前言:HDFS是分布式存储的框架,能为大数据的计算框架(MR和spark)在大数据的内存中存取给予大量的支持,但是如果想快速,便捷地对一个大数据中局部小条目进行存取,这样的话在hdfs上就变得不太容易实现,所以Apache HBase是专门针对这一问题产生的技术框架。
一:关于Hbase
1.Hbase简介:
HBase 是 BigTable 之上建立的一个开源,分布式,多版本,面向列的非关系型数据库 。被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
2.HBase特性
1).表的数据量大,线性和模块化的可扩展性,使一个表可以达到数十亿行,数百万列。
2).Hbase与HDFS集成,Hbase支持HDFS作为其分布式文件系统,Hbase与MR集成,Hbase支持MR对其进行读取和大规模并行处理。 3).自动表切分:Hbase以Region为单位分布式存储于服务器集群中,当表数据递增至Region大小时,Region会通过中间键自动拆分为两个Region并自动分配到集群中。
4).面向列存储:按列来切割文件,列(族)独立检索,Hbase中的数据都是字符串,没有类型,每个单元中的数据可以有多个version,默认情况下版本号自动分配,是单元格插入时的时间戳。
二:Hbase数据模型
在Hbase中,数据存储在具有行和列的表中,这似乎与关系型数据库(RDBMS)类似,但其实并不是这样的。关系型数据库通过行与列来唯一的确定要查找的值,而在Hbase中通过行键(Rowkey),列(列:列修饰符)和时间戳来确定一个唯一的值。故关系型数据库的表中的值的映射关系为二维,而Hbase表中的映射关系为多维的。下面来分别讲述一下Hbase中的逻辑结构和物理存储结构。
1.逻辑结构
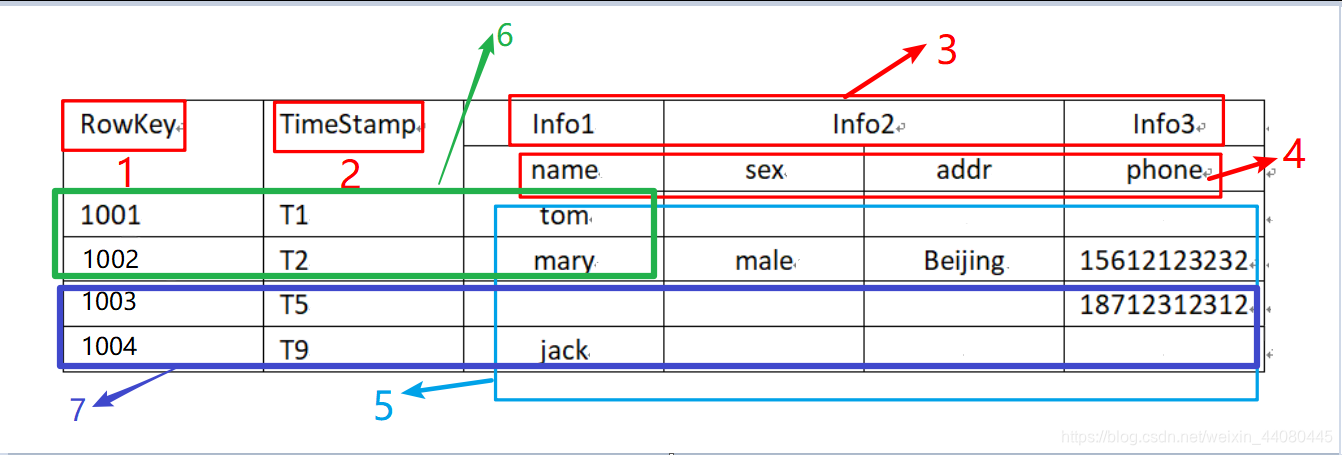
下面来讲述一下表的各个部分:
(1).RowKey:
与nosql数据库们一样,row key是用来检索记录的主键,并且每条数据的rowkey必须唯一,不重复。访问Hbase table中的行,Hbase的表是按key排序的,所有的表中都必须要有RowKey。
(2).Time Stamp:
用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase的时间。
(3).列族(Column Family):
HBase中的每个列都由Column Family(列族)和Column Qualifier(列修饰符)进行限定,例如info1:name,info2:age。建表时,只需指明列族,而列修饰符无需预先定义。
(4).列限定符:
每个列族的下面都有一个列限定符,列限定符可以动态的增加和删除。
