关于HBase环境搭建和java操作,请见笔者相关博客。
1.概述
HBase是一个分布式的、面向列的开源数据库,HBase的成熟应用归功于Google论文“Bigtable:一个结构化数据的分布式存储系统”。利用HBase技术可在廉价PC Server上搭建起大规模存储集群。
Hbase的名字的来源是Hadoop database,即hadoop数据库。
Hbase与传统的关系型数据库(如:MySql)不同,传统的关系型数据库是以行进行存储的,而Hbase是以列进行存储的。(注意,此处指的是存储结构。真正操作起来,为了方便理解,仍以行为基础进行操作)。传统的关系型数据库,没有索引的查询将消耗大量的I/O,如果建立索引或视图需要消耗大量的时间和资源。而Hbase是以列为基础进行存储的,以列存储的优势是“数据便是索引”(诸如数组)。在大量、高并发的查询时,极大地降低了系统的I/O。
2.HBase相关名词
table(表):以列为存储结构的表。
rowKey(行键):行键是每一行数据的标识,是不可分割的字节数组。行是按字典排序由低到高存储在表中的。
column family(列族):所有列成员的类型,列族里面存有一个到多个的key-value键值对(即列)。(下面会进一步说明)
cell(元组):单条数据。
3.HBase逻辑结构
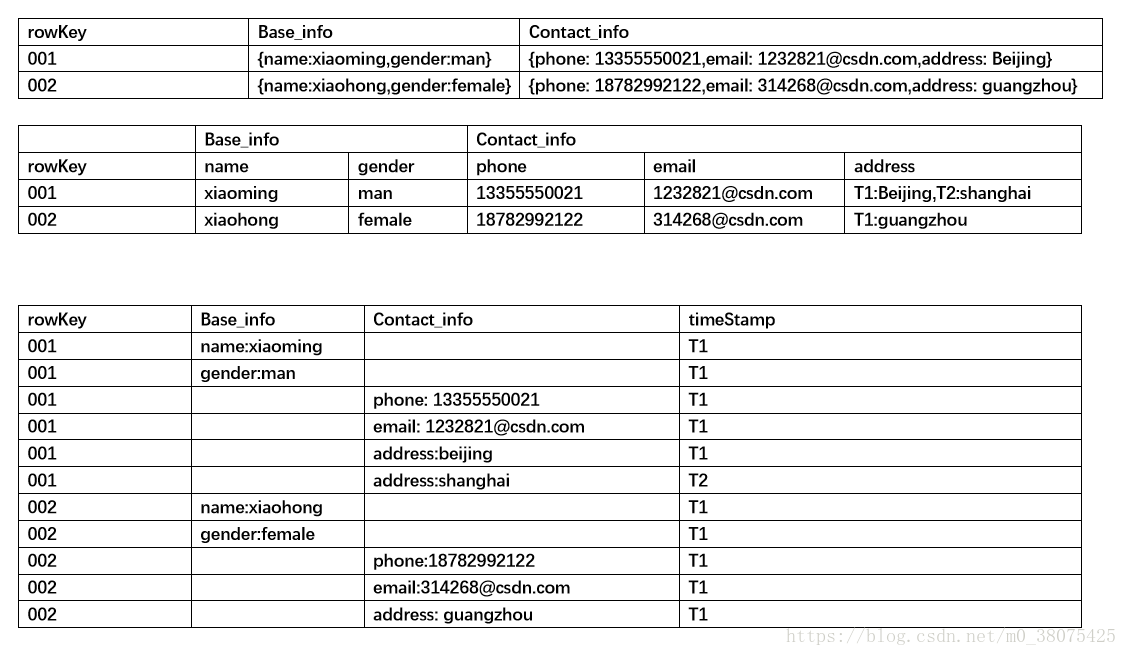
比如我们在一个表中需要存一个人,他的身份证号(唯一标识)是001;基本信息有:姓名-小明、性别-男,联系方式有:手机-13355550021、邮箱[email protected]、地址-北京市。
那么他的逻辑结构如下:

结构的演变由表1到表3,真正的结构为表3,但是为方便理解,在操作的时候,以表2为模型进行操作即可。
HBase的每列数据都有一个timeStamp时间戳,时间戳是版本的表示,在用户更新数据时,原数据会保留,未来还可以取的到。在查询时,默认查出最新的数据。如:将小明的地址更新为上海,存储结构则变为如下:

举例,多条数据的存储结构(又将小红存储进去):
4.HBase的物理结构
在逻辑结构,表可以被看成是一个稀疏的行的集合。但在物理上,它是以列族进行存储的。以上表3(一条数据时)是被分为两部分存储的:

