八、MergeTree系列表引擎
8.1 MergeTree
两项能力:数据TTL和存储策略。
8.1.1 TTL
TTL即time To Live,数据的存活时间。
MergeTree中,可以为某个列字段,或者整张表设置TTL。当时间到达时,如果是列字段级别为TTL,则会删除这一列数据;如果是表级别为TTL,则会删除整张表的数据;如果同时设置了列级别和表级别的TTL,会以先到时间的为准删除数据。
无论是列或者表级别的TTL,都依靠DateTime或Date类型字段,通过对这个时间字段的INTERVAL操作,来确定TTL过期时间:
示例:
TTL time_column + interval 3 DAY
表示数据存活的时间为time_column 时间的3天之后。
TTL time_column + interval 1 MONTH
表示数据存活的时间为time_column 时间的1月之后。
INTERVAL支持的操作:second,minute,hour,day,week,month,quarter,year。
8.1.1.1 列级别的TTL
若要设置列级别的TTL,则需要在定义表字段的时候,为他们声明TTL表达式,主键字段不能被声明TTL。
示例:
CREATE TABLE t_column_ttl
(
id UInt64 COMMENT 'Primary key',
create_time Datetime,
product_desc String TTL create_time + toIntervalSecond(10),
product_type UInt8 TTL create_time + toIntervalSecond(10)
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY id
insert into table t_column_ttl values(1,now(),'Huawei',1),(2,now()+interval 1 minute,'Apple',2);
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:16:28 │ Huawei │ 1 │
│ 2 │ 2020-12-24 16:17:28 │ Apple │ 2 │
└────┴─────────────────────┴──────────────┴──────────────┘
select sleep(10);
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:18:51 │ │ 0 │
│ 2 │ 2020-12-24 16:19:51 │ Apple │ 2 │
└────┴─────────────────────┴──────────────┴──────────────┘
optimize table t_column_ttl final;
select * from t_column_ttl;
┌─id─┬─────────create_time─┬─product_desc─┬─product_type─┐
│ 1 │ 2020-12-24 16:18:51 │ │ 0 │
│ 2 │ 2020-12-24 16:19:51 │ │ 0 │
└────┴─────────────────────┴──────────────┴──────────────┘
# 执行optimize命令会强制触发TTL清理,若再次查询可以看到满足TTL条件之后,定义了TTL操作的字段列会被还原为数据类型的默认值。
# 修改列字段的TTL或者修改已有字段的TTL:
alter table t_column_ttl MODIFY COLUMN product_desc String TTL create_time + INTERVAL 2 DAY;
# 添加字段的TTL:
alter table t_column_ttl add column product_name String comment '产品名称' ttl create_time + interval 3 month;
# 查看TTL的信息:
desc t_column_ttl\G
Row 1:
──────
name: id
type: UInt64
default_type:
default_expression:
comment: Primary key
codec_expression:
ttl_expression:
Row 2:
──────
name: create_time
type: DateTime
default_type:
default_expression:
comment:
codec_expression:
ttl_expression:
Row 3:
──────
name: product_desc
type: String
default_type:
default_expression:
comment:
codec_expression:
ttl_expression: create_time + toIntervalSecond(10)
Row 4:
──────
name: product_type
type: UInt8
default_type:
default_expression:
comment:
codec_expression:
ttl_expression: create_time + toIntervalSecond(10)
8.1.1.2 表级别的TTL
可以在MergeTree的表参数中增加TTL表达式 为整张表设置TTL。
设置之前需要查找配置的 disk和volume
SELECT * FROM system.disks
┌─name────┬─path──────────────────────┬───free_space─┬──total_space─┬─keep_free_space─┬─type──┐
│ default │ /var/lib/clickhouse/ │ 100418579456 │ 102818225152 │ 1024 │ local │
│ disk_1 │ /mnt/fast_ssd/clickhouse/ │ 49954570240 │ 52710309888 │ 0 │ local │
│ disk_2 │ /mnt/hdd1/clickhouse/ │ 39246221312 │ 42130964480 │ 10485760 │ local │
│ disk_3 │ /mnt/hdd2/clickhouse/ │ 39916331008 │ 42130964480 │ 10485760 │ local │
└─────────┴───────────────────────────┴──────────────┴──────────────┴─────────────────┴───────┘
select * from system.storage_policies\G
Row 1:
──────
policy_name: default
volume_name: default
volume_priority: 1
disks: ['default']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0
Row 2:
──────
policy_name: hdd_jbod
volume_name: jbod_volume
volume_priority: 1
disks: ['disk_2','disk_3']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 3:
──────
policy_name: policy_1_only
volume_name: volume_1
volume_priority: 1
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 4:
──────
policy_name: policy_hot_and_cold_data
volume_name: hot_volume
volume_priority: 1
disks: ['disk_1']
volume_type: JBOD
max_data_part_size: 1073741824
move_factor: 0.1
Row 5:
──────
policy_name: policy_hot_and_cold_data
volume_name: cold_volume
volume_priority: 2
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.1
Row 6:
──────
policy_name: policy_hot_and_cold_data_movefactor99
volume_name: hot_volume
volume_priority: 1
disks: ['disk_1']
volume_type: JBOD
max_data_part_size: 1073741824
move_factor: 0.01
Row 7:
──────
policy_name: policy_hot_and_cold_data_movefactor99
volume_name: cold_volume
volume_priority: 2
disks: ['disk_2']
volume_type: JBOD
max_data_part_size: 0
move_factor: 0.01
7 rows in set. Elapsed: 0.005 sec.
