【clickhouse系列】ClickHouse入门
1、官方文档 猛戳这里
2、ClickHouse入门指北 猛戳这里---------这个很重要,下面写的很多东西都来自于这个文档的理论基础。
3、ClickHouse源码 猛戳这里---------c++写的,暂时还没时间看(其实主要是因为看也看不懂)
4、本地安装或集群安装–详见后面【clickhouse系列】clickhouse安装和使用 的部分
5、以下教程默认大家有简单mysql语法基础,重点放在和mysql区别的部分。
一、what is clickhouse?
-
clickhouse 诞生于俄罗斯最大的搜索公司Yandex,在clickhouse的配置文件中我们也会看到yandex的影子。
-
clickhouse 是面向联机分析处理(OLAP, On-Line Analytical Processing) 的分布式列式数据库管理系统(DBMS),在数据分析中能提供高性能的查询服务。
-
clickhouse的优点是快、非常快、特别快,缺点是query不好写不好维护。
-
用于对干净,结构良好且不可变的事件或日志进行分析。
-
…
-
说明:在一个 “常规” 的行式数据库管理系统中,数据按下面的顺序存储:
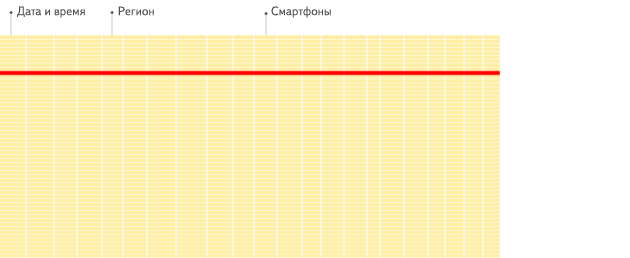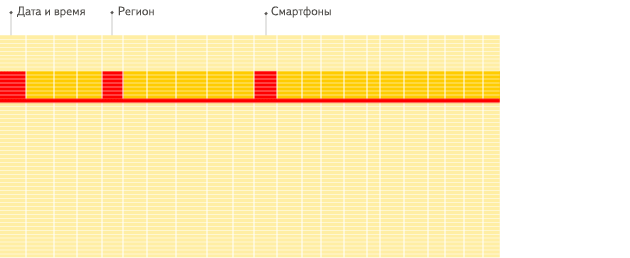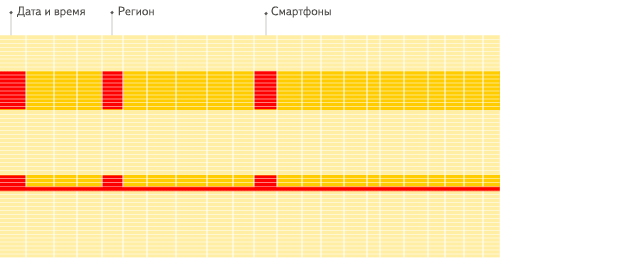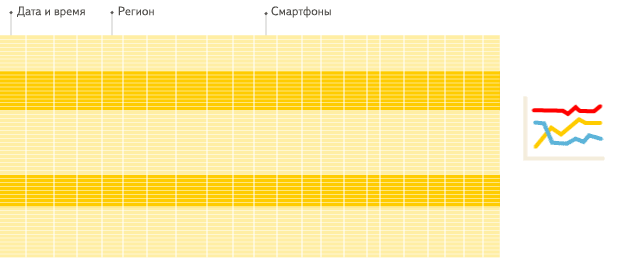
行式存储的的数据库管理系统有:MySQL, Postgres, MS SQL Server 等。 -
在一个列式存储数据库管理系统中,数据存储的方式如下所示:
常见的列式数据库有: Vertica、 Paraccel (Actian Matrix,Amazon Redshift)、 Sybase IQ、 Exasol、 Infobright、 InfiniDB、 MonetDB (VectorWise, Actian Vector)、 LucidDB、 SAP HANA、 Google Dremel、 Google PowerDrill、 Druid、 kdb+。
二、clickhouse的特性
- 真正的列式数据库管理系统
- 数据压缩
- 数据的磁盘存储
- 多核心并行处理
- 多服务器分布式处理
- 支持SQL
- 向量引擎
- 实时的数据更新
- 索引
- 适合在线查询
- 支持近似计算
- 支持数据复制和数据完整性
- …
- 一些缺点:
- 没有完整的事物支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
三、when use clickhouse?