为了便于理解,HBase在windows控制台显示样式如下:
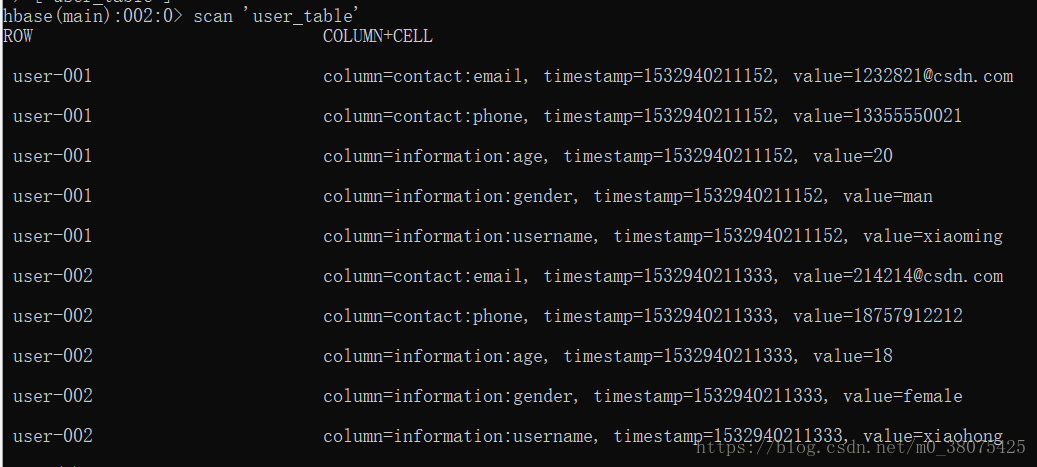
在上图,我们可以清晰地看到其列族结构。
其存储特性如下:
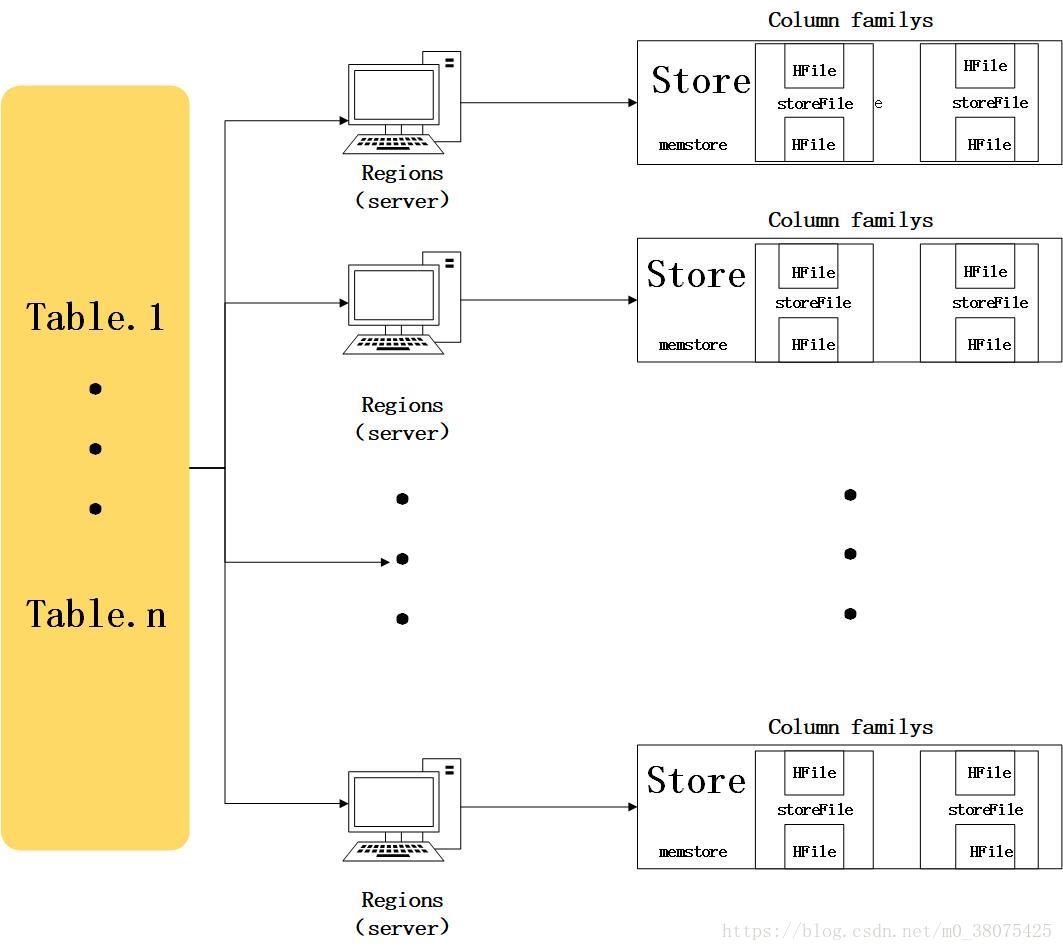
HBase在存储数据时,会将table存在region中,region 按大小分割的(默认 10G),每个表一开始只有一个 region,随着数据不断的增加, region 不断增大,当增大到一个阀值的时候, region 就会等分会两个新的 region。当 table 中的行不断增多,就会有越来越多的 region。region 是 HBase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 region 可以分布在不同的 server上。但一个 region 是不会拆分到多个 server 上的,region 由一个或者多个 store 组成, 每个 store 保存一个 column family。一个的column family成员在文件系统上都是存储在一起。因为存储优化都是针对列族级别的,这就意味着,一个colimn family的所有成员的是用相同的方式访问的。每个 strore 又由一个 memStore 和 0 至多个 StoreFile 组成,写操作先写入 memstore,当 memstore 中的数据量达到某个阈值, regionServer 启动flushcache 进程写入 storefile, 每次写入形成单独一个 Hfile,当 storefile 大小超过一定阈值后,会把当前的 region 分割成两个,并由 HMaster 分配给相应的 region 服务器,实现负载均衡,客户端检索数据时,先在 memstore 找,当memstore中找不到时,再从 storefile中找。
5.HBase的特性
- 强一致性读写: HBase 不是 "最终一致性(eventually consistent)" 数据存储. 这让它很适合高速计数聚合类任务。
- 自动分片(Automatic sharding): HBase 表通过region分布在集群中。数据增长时,region会自动分割并重新分布。
