深度学习论文: TurboViT: Generating Fast Vision Transformers via Generative Architecture Search及其PyTorch实现
TurboViT: Generating Fast Vision Transformers via Generative Architecture Search
PDF: https://arxiv.org/pdf/2308.11421.pdf
PyTorch代码: https://github.com/shanglianlm0525/CvPytorch
PyTorch代码: https://github.com/shanglianlm0525/PyTorch-Networks
1 概述
本文通过生成式架构搜索(GAS)探索了快速视觉Transformer架构设计的生成,以实现精确性与架构和计算效率之间的强大平衡。在这个生成式架构搜索过程中,创建了TurboViT,这是一个高效的分层视觉Transformer架构设计,它基于Mask单元注意力和Q-pooling设计模式生成。
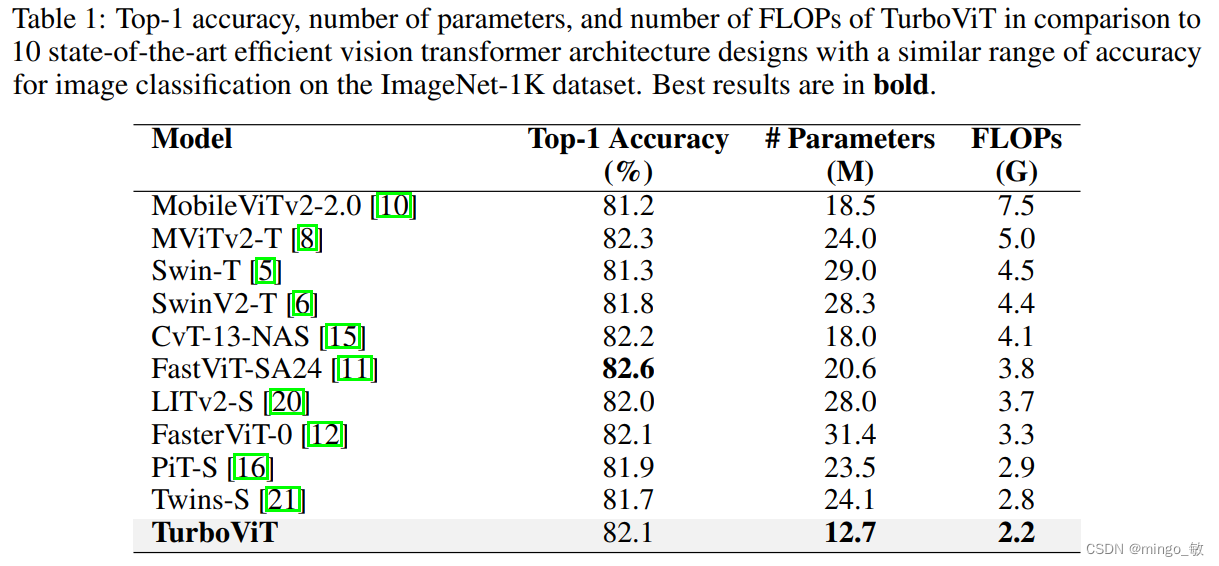
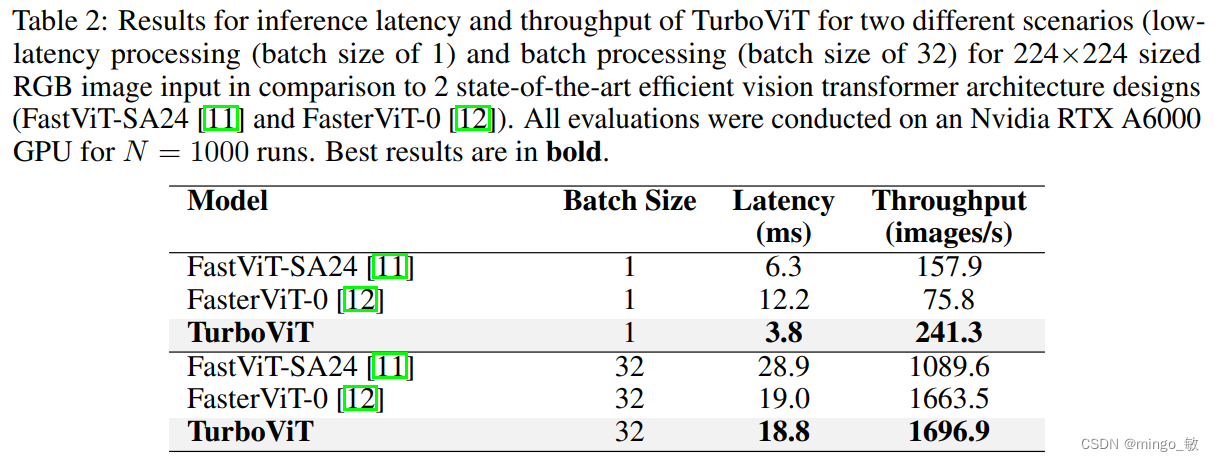
实验结果显示,TurboViT架构设计在架构计算复杂性方面显著更低(与FasterViT-0相比,大小缩小了2.47倍以上,同时达到了相同的准确性)。在计算复杂性方面,TurboViT也更低(与MobileViT2-2.0相比,FLOP减少了3.4倍以上,准确性提高了0.9%以上)。与ImageNet-1K数据集上的其他10种最先进的高效视觉Transformer网络架构设计相比,TurboViT在相似准确性范围内表现出色。