# 表的定义:
CREATE TABLE t_table_ttl
(
`id` UInt64 COMMENT '主键',
`create_time` Datetime COMMENT '创建时间',
`product_desc` String COMMENT '产品描述' TTL create_time + toIntervalMinute(10),
`product_type` UInt8
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(create_time)
ORDER BY create_time
表级别的TTL修改:
alter table t_table_ttl modify ttl create_time + interval 2 month;
查看信息:
SELECT
database,
name,
engine,
data_paths,
metadata_path,
metadata_modification_time,
partition_key,
sorting_key
FROM system.tables
WHERE name = 't_table_ttl'
Row 1:
──────
database: default
name: t_table_ttl
engine: MergeTree
data_paths: ['/var/lib/clickhouse/data/default/t_table_ttl/']
metadata_path: /var/lib/clickhouse/metadata/default/t_table_ttl.sql
metadata_modification_time: 2020-12-24 16:34:47
partition_key: toYYYYMM(create_time)
sorting_key: create_time
# 查看表的结构:
DESCRIBE TABLE t_table_ttl
Row 1:
──────
name: id
type: UInt64
default_type:
default_expression:
comment: 主键
codec_expression:
ttl_expression:
Row 2:
──────
name: create_time
type: DateTime
default_type:
default_expression:
comment: 创建时间
codec_expression:
ttl_expression:
Row 3:
──────
name: product_desc
type: String
default_type:
default_expression:
comment: 产品描述
codec_expression:
ttl_expression: create_time + toIntervalMinute(10)
Row 4:
──────
name: product_type
type: UInt8
default_type:
default_expression:
comment:
codec_expression:
ttl_expression:
注意:列级别或者表级别的TTL 目前暂不支持取消操作。
8.1.1.3 TTL的运行机理
若一张MergeTree表被设置为TTL 则在写入数据时候会以数据分区为单位,在每个分区目录内生成一个ttl.txt的文件。
写入数据:
insert into t_table_ttl(id,create_time,product_desc,product_type)values(10,now(),'Huawei',1),(20,now()+ interval 10 minute,'Apple',2);
ll /var/lib/clickhouse/data/default/t_table_ttl/
total 4
drwxr-x--- 2 clickhouse clickhouse 322 Dec 24 17:14 202012_1_1_0
drwxr-x--- 2 clickhouse clickhouse 6 Dec 24 16:34 detached
-rw-r----- 1 clickhouse clickhouse 1 Dec 24 16:34 format_version.txt
ll /var/lib/clickhouse/data/default/t_table_ttl/202012_1_1_0/
total 60
-rw-r----- 1 clickhouse clickhouse 464 Dec 24 17:14 checksums.txt
-rw-r----- 1 clickhouse clickhouse 115 Dec 24 17:14 columns.txt
-rw-r----- 1 clickhouse clickhouse 1 Dec 24 17:14 count.txt
-rw-r----- 1 clickhouse clickhouse 34 Dec 24 17:14 create_time.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 create_time.mrk2
-rw-r----- 1 clickhouse clickhouse 39 Dec 24 17:14 id.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 id.mrk2
-rw-r----- 1 clickhouse clickhouse 8 Dec 24 17:14 minmax_create_time.idx
-rw-r----- 1 clickhouse clickhouse 4 Dec 24 17:14 partition.dat
-rw-r----- 1 clickhouse clickhouse 8 Dec 24 17:14 primary.idx
-rw-r----- 1 clickhouse clickhouse 39 Dec 24 17:14 product_desc.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 product_desc.mrk2
-rw-r----- 1 clickhouse clickhouse 28 Dec 24 17:14 product_type.bin
-rw-r----- 1 clickhouse clickhouse 48 Dec 24 17:14 product_type.mrk2