(5).值(也叫cell):
由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的最小单元。例如Tom由{1001,T1,Info1,name}联和确定。
(6).store:
每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store(即有几个ColumnFamily,也就有几个Store)。
(7).Region:
类似于关系型数据库的表概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase能够轻松应对字段变更的场景。
2.物理存储结构
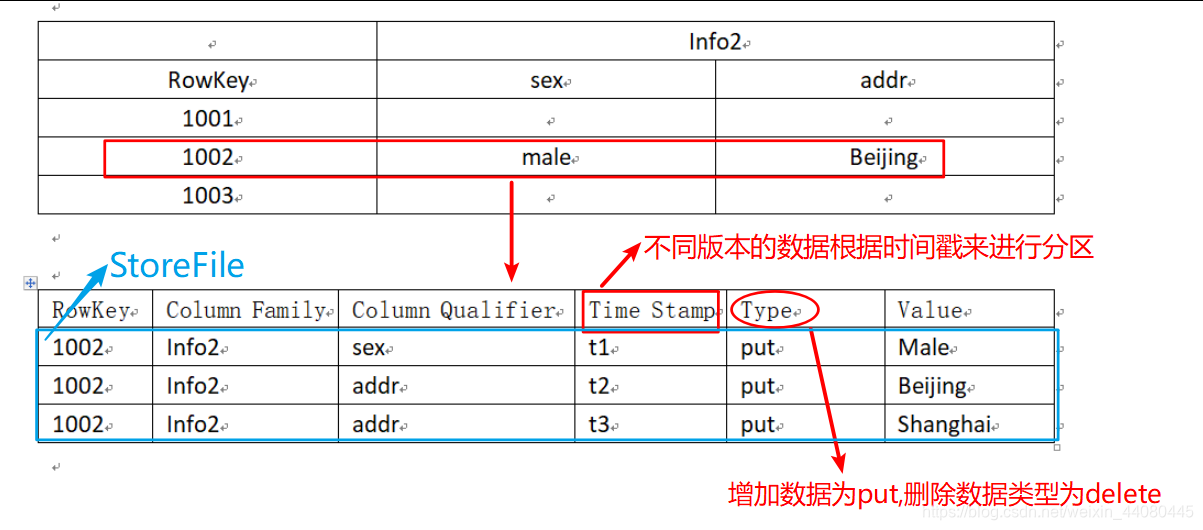
三:Hbase的架构原理
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion Server群和HBase Master服务器构成。其中 HBase Master服务器相当于集群的管理者,负责管理所有的HRegion Server,而HRegion Server相当于管理者手下的众多员工。HBase中所有的服务器都通过ZooKeeper来进行协调,并处理HBase服务器运行期间可能遇到的错误。HMaster 本身并不存储HBase中的任何数据,HBase逻辑上的表可能会被划分成多个HRegion.
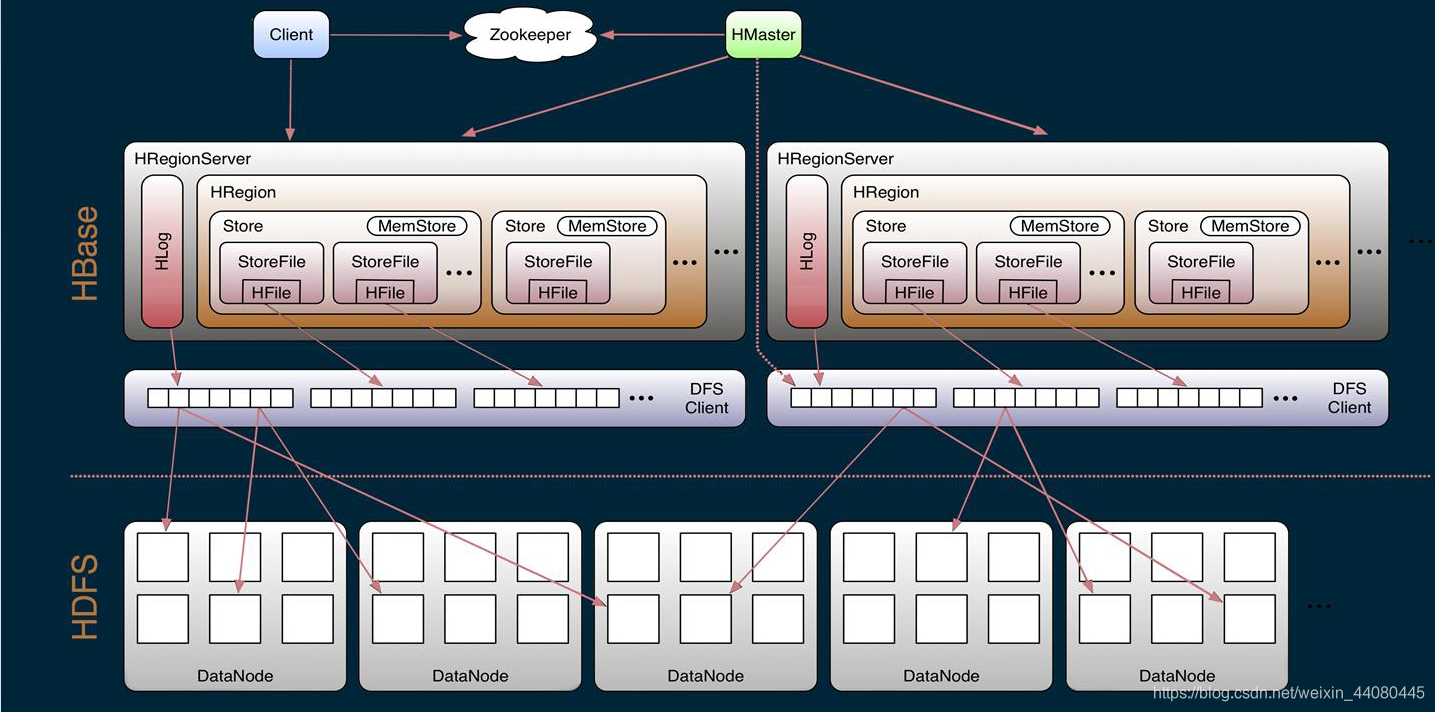
1.Client:
HBase Client 使用HBase的RPC机制(通信机制)与 HMaster和 HRegion Server 进行通信。对于DDL操作,Client与HMaster进行RPC;对于DML操作,Client与 HRegion Server 进行 RPC。HBase Client通过 meta表找到正在服务中的所在的 Region Server,找到所需的 Region 后,Client联系为该Region服务的Region Server,而不是Master,并发出读取或写入的请求。该信息被缓存在Client端,方便后继的请求不需要经过查找过程而直接使用。如果 Region 由主负载平衡器重新分配或 Region Server已经死亡,则客户机将重新查询目录表,以确定用户Region的新位置。
2.zookeeper:
1).保证任何时候,集群中只有一个活跃的master,因为为保证安全性会启动多个Master,这样的话master因为zookeeper的存在解决了单点故障的问题。
2).每台Region Server在ZK上注册来自己的临时节点,所以ZK存储所有Region的寻址入口。知道那个Region在哪台机器上。
