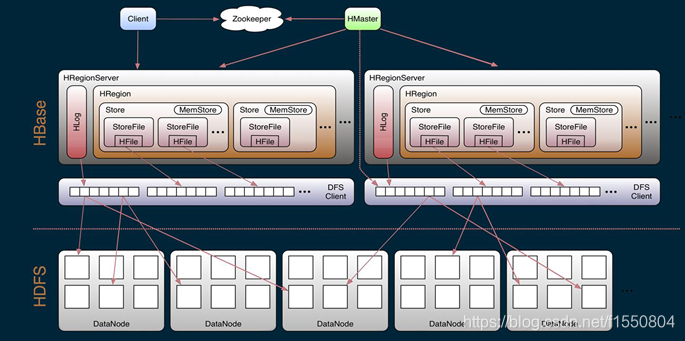
简单了解了HBase的基本概念之后,在接下来的安装部署HBase之前,首先要对HBase的体系结构进行了解。
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信
对于管理类操作,Client与HMaster进行RPC;
对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
HBase整体十分依赖zookeeper服务,zookeeper管理了所有HRegionServer的信息
每次客户端和Region Server连接时,都会先和zookeeper进行通信,查询出哪个RegionServer需要连接,在进行具体操作
1、ZooKeeper 为 HBase 提供 Failover 机制,选举 Master,避免单点 Master 单点故障问题
2、存储所有 Region 的寻址入口:-ROOT-表在哪台服务器上。-ROOT-这张表的位置信息
3、实时监控 RegionServer 的状态,将 RegionServer 的上线和下线信息实时通知给 Master
4、存储 HBase 的 Schema,包括有哪些 Table,每个 Table 有哪些 Column Family
HMaster
每台HRegion服务器都会和HMaster服务器通信,HMaster的主要任务就是要告诉每台HRegion服务器它要维护哪些HRegion。
当一台新的HRegion服务器登录到HMaster服务器时,HMaster会告诉它先等待分配数据。而当一台HRegion死机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegion服务器中。
1、管理用户对Table的增、删、改、查操作;
2、管理HRegion Server的负载均衡,调整Region分布;
3、如果HRegionServer宕机,负责重新分配该服务器region
4、HDFS 上的垃圾文件(HBase)回收
HRegion Server
简单来说,HRegionServer就是一个服务,它是存放Region的容器,
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
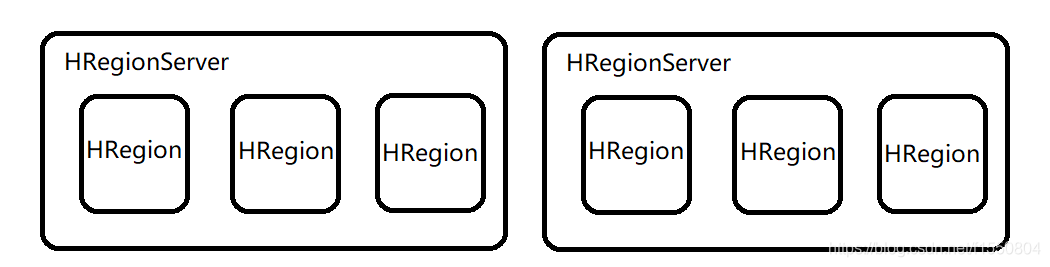
所有的数据库数据一般是保存在Hadoop分布式文件系统上面的,用户通过一系列HRegion服务器来获取这些数据,一台机器上面一般只运行一个HRegion服务器,且每一个区段的HRegion也只会被一个HRegion服务器维护。
当用户需要更新数据的时候,他会被分配到对应的HRegion服务器上提交修改,这些修改显示被写到Hmemcache(内存中的缓存,保存最近更新的数据)缓存和服务器的Hlog(磁盘上面的记录文件,他记录着所有的更新操作)文件里面。在操作写入Hlog之后,commit()调用才会将其返回给客户端。
在读取数据的时候,HRegion服务器会先访问Hmemcache缓存,如果缓存里没有改数据,才会回到Hstores磁盘上面寻找,每一个列族都会有一个HStore集合,每一个HStore集合包含很多HstoreFile文件
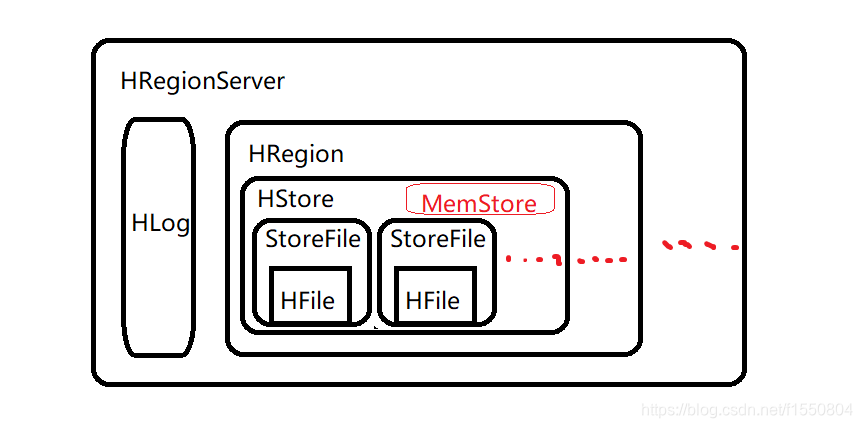
HRegion
Region就是一段数据的集合。
当表的大小超过设置值的时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集。
对用户来说,每个表是一堆数据的集合,靠主键来区分。
从物理上来说,一张表被拆分成了多块,每一块就是一个HRegion。我们用表名+开始/结束主键来区分每一个HRegion,一个HRegion会保存一个表里某段连续的数据,从开始主键到结束主键,一张完整的表是保存在多个HRegion上面的。
当HBase在进行负载均衡的时候,也有可能会从一台RegionServer上把Region移动到另一台RegionServer上。
Region是基于HDFS的,它的所有数据存取操作都是调用了HDFS的客户端接口来实现的。
下一章:深入理解HBase存储结构