-rw-r----- 1 clickhouse clickhouse 93 Dec 24 17:14 ttl.txt
cat /var/lib/clickhouse/data/default/t_table_ttl/202012_1_1_0/ttl.txt
ttl format version: 1
{
"columns":[{
"name":"product_desc","min":1608801843,"max":1608802443}]}
cat /var/lib/clickhouse/data/default/t_column_ttl/202012_1_1_1/ttl.txt
ttl format version: 1
{
"columns":[{
"name":"product_desc","min":1608802649,"max":1608802649},{
"name":"product_type","min":1608802649,"max":1608802649}]}
可以看到MergeTree是通过一串JSON配置保存了TTL的相关信息。
columns 用于保存列级别的TTL信息
tables 用于保存表级别的TTL信息
min和max则保存了当前数据分区内TTL指定的日期字段的最小值和最大值分别与INTERVAL表达式计算后的时间戳。
# 列
select toDateTime('1608801843') ttl_min,toDateTime('1608802443') ttl_max,ttl_min - min(create_time) expire_min,ttl_max - max(create_time) expire_max from t_table_ttl;
┌─────────────ttl_min─┬─────────────ttl_max─┬─expire_min─┬─expire_max─┐
│ 2020-12-24 17:24:03 │ 2020-12-24 17:34:03 │ 600 │ 600 │
└─────────────────────┴─────────────────────┴────────────┴────────────┘
# 表
select toDateTime('1608802649') ttl_min,toDateTime('1608802649') ttl_max,ttl_min - min(create_time) expire_min,ttl_max - max(create_time) expire_max from t_table_ttl;
┌─────────────ttl_min─┬─────────────ttl_max─┬─expire_min─┬─expire_max─┐
│ 2020-12-24 17:37:29 │ 2020-12-26 17:37:29 │ 86400 │ 86400 │
└─────────────────────┴─────────────────────┴────────────┴────────────┘
可以看ttl.txt 记录的极值区间恰好等于当前数据分区内create_time的最大值和最小值加1天(86400S ),和TTL的表达式的预期相符合。
通过TTL的信息记录方式 可以推断大体的处理逻辑:
1.MergeTree 是以分区目录为单位,通过ttl.txt 记录过期时间,并以此作为判断标准。
2.每当写入一批数据时候,都会基于interval 表达式的计算结果为这个分区生成ttl.txt 文件
3.只有在MergeTree合并分区才会触发TTL过期数据的逻辑
4.在删除分区的时候,选择使用了贪婪算法,算法规则即尽可能找到会最早过期,同时时间最早的分区。
5.若一个分区内某一列因为TTL到期则全部删除,在合并之后生成的新分区目录中将不会包含这个列字段的数据文件(.bin 和.mrk)
注意:
1.TTL默认的合并频率有MergeTree的参数merge_with_ttl_timeout 控制,默认周期为86400秒。它专门维护一个专有的TTL任务队列。有别于MergeTree的常规合并任务,若这个值设置的过小则可能会带来性能损耗。
此设置意味着仅在一个分区上或发生后台合并时,每24小时执行一次TTL删除。因此,在最坏的情况下,ClickHouse现在最多每24小时删除一个与TTL delete表达式匹配的分区。
此行为可能并不理想,因此,如果您希望TTL删除表达式更快地执行删除操作,则可以修改表的merge_with_ttl_timeout设置
设置为一个小时。
alter table t_table_ttl MODIFY SETTING merge_with_ttl_timeout = 3600;
2.除了触发TTL合并外,optimize 命令可以强制触发合并。
触发一个分区合并: optimize table t;
触发所有分区合并: optimize table t final;
3.目前没有删除ttl的声明方法,但是提供了全局控制TTL合并任务的启动和关停方法:
system stop/start TTL MERGES
8.1.2 多路径存储策略
<后面补充>
8.2 ReplacingMergeTree
MergeTree拥有主键,但是主键没有唯一键约束(会出现主键相同)。
ReplacingMergeTree为了数据去重而设计,能够在合并分区时删除重复的数据。一定程度解决了重复数据的问题(同数据分区)。
# 建表语法
CREATE TABLE replace_table(
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY(id,code)
PRIMARY KEY id ;
insert into replace_table values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-11 17:00:00'),('A001','C100','2019-05-12 17:00:00'),('A001','C200','2019-05-13 17:00:00'),('A002','C2','2019-05-14 17:00:00'),('A003','C3','2019-05-15 17:00:00');
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
