一、首先准备好hadoop安装包
当然其他版本的也好,但jdk最好是1.8以上
可以使用ubuntu内部网站下载相关安装包,或者在windows下载之后通过ubuntu的客户端传入ubuntu
hadoop-2.7.7.tar.gz
jdk-8u141-linux-x64.tar.gz

二、安装前准备工作
1.将Ubuntu的机器名改为个人学号(根据课程要求,你们可改可不改)
sudo vi /etc/hostname
输入命令后,再次你的ubuntu密码,打开文件,修改内容(‘x’删除光标所在单个字符;‘I’进入修改(插入)模式;‘o’创建新的一行且为插入模式;‘dd’删除光标所在行;‘shift+g’光标直接移到文件末尾;‘shift+zz’保存文件内容)
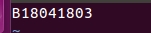
最终结果(重启后生效sudo reboot):

2.映射IP地址及主机名(这一步至关重要!重要!重要!没搞好会使得客户端无法操作)
(1) ip匹配主机名之前,要首先设计个人的网络配置
打开 虚拟机 > 主菜单的“编辑” > 点击“虚拟网络编辑器” > 点击“nat模式” > 点击“nat配置” > 查看个人虚拟机的网关ip(记下)

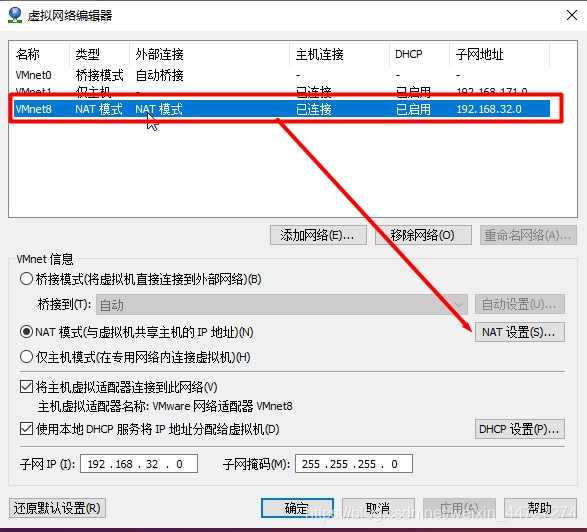
虚拟机网关ip
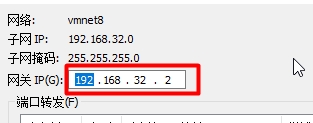
(2)点击虚拟机ubuntu的系统设置 > 网络(然后打开后点击右下角的"选项" 设置ip)
网络 配置ip4 (这里的“网关”要与上面要求记下的虚拟机网关“相同”;“地址”随便写,不超过ip地址的范围就行) :
最后要记得 保存!!保存!!保存!!>>>>>切记个人ip地址:192.168.32.33
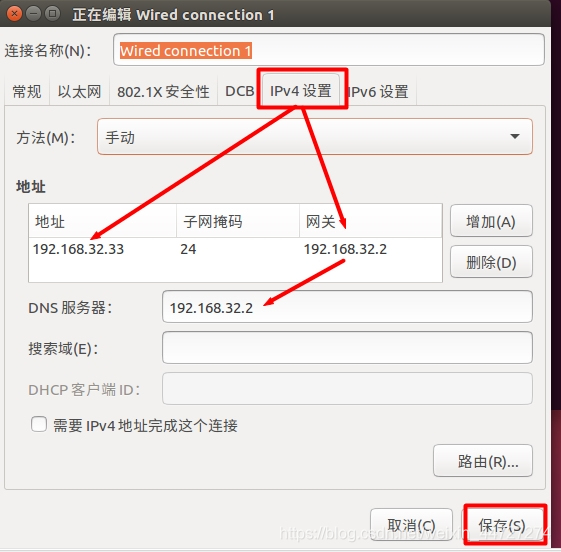
点击打开或者关闭>>>>>>>>查看到网关已经改变
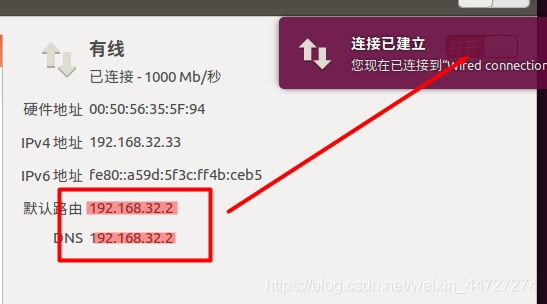
(3)映射ip和主机
sudo vi /etc/hosts