- RegionServer 自动故障转移
- Hadoop/HDFS 集成: HBase 支持本机外HDFS 作为它的分布式文件系统。
- MapReduce: HBase 通过MapReduce支持大并发处理, HBase 可以同时做源和目标.
- Java 客户端 API: HBase 支持易于使用的 Java API 进行编程访问.
- Thrift/REST API: HBase 也支持Thrift 和 REST 作为非Java 前端.
- Block Cache 和 Bloom Filters: 对于大容量查询优化, HBase支持 Block Cache 和 Bloom Filters。
- 运维管理: HBase提供内置网页用于运维视角和JMX 度量.
6.HBase应用场景
HBase不适合所有问题.
(1)首先,确信有足够多数据,如果有上亿或上千亿行数据,HBase是很好的备选。 如果只有上千或上百万行,则用传统的关系型数据库(MySql)可能是更好的选择。因为所有数据可以在一两个节点保存,集群其他节点可能闲置。
(2)其次,确信可以不依赖所有关系型数据库的额外特性 (例如,列数据类型, 第二索引, 事物,高级查询语言等) 一个建立在关系型数据库上应用,如不能仅通过改变一个JDBC驱动移植到HBase。因为相对于移植,需考虑从关系型数据库到HBase是一次完全的重新设计。
HBase 能在单独的笔记本上运行良好。但这应仅当成开发的测试环境。
7.HBase和Hadoop/HDFS 的区别
HDFS是分布式文件系统,适合保存大文件。官方宣称它并非普通用途文件系统,不提供文件的个别记录的快速查询。 另一方面,HBase基于HDFS且提供大表的记录快速查找(和更新)。这有时可能引起概念混乱。 HBase 内部将数据放到索引好的 "存储文件(StoreFiles)" ,以便高速查询。存储文件位于 HDFS中。总的来说,Hadoop仅仅是一个高吞吐量、分布式的基础文件系统,HBase是以此文件系统为基础的高速分布式key-value系统。
转载于:https://blog.csdn.net/m0_38075425/article/details/81283931