ORDER BY是去除重复数据的关键,排序键ORDER BY所声明的表达式是后续作为判断数据是否重复的依据。在这个例子中,数据会基于id和code两个字段去重。
执行optimize强制触发合并后,会按照id和code分组,保留分组内的最后一条(观察create_time日期字段):
optimize TABLE replace_table FINAL;
select * from replace_table;
┌─i───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
从执行的结果来看,ReplacingMergeTree在去除重复数据时,确实是以ORDERBY排序键为基准的,而不是PRIMARY KEY。因为在上面的例子中,ORDER BY是(id, code),而PRIMARY KEY是id,如果按照id值去除重复数据,则最终结果应该只剩下A001、A002和A003三行数据。
CREATE TABLE replace_table_v1(
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree()
partition by toYYYYMM(create_time)
ORDER BY(id)
PRIMARY KEY id ;
insert into replace_table_v1 values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-11 17:00:00'),('A001','C100','2019-05-12 17:00:00'),('A001','C200','2019-05-13 17:00:00'),('A002','C2','2019-05-14 17:00:00'),('A003','C3','2019-05-15 17:00:00');
select * from replace_table_v1 ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table_v1 FINAL;
select * from replace_table_v1 ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
写入之后,执行optimize强制分区合并,并查询数据:
insert into replace_table values ('A001','C1','2020-07-02 12:01:01');
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2020-07-02 12:01:01 │
└──────┴──────┴─────────────────────┘
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table FINAL;
select * from replace_table;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2020-07-02 12:01:01 │
└──────┴──────┴─────────────────────┘
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-11 17:00:00 │
│ A001 │ C100 │ 2019-05-12 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
│ A002 │ C2 │ 2019-05-14 17:00:00 │
│ A003 │ C3 │ 2019-05-15 17:00:00 │
└──────┴──────┴─────────────────────┘
观察返回的数据,可以看到A001:C1依然出现了重复。这是因为ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。这就是上面说ReplacingMergeTree只是在一定程度上解决了重复数据问题的原因。
ReplacingMergeTree版本号的用法。以下面的语句为例:
CREATE TABLE replace_table_v (
id String,
code String,
create_time DateTime
) ENGINE = ReplacingMergeTree(create_time)
PARTITION BY toYYYYMM(create_time)
ORDER BY id ;
replace_table_v基于id字段去重,并且使用create_time字段作为版本号
insert into replace_table_v values('A001','C1','2019-05-10 17:00:00'),('A001','C1','2019-05-25 17:00:00'),('A001','C200','2019-05-13 17:00:00');
select * from replace_table_v
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-10 17:00:00 │
│ A001 │ C1 │ 2019-05-25 17:00:00 │
│ A001 │ C200 │ 2019-05-13 17:00:00 │
└──────┴──────┴─────────────────────┘
optimize TABLE replace_table_v FINAL;
select * from replace_table_v ;
┌─id───┬─code─┬─────────create_time─┐
│ A001 │ C1 │ 2019-05-25 17:00:00 │
└──────┴──────┴─────────────────────┘
ReplacingMergeTree的处理逻辑。
(1)使用ORBER BY排序键作为判断重复数据的唯一键。
(2)只有在合并分区的时候才会触发删除重复数据的逻辑。
(3)以数据分区为单位删除重复数据。当分区合并时,同一分区内的重复数据会被删除;不同分区之间的重复数据不会被删除。
(4)在进行数据去重时,因为分区内的数据已经基于ORBER BY进行了排序,所以能够找到那些相邻的重复数据。
(5)数据去重策略有两种:
❑ 如果没有设置ver版本号,则保留同一组重复数据中的最后一行。
❑ 如果设置了ver版本号,则保留同一组重复数据中ver字段取值最大的那一行。