(4)重启使之生效并查看防火墙状态
sudo reboot
使防火墙状态处于“不活动”
sudo ufw status

三 、JDK安装
1.创建文件夹(存放jdk解压后路径并给文件赋权)
sudo mkdir /expt
sudo chmod 777 /expt
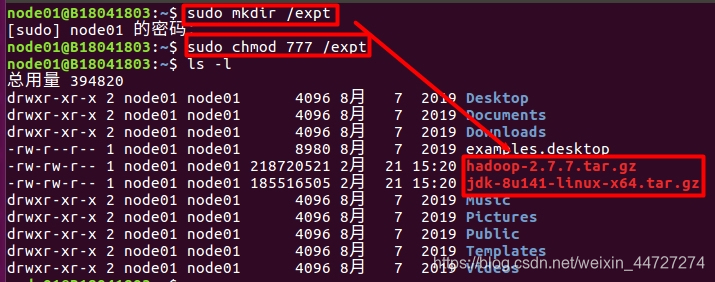
2.解压安装包到刚刚创建的文件夹expt

sudo tar -zxvf jdk-8u141-linux-x64.tar.gz -C /expt
然后创建软连接(软连接是方便jdk环境变量的配置)
出现 jdk-> 表示创建成功
ln -s /expt/jdk1.8.0_141 jdk

3.配置JDK环境变量
打开环境变量文件夹(‘I’进入修改(插入)模式;“shift+g”直接在文件最后添加;
“shift+zz”保存文件夹)
vi ~/.bashrc
 9
9
添加内容(光标移到文件末尾字母f时,点击‘o’即可,直接粘贴):
export JAVA_HOME=~/jdk
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
export PATH=${
JAVA_HOME}/bin:$PATH

环境变量生效!!生效!!生效!!
source ~/.bashrc
检验安装是否成功java –version
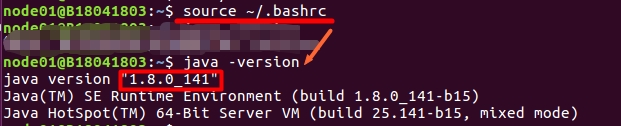
四、ssh免密登录设置
1.在主机上生成密钥对
ssh-keygen -t rsa

查看目录 ls ~/.ssh(确保生成下图两个文件)

2.将B18041803公钥id_rsa.pub复制到B18041803主机上
ssh-copy-id -i ~/.ssh/id_rsa.pub B18041803

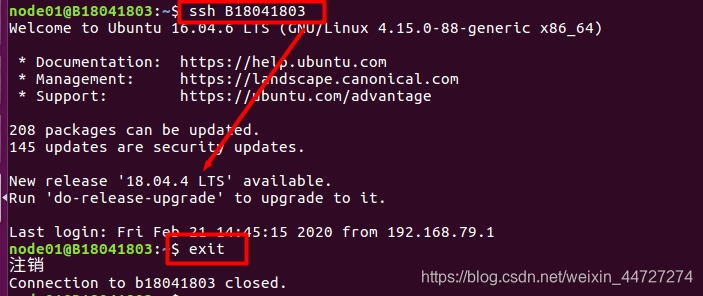
3.验证免密登录并退出
ssh B18041803
五、hadoop伪分布安装与系统文件配置
1.创建文件夹(存放hadoop的解压路径以及hadoop的数据临时文件)
mkdir /expt/server
mkdir /expt/data
mkdir /expt/data/hddata

2.解压安装包 并创建软连接
tar zxvf hadoop-2.7.7.tar.gz -C /expt/server
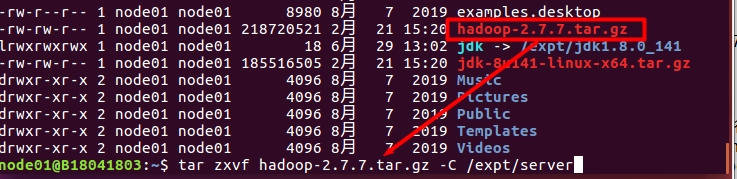
软连接:
ln -s /expt/server/hadoop-2.7.7 hadoop

3.配置环境变量
打开环境变量文件:vi ~/.bashrc
添加以下内容(光标移到文件末尾时,点击‘o’即可,直接粘贴):
export HADOOP_HOME=~/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
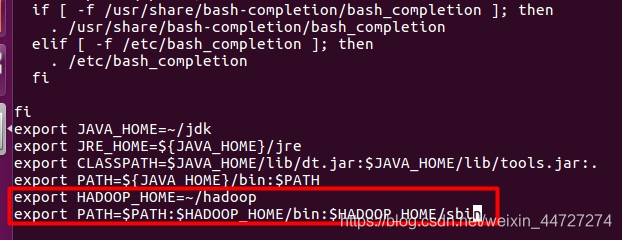
使环境变量生效!!生效!!生效!!source ~/.bashrc
4.hadoop系统文件配置(总共需要配置5个文件)
配置文件前,首先进入hadoop的配置文件存放路径下
cd ~/hadoop/etc/hadoop