3).实时监控Region Server的状态,将Region Server的上下线的信息汇报给HMaster。,将Region Server的上下线的信息汇报给HMaster。(因为每间隔一段时间,RegionServer与Master都会zookeeper发送心跳信息),Region Server不直接向Master发送信息的原因是为了减少Master的压力因为只有一个活跃的Master,所有的RegionServer同时向他汇报信息,压力太大。而若有100台RegionServer时,Region Server可以分每10台向一个zookeeper汇报信息,实现zookeeper的负载均衡
4).存储Hbase的元数据(Schema)包括,知道整个Hbase集群中有哪些Table,每个 Table 有哪些column family(列族)
3.Hmaster:
1).为HRegion Server分配HRegion,监控每个HRegion Server的状态
2). 负责HRegionServer的负载均衡
3).发现失效的HRegionServer并重新分配
4.Region Server:
Region Server为 Region的管理者,他里面存储着大量的Region,其实现类为HRegionServer,主要作用如下: 对于数据的操作(主要是DML):get, put, delete;对于Region的操作:splitRegion、compactRegion(对表的切分与合并)。
5.Region:
对用户来说,每个表是一堆数据的集合,靠主键RowKey来区分,且RowKey是系统内部按字典顺序排序的。当HBase中表的大小超过设置值的时候,HBase会使用中间的RowKey 键将表水平切割成两个Region,这一部分见上述内容( 二:Hbase数据模型之逻辑结构中的第七部分)
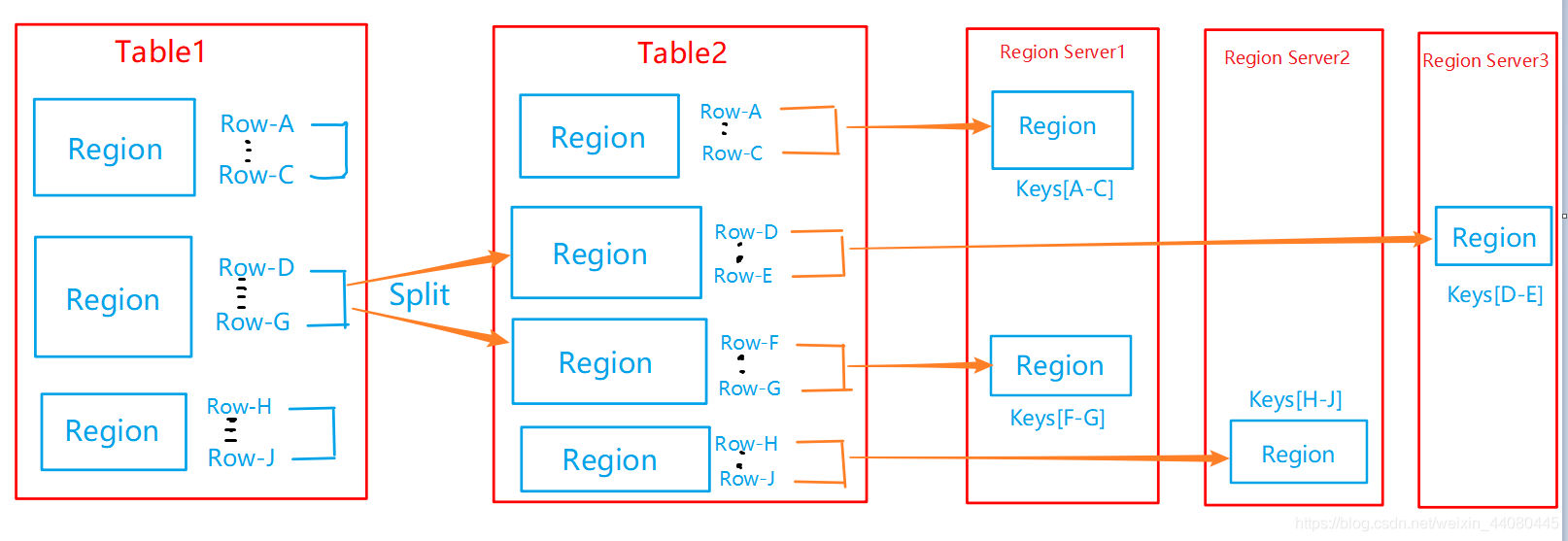
***Region拆分过程***
从物理上来讲,HBase中建立的表最初是一个Region,随着表记录数的增加,表内容所占资源增加,当增加到指定读值时,一个表被拆分成两块,每一块就是一个HRegion。依次类推,随着表记录数不断增加而变大后,会逐渐分裂成若干个HRegion。图8-8中展示的Tablel为3个Region时,随着RowKeyD~G范围值的增加,当该Region值达到國值时,会按中间键对该 Region 进行拆分,生成两个新的Region,RowKey范围分别是Row-D~E,Row-F~G。每个HRegion 会保存一个表里面某段连续的数据,从开始主键到结束主键,一张完整的表格被保存在多个HRegion上面, 即每个Region 由[startkey,endkey]表示。不同的Region会被Master分配给相应的Region Server 进行管理。可以讲Region是分布式存储的最小单位。