8.3 SummingMergeTree
有这样一种查询需求:终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的(GROUP BY条件明确,且不会随意改变)。
对于这样的查询场景,在ClickHouse中如何解决呢?最直接的方案就是使用MergeTree存储数据,然后通过GROUP BY聚合查询,并利用SUM聚合函数汇总结果。这种方案存在两个问题。
❑ 存在额外的存储开销:终端用户不会查询任何明细数据,只关心汇总结果,所以不应该一直保存所有的明细数据。
❑ 存在额外的查询开销:终端用户只关心汇总结果,虽然MergeTree性能强大,但是每次查询都进行实时聚合计算也是一种性能消耗。
SummingMergeTree就是为了应对这类查询场景而生的。顾名思义,它能够在合并分区的时候按照预先定义的条件聚合汇总数据,将同一分组下的多行数据汇总合并成一行,这样既减少了数据行,又降低了后续汇总查询的开销。
在先前介绍MergeTree原理时曾提及,在MergeTree的每个数据分区内,数据会按照ORDER BY表达式排序。主键索引也会按照PRIMARY KEY表达式取值并排序。而ORDER BY可以指代主键,所以在一般情形下,只单独声明ORDER BY即可。此时,ORDER BY与PRIMARY KEY定义相同,数据排序与主键索引相同。
如果需要同时定义ORDER BY与PRIMARY KEY,通常只有一种可能,那便是明确希望ORDER BY与PRIMARY KEY不同。这种情况通常只会在使用SummingMergeTree或AggregatingMergeTree时才会出现。这是为何呢?这是因为SummingMergeTree与AggregatingMergeTree的聚合都是根据ORDER BY进行的。由此可以引出两点原因:主键与聚合的条件定义分离,为修改聚合条件留下空间。
现在用一个示例说明。假设一张SummingMergeTree数据表有A、B、C、D、E、F六个字段,如果需要按照A、B、C、D汇总,则有:
ORDER BY (A,B,C,D)
如此一来,此表的主键也被定义成了A、B、C、D。而在业务层面,其实只需要对字段A进行查询过滤,应该只使用A字段创建主键。所以,一种更加优雅的定义形式应该是:
ORDER BY (A,B,C,D)
PRIMARY KEY A
如果同时声明了ORDER BY与PRIMARY KEY, MergeTree会强制要求PRIMARYKEY列字段必须是ORDER BY的前缀。例如下面的定义是错误的:
ORDER BY(B,C)
PRIMARY KEY A
PRIMARY KEY必须是ORDER BY的前缀:
ORDER BY (B,C)
PRIMARY KEY B
这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。
假设现在业务发生了细微的变化,需要减少字段,将先前的A、B、C、D改为按照A、B聚合汇总,则可以按如下方式修改排序键:
ALTER TABLE table_name MODIFY ORDER BY (A,B)
在修改ORDER BY时会有一些限制,只能在现有的基础上减少字段。如果是新增排序字段,则只能添加通过ALTER ADD COLUMN新增的字段。但是ALTER是一种元数据的操作,修改成本很低,相比不能被修改的主键,这已经非常便利了。
现在开始正式介绍SummingMergeTree的使用方法。如下所示:
CREATE TABLE summing_table(
id String,
city String,
v1 UInt32,
v2 Float64,
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY (id,city)
PRIMARY KEY id ;
这里的ORDER BY是一项关键配置,SummingMergeTree在进行数据汇总时,会根据ORDER BY表达式的取值进行聚合操作。假设此时表内的数据如下所示:
insert into summing_table values('A001','wuhan',10,20,'2019-08-10 17:00:00') ,('A001','wuhan',20,30,'2019-08-20 17:00:00'),('A001','zhuhai',20,30,'2019-08-10 17:00:00');
insert into summing_table values('A001','wuhan',10,20,'2019-02-10 09:00:00') ;
insert into summing_table values('A002','wuhan',60,50,'2019-10-10 17:00:00') ;
select * from summing_table;
┌─id───┬─city───┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-08-10 17:00:00 │
│ A001 │ wuhan │ 20 │ 30 │ 2019-08-20 17:00:00 │
│ A001 │ zhuhai │ 20 │ 30 │ 2019-08-10 17:00:00 │
└──────┴────────┴────┴────┴─────────────────────┘
┌─id───┬─city──┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-02-10 09:00:00 │
└──────┴───────┴────┴────┴─────────────────────┘
┌─id───┬─city──┬─v1─┬─v2─┬─────────create_time─┐
│ A002 │ wuhan │ 60 │ 50 │ 2019-10-10 17:00:00 │
└──────┴───────┴────┴────┴─────────────────────┘
执行optimize强制进行触发和合并操作:
optimize TABLE summing_table FINAL
select * from summing_table;
┌─id───┬─city───┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 30 │ 50 │ 2019-08-10 17:00:00 │
│ A001 │ zhuhai │ 20 │ 30 │ 2019-08-10 17:00:00 │