(1)配置hadoop-env.shvi hadoop-env.sh
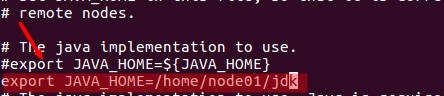
找到export JAVA_HOME一行,修改如下(“I”进入修改模式;shift+zz保存并退出):
export JAVA_HOME=/home/node01/jdk
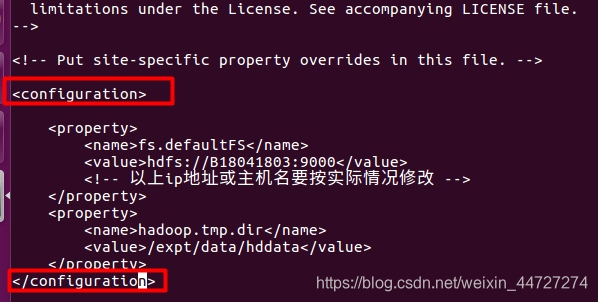
(2)配置core-site.xml vi core-site.xml
添加如下(主机名要根据自己的,且内容要在configuration之间):
<property>
<name>fs.defaultFS</name>
<value>hdfs://B18041803:9000</value>
<!-- 以上ip地址或主机名要按实际情况修改 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/expt/data/hddata</value>
</property>
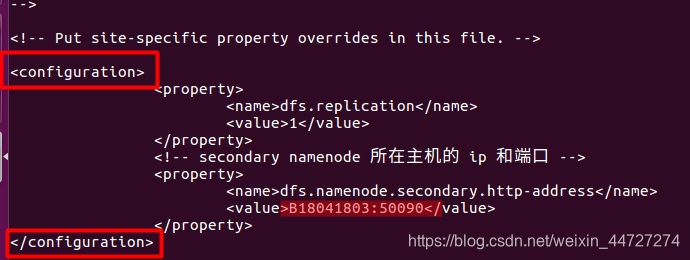
(3)配置hdfs-site.xml vi hdfs-site.xml
添加如下:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- secondary namenode 所在主机的 ip 和端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>B18041803:50090</value>
</property>
(4)配置mapred-site.xml(因该mapred-site.xml.template文件不可轻易更改)
复制得文件mapred-site.xml进行修改:
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
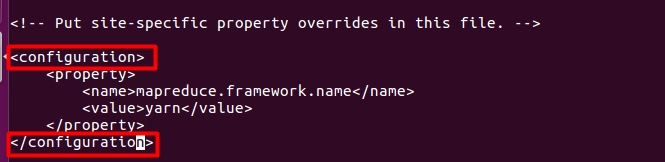
添加如下:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)配置yarn-site.xml vi yarn-site.xml
添加如下:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>B18041803</value>
<!-- 以上主机名或IP地址按实际情况修改 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>

六、hadoop格式化(格式化只能执行一次!!一次!!)
进入家目录下:cd
执行 hdfs namenode -format
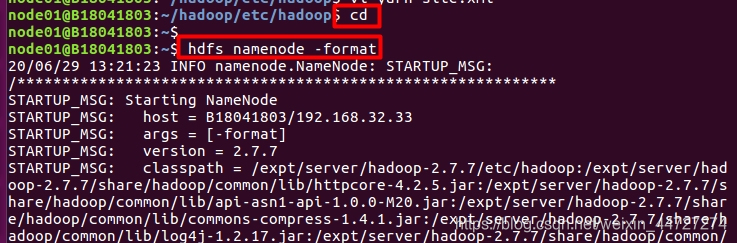
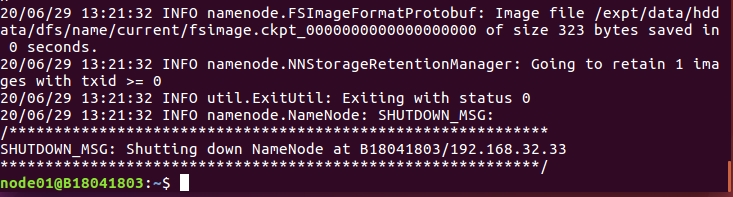
若出现以上结果,则hadoop安装基本完成!!!
七、启动Hadoop,验证Hadoop进程
启动hadoop,并使用jps验证,出现 5个进程 表示hadoop安装成功
start-all.sh

之后 也可使用stop-all.sh关闭hadoop!!