Region的层次关系如下。
Table (Hbase表)
|----Region (多个Regions组成Table)
|--------Store (存储在Table中的一个Region中存储的一个Colomn Family)
|-----------MemStore (每个Region中每个store有一个MemStore)
|-----------StoreFile (每个Region中的每个store有多个StoreFile)
|-------------------Block (每个StoreFile中有多个Block)
6.HLog:
WAL(Write-Ahead-Log)预写入日志是Hbase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。在每次Put、Delete等一条记录时,首先将其数据写入到RegionServer对应的HLog文件的过程,客户端往RegionServer端提交数据的时候,会先写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉提交数据成功,如果写WAL失败会告知客户端提交失败,换句话说这其实是一个数据落地的过程。hLog存在的作用就是当某一台Region Server关掉以后他可以将自己所记录的日志拿出来以备数据的恢复。
7.HStore:
HStore 是HBase存储的核心,由两部分组成,一部分是MemStore,另一部分是StoreFile。MemStore 是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile (底层实现是 HFile),当StoreFile文件数量增长到一定國值,会触发 Compact合并操作,将多个 StoreFile 合并成一个 StoreFile。合并过程中会进行版本合并和数据删除,当 StoreFile Compact后,会逐步形成越来越大的 StoreFile,当单个StoreFile大小超过一定國值后,会触发Split操作,同时把当前 Region 拆分成两个Region(此过程见上图Region的拆分过程),父Region 会下线,新拆分出的两个子 Region 会被 HMaster分配到相应的 HRegion Server 上,使原先一个Region的压力得以分流到两个Region上。
四:Hbase的安装部署:
https://blog.csdn.net/weixin_44080445/article/details/107436127