└──────┴────────┴────┴────┴─────────────────────┘
┌─id───┬─city──┬─v1─┬─v2─┬─────────create_time─┐
│ A001 │ wuhan │ 10 │ 20 │ 2019-02-10 09:00:00 │
└──────┴───────┴────┴────┴─────────────────────┘
┌─id───┬─city──┬─v1─┬─v2─┬─────────create_time─┐
│ A002 │ wuhan │ 60 │ 50 │ 2019-10-10 17:00:00 │
└──────┴───────┴────┴────┴─────────────────────┘
在第一个分区内,同为A001:wuhan的两条数据汇总成了一行。其中,v1和v2被SUM汇总,不在汇总字段之列的create_time则选取了同组内第一行数据的取值。而不同分区之间,数据没有被汇总合并。
SummingMergeTree也支持嵌套类型的字段,在使用嵌套类型字段时,需要被SUM汇总的字段名称必须以Map后缀结尾,例如:
CREATE TABLE summing_table_nested(
id1 String,
nestMap Nested(
id UInt32,
key UInt32,
val UInt64
),
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id1 ;
在使用嵌套数据类型的时候,默认情况下,会以嵌套类型中第一个字段作为聚合条件Key。
假设表内的数据如下所示:
insert into summing_table_nested values('A001','[1,1,2]','[10,20,30]','[40,50,60]','2019-08-10 17:00:00') ;
select * from summing_table_nested;
┌─id1──┬─nestMap.id─┬─nestMap.key─┬─nestMap.val─┬─────────create_time─┐
│ A001 │ [1,1,2] │ [10,20,30] │ [40,50,60] │ 2019-08-10 17:00:00 │
└──────┴────────────┴─────────────┴─────────────┴─────────────────────┘
上述示例中数据会按照第一个字段id聚合,汇总后的数据会变成下面的样子:
optimize table summing_table_nested final;
select * from summing_table_nested;
┌─id1──┬─nestMap.id─┬─nestMap.key─┬─nestMap.val─┬─────────create_time─┐
│ A001 │ [1,2] │ [30,30] │ [90,60] │ 2019-08-10 17:00:00 │
└──────┴────────────┴─────────────┴─────────────┴─────────────────────┘
数据汇总逻辑示意如下:
[(1,10,40)] + [(1,20,50)] => [(1,30,90)]
[(2,30,60)] => [(2,30,60)]
在使用嵌套数据类型的时候,也支持使用复合Key作为数据聚合的条件。为了使用复合Key,在嵌套类型的字段中,除第一个字段以外,任何名称是以Key、Id或Type为后缀结尾的字段,都将和第一个字段一起组成复合Key。例如将上面的例子中小写key改为Key:
CREATE TABLE summing_table_v1(
id1 String,
nestMap Nested(
id UInt32,
Key UInt32,
val UInt64
),
create_time DateTime
) ENGINE = SummingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY id1 ;
insert into summing_table_v1 values('A001','[1,1,2]','[10,20,30]','[40,50,60]','2019-08-10 17:00:00');
insert into summing_table_v1 values('A001','[1,1,2]','[10,10,30]','[40,50,60]','2019-08-20 17:00:00');
select * from summing_table_v1;
┌─id1──┬─nestMap.id─┬─nestMap.Key─┬─nestMap.val─┬─────────create_time─┐
│ A001 │ [1,1,2] │ [10,10,30] │ [40,50,60] │ 2019-08-20 17:00:00 │
└──────┴────────────┴─────────────┴─────────────┴─────────────────────┘
┌─id1──┬─nestMap.id─┬─nestMap.Key─┬─nestMap.val─┬─────────create_time─┐
│ A001 │ [1,1,2] │ [10,20,30] │ [40,50,60] │ 2019-08-10 17:00:00 │
└──────┴────────────┴─────────────┴─────────────┴─────────────────────┘
optimize table summing_table_v1 final;
select * from summing_table_v1;
┌─id1──┬─nestMap.id─┬─nestMap.Key─┬─nestMap.val──┬─────────create_time─┐
│ A001 │ [1,1,2] │ [10,20,30] │ [130,50,120] │ 2019-08-10 17:00:00 │
└──────┴────────────┴─────────────┴──────────────┴─────────────────────┘
上述例子中数据会以id和Key作为聚合条件。知道了SummingMergeTree的使用方法后,现在简单梳理一下它的处理逻辑。
(1)用ORBER BY排序键作为聚合数据的条件Key。