2 TurboViT
本文采用了generative architecture search (GAS)进行了TurboViT的架构搜索。下图展示了通过生成式架构搜索生成的TurboViT架构设计。整体而言,可以观察到该架构设计相当简洁和流畅,主要由一系列ViT块组成。与其他最先进的高效视觉Transformer架构设计(尤其是更复杂的混合卷积-Transformer架构设计)相比,TurboViT具有相对较低的隐藏维度和头数(特别是与ViT相比),因此有助于实现更高的架构和计算效率。
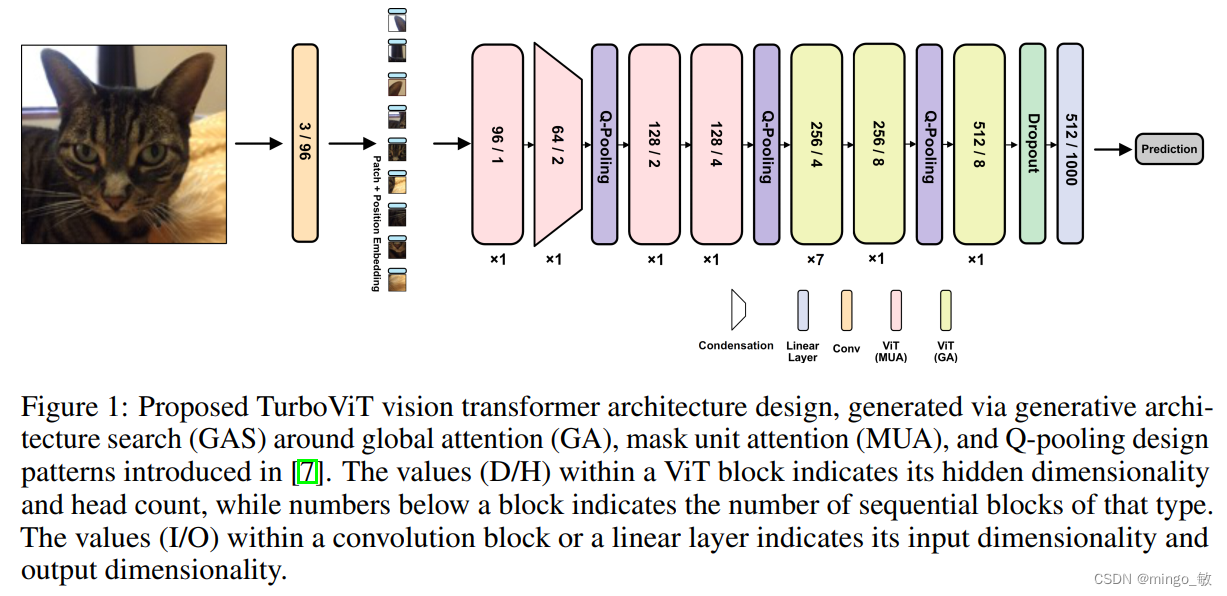
TurboViT架构设计在三个不同位置上都采用了Q-pooling,以通过空间降维实现架构和计算效率。大部分层位于第二个Q-pooling之后。同时在TurboViT架构设计中,早期的ViT块利用了通过掩码单元注意力实现的局部注意力,而后期的ViT块则利用了全局注意力,从而在计算效率方面取得显著的收益,而在全局注意力对模型性能贡献较小的情况下并不使用全局注意力。关于TurboViT架构设计的一个特别有趣的观察是,在架构设计的开始处引入了一个隐藏的维度压缩机制,在第二个ViT块中大大减少了隐藏维度,形成了一个高度压缩的嵌入,与第一个ViT块相比,随着向下移动架构,隐藏维度逐渐增加。这种压缩机制似乎在极大地减少计算复杂性的同时,仍能在整体架构设计中实现高度的表征能力。
3 Experiments