des = new ReducingStateDescriptor[(String, Int)]("DES1", new ReduceFunction[(String, Int)] {
override def reduce(t: (String, Int), t1: (String, Int)): (String, Int) = {
(t._1, (t1._2 + t._2))
}
}, createTypeInformation[(String, Int)])
des
//查询,获取完整的查询结果
val result: CompletableFuture[ReducingState[(String, Int)]] = client.getKvState(id,name,"this",ty,des)
/* //同步获取结果
val state: ReducingState[(String, Int)] = result.get()
//输出
println(state.get())
//结束
client.shutdownAndWait()*/
//异步获取结果
result.thenAccept(new Consumer[ReducingState[(String, Int)]] {
override def accept(t: ReducingState[(String, Int)]): Unit = {
//输出
println(t.get())
}
})
//因为是异步的获取,所有线程需要休眠一下,再停止
Thread.sleep(1000)
//停止
client.shutdownAndWait()
}
}