(2)只有在合并分区的时候才会触发汇总的逻辑。
(3)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。
(4)如果在定义引擎时指定了columns汇总列(非主键的数值类型字段),则SUM汇总这些列字段;如果未指定,则聚合所有非主键的数值类型字段。
(5)在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同聚合Key的数据。
(6)在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值。
(7)支持嵌套结构,但列字段名称必须以Map后缀结尾。嵌套类型中,默认以第一个字段作为聚合Key。除第一个字段以外,任何名称以Key、Id或Type为后缀结尾的字段,都将和第一个字段一起组成复合Key。
8.4 AggregatingMergeTree
数据立方体:它通过以空间换时间的方法提升查询性能,将需要聚合的数据预先计算出来,并将结果保存起来。在后续进行聚合查询的时候,直接使用结果数据。
AggregatingMergeTree它能够在合并分区的时候,按照预先定义的条件聚合数据。同时,根据预先定义的聚合函数计算数据并通过二进制的格式存入表内。将同一分组下的多行数据聚合成一行,既减少了数据行,又降低了后续聚合查询的开销。
建表语句:
CREATE TABLE agg_table (
id String,
city String,
code AggregateFunction(uniq,String),
value AggregateFunction(sum,UInt32),
create_time DateTime
) ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(create_time)
ORDER BY(id,city)
PRIMARY KEY id ;
上例中列字段id和city是聚合条件,等同于下面的语义:
GROUP BY id,city
而code和value是聚合字段,其语义等同于:
UNIQ(code),SUM(value)
AggregatingMergeTree更为常见的应用方式是结合物化视图使用,将它作为物化视图的表引擎。而这里的物化视图是作为其他数据表上层的一种查询视图。
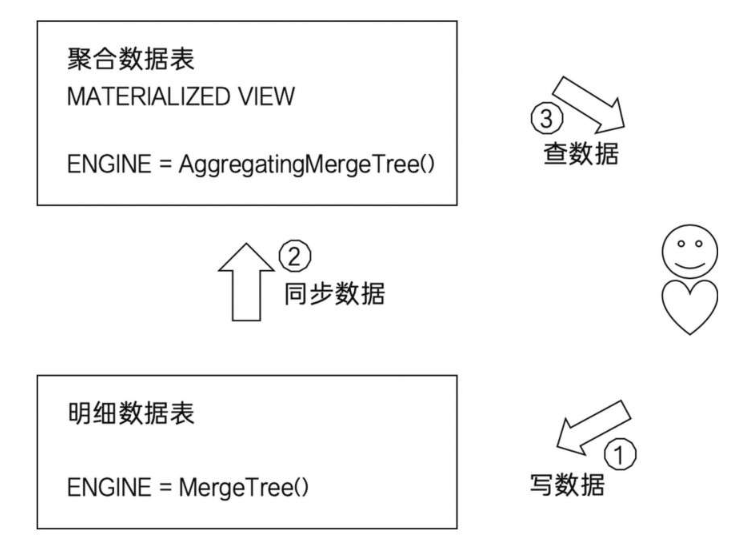
首先,建立明细数据表,也就是俗称的底表:
CREATE TABLE agg_table_basic(
id String,
city String,
code String,
value UInt32
) ENGINE = MergeTree()
PARTITION BY city
ORDER BY(id,city);
通常会使用MergeTree作为底表,用于存储全量的明细数据,并以此对外提供实时查询。接着,新建一张物化视图:
CREATE MATERIALIZED VIEW agg_view
ENGINE = AggregatingMergeTree()
PARTITION BY city
ORDER BY (id,city)
AS SELECT
id,city,
uniqState(code) AS code,
sumState(value) as value
FROM agg_table_basic
group by id,city;
物化视图使用AggregatingMergeTree表引擎,用于特定场景的数据查询,相比MergeTree,它拥有更高的性能。
在新增数据时,面向的对象是底表MergeTree:
INSERT INTO TABLE agg_table_basic
VALUES('A000','wuhan','code1',100),
('A000','wuhan','code2',200),
('A000','zhuhai','code1',200) ;
数据会自动同步到物化视图,并按照AggregatingMergeTree引擎的规则处理。
在查询数据时,面向的对象是物化视图AggregatingMergeTree:
SELECT id,sumMerge(value),uniqMerge(code) FROM agg_view GROUP BY id,city ;
AggregatingMergeTree的处理逻辑。
(1)用ORBER BY排序键作为聚合数据的条件Key。
(2)使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字段。
(3)只有在合并分区的时候才会触发聚合计算的逻辑。
(4)以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并计算,而不同分区之间的数据则不会被计算。(5)在进行数据计算时,因为分区内的数据已经基于ORBER BY排序,所以能够找到那些相邻且拥有相同聚合Key的数据。
(5)在聚合数据时,同一分区内,相同聚合Key的多行数据会合并成一行。对于那些非主键、非AggregateFunction类型字段,则会使用第一行数据的取值。
(6)AggregateFunction类型的字段使用二进制存储,在写入数据时,需要调用State函数;而在查询数据时,则需要调用相应的Merge函数。其中,*表示定义时使用的聚合函数。
(7)AggregatingMergeTree通常作为物化视图的表引擎,与普通MergeTree搭配使用。
8.5 CollapsingMergeTree
CollapsingMergeTree是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。这种1和-1相互抵消的操作,犹如将一张瓦楞纸折叠了一般。这种直观的比喻,想必也正是折叠合并树(CollapsingMergeTree)名称的由来,其折叠的过程如图所示。

建表示例:
CREATE TABLE collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8
) ENGINE = CollapsingMergeTree(sign)
PARTITION BY toYYYYMM(create_time)
ORDER BY id ;
与其他的MergeTree变种引擎一样,CollapsingMergeTree同样是以ORDER BY排序键作为后续判断数据唯一性的依据。按照之前的介绍,对于上述collpase_table数据表而言,除了常规的新增数据操作之外,还能够支持两种操作。
其一,修改一行数据:
--修改前的源数据,它需要被修改
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1);
--镜像数据,ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1);
--修改后的数据,sign为1
INSERT INTO TABLE collpase_table VALUES('A000',120,'2019-02-20 00:00:00',1);
其二,删除一行数据:
--修改前的源数据,它需要被修改
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',1);
--镜像数据,ORDER BY字段与源数据相同(其他字段可以不同),sign取反为-1,它会和源数据折叠
INSERT INTO TABLE collpase_table VALUES('A000',100,'2019-02-20 00:00:00',-1);
CollapsingMergeTree在折叠数据时,遵循以下规则。
❑ 如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。
❑ 如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。❑ 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
❑ 如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。
❑ 其余情况,ClickHouse会打印警告日志,但不会报错,在这种情形下,查询结果不可预知。在使用CollapsingMergeTree的时候,还有几点需要注意。
8.6 VersionedCollapsingMergeTree
VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。VersionedCollapsingMergeTree是从它的命名各位就应该能够猜出来是版本号。
建表示例:
CREATE TABLE ver_collpase_table(
id String,
code Int32,
create_time DateTime,
sign Int8,
ver UInt8
) ENGINE = VersionedCollapsingMergeTree(sign,ver)
PARTITION BY toYYYYMM(create_time)
ORDER BY id ;
在定义ver字段之后,VersionedCollapsingMergeTree会自动将ver作为排序条件并增加到ORDER BY的末端。以上面的ver_collpase_table表为例,在每个数据分区内,数据会按照ORDER BY id , ver DESC排序。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
--删除
INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1,1);
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1,1);
select * from ver_collpase_table;
optimize table ver_collpase_table FINAL;
select * from ver_collpase_table;
INSERT INTO TABLE ver_collpase_table VALUES('A000',101,'2019-02-20 00:00:00',-1,1);
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1,1);
INSERT INTO TABLE ver_collpase_table VALUES('A000',102,'2019-02-20 00:00:00',1,2);
select * from ver_collpase_table;
optimize table ver_collpase_table FINAL;
select * from ver_collpase_table;
· 上述操作,数据均能够按照正常预期被折叠。
8.7 各种MergeTree之间的关系总结
8.7.1 继承关系
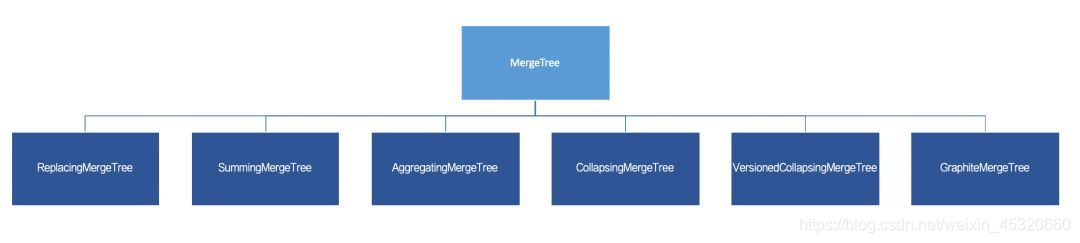
通过最基础的MergeTree表引擎,向下派生出6个变种表引擎,如下图所示
在ClickHouse底层具体的实现方法中,上述7种表引擎的区别主要体现在Merge合并的逻辑部分。如下图所示,是简化后的对象关系:
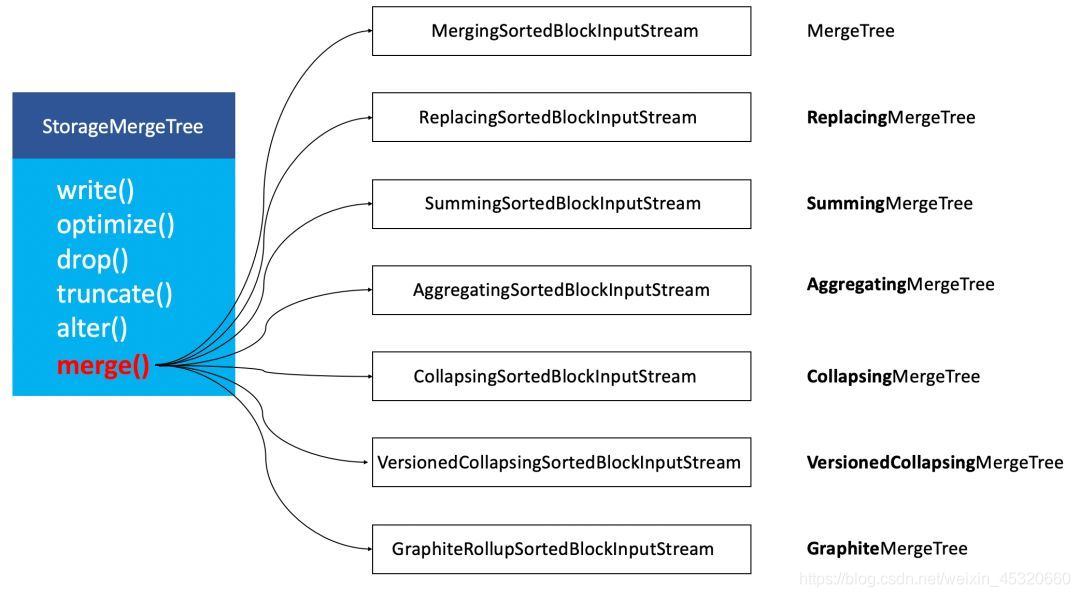
可以看到,在具体的实现逻辑部分,7种MergeTree共用一个主体,在触发Merge动作时,调用了各自独有的合并逻辑。
而除开MergeTree之外的其他6个变种表引擎,它们的Merge合并逻辑,全部是建立在MergeTree基础之上的,如下图所示:
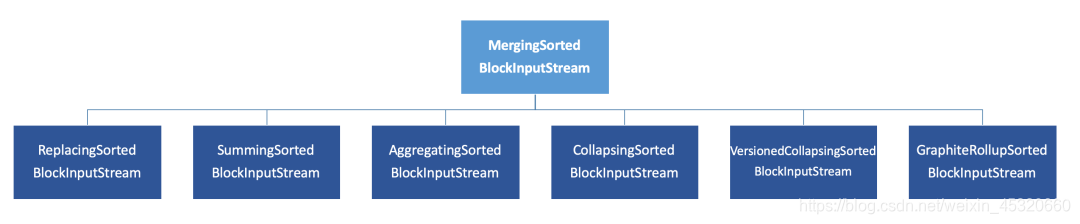
Merging**SortedBlockInputStream 的主要作用,是按照ORDER BY的规则保持新分区数据的有序性。
而其他6种变种MergeTree的合并逻辑,则是在有序的基础之上 “各有所长”,要么是将排序后相邻的重复数据消除、亦或是将它们累加汇总。
所以,从继承关系的角度这7种MergeTree的关系,也进一步明确了一个事实,它们的主要区别在Merge部分的逻辑,所以特殊功能只会在Merge合并时才会触发。
8.7.2 组合关系
ReplicatedMergeTree与普通的MergeTree又有什么区别呢? 如下图:
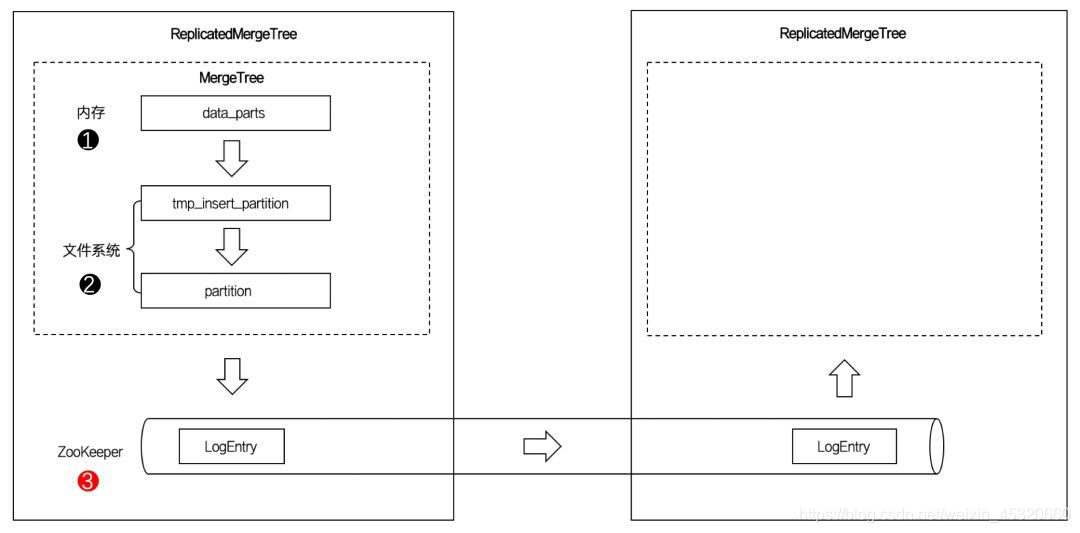
图中的虚线框部分是MergeTree的能力边界,而ReplicatedMergeTree在它的基础之上增加了分布式协同的能力。
借助ZooKeeper的消息日志广播,实现了副本实例之间的数据同步功能。
ReplicatedMergeTree系列可以用组合关系来理解,如下图所示:

当我们为7种MergeTree加上Replicated前缀后,又能组合出7种新的表引擎,这些ReplicatedMergeTree拥有副本协同的能力。
更多精彩内容,请关注微信公众号获取