- Web和App分析
- 广告网络和RTB
- 电信
- 电子商务和金融
- 信息安全
- 监测和遥测
- 时间序列
- 商业智能
- 线上游戏
- 物联网
- 事务性工作负载(OLTP)
- 高请求率的键值访问
- Blob或文档存储
- 超标准化的数据
- …
四、基础知识
-
数据类型----下面只写了一种数据类型,其他参考官方入门文档
ClickHouse 可以在数据表中存储多种数据类型。
UInt8, UInt16, UInt32, UInt64, Int8, Int16, Int32, Int64 固定长度的整型,包括有符号整型或无符号整型。
(1) 整型范围Int8 - [-128 : 127] Int16 - [-32768 : 32767] Int32 - [-2147483648 : 2147483647] Int64 - [-9223372036854775808 : 9223372036854775807](2) 无符号整型范围
UInt8 - [0 : 255] UInt16 - [0 : 65535] UInt32 - [0 : 4294967295] UInt64 - [0 : 18446744073709551615] -
sql语法----详见官方入门文档
SELECT 查询语法
SELECT 查询语法
SELECT 语句用于执行数据的检索
SELECT [DISTINCT] expr_list
[FROM [db.]table | (subquery) | table_function] [FINAL]
[SAMPLE sample_coeff]
[ARRAY JOIN ...]
[GLOBAL] ANY|ALL INNER|LEFT JOIN (subquery)|table USING columns_list
[PREWHERE expr]
[WHERE expr]
[GROUP BY expr_list] [WITH TOTALS]
[HAVING expr]
[ORDER BY expr_list]
[LIMIT [n, ]m]
[UNION ALL ...]
[INTO OUTFILE filename]
[FORMAT format]
[LIMIT n BY columns]
所有的子句都是可选的,除了SELECT之后的表达式列表(expr_list)。 下面将按照查询运行的顺序逐一对各个子句进行说明。
如果查询中不包含DISTINCT,GROUP BY,ORDER BY子句以及IN和JOIN子查询,那么它将仅使用O(1)数量的内存来完全流式的处理查询 否则,这个查询将消耗大量的内存,除非你指定了这些系统配置:max_memory_usage, max_rows_to_group_by, max_rows_to_sort, max_rows_in_distinct, max_bytes_in_distinct, max_rows_in_set, max_bytes_in_set, max_rows_in_join, max_bytes_in_join, max_bytes_before_external_sort, max_bytes_before_external_group_by。它们规定了可以使用外部排序(将临时表存储到磁盘中)以及外部聚合,目前系统不存在关于Join的配置,更多关于它们的信息,可以参见“配置”部分。
FROM 子句
如果查询中不包含FROM子句,那么将读取system.one。 system.one中仅包含一行数据(此表实现了与其他数据库管理系统中的DUAL相同的功能)。
FROM子句规定了将从哪个表、或子查询、或表函数中读取数据;同时ARRAY JOIN子句和JOIN子句也可以出现在这里(见后文)。
可以使用包含在括号里的子查询来替代表。 在这种情况下,子查询的处理将会构建在外部的查询内部。 不同于SQL标准,子查询后无需指定别名。为了兼容,你可以在子查询后添加‘AS 别名’,但是指定的名字不能被使用在任何地方。
也可以使用表函数来代替表,有关信息,参见“表函数”。
执行查询时,在查询中列出的所有列都将从对应的表中提取数据;如果你使用的是子查询的方式,则任何在外部查询中没有使用的列,子查询将从查询中忽略它们; 如果你的查询没有列出任何的列(例如,SELECT count() FROM t),则将额外的从表中提取一些列(最好的情况下是最小的列),以便计算行数。
最后的FINAL修饰符仅能够被使用在SELECT from CollapsingMergeTree场景中。当你为FROM指定了FINAL修饰符时,你的查询结果将会在查询过程中被聚合。需要注意的是,在这种情况下,查询将在单个流中读取所有相关的主键列,同时对需要的数据进行合并。这意味着,当使用FINAL修饰符时,查询将会处理的更慢。在大多数情况下,你应该避免使用FINAL修饰符。更多信息,请参阅“CollapsingMergeTree引擎”部分。
SAMPLE 子句
通过SAMPLE子句用户可以进行近似查询处理,近似查询处理仅能工作在MergeTree*类型的表中,并且在创建表时需要您指定采样表达式(参见“MergeTree 引擎”部分)。
SAMPLE子句可以使用SAMPLE k来表示,其中k可以是0到1的小数值,或者是一个足够大的正整数值。
当k为0到1的小数时,查询将使用'k'作为百分比选取数据。例如,SAMPLE 0.1查询只会检索数据总量的10%。 当k为一个足够大的正整数时,查询将使用'k'作为最大样本数。例如, SAMPLE 10000000查询只会检索最多10,000,000行数据。
Example:
SELECT
Title,
count() * 10 AS PageViews
FROM hits_distributed
SAMPLE 0.1
WHERE
CounterID = 34
AND toDate(EventDate) >= toDate('2013-01-29')
AND toDate(EventDate) <= toDate('2013-02-04')
AND NOT DontCountHits
AND NOT Refresh
AND Title != ''
GROUP BY Title
ORDER BY PageViews DESC LIMIT 1000;
在这个例子中,查询将检索数据总量的0.1 (10%)的数据。值得注意的是,查询不会自动校正聚合函数最终的结果,所以为了得到更加精确的结果,需要将count()的结果手动乘以10。
当使用像SAMPLE 10000000这样的方式进行近似查询时,由于没有了任何关于将会处理了哪些数据或聚合函数应该被乘以几的信息,所以这种方式不适合在这种场景下使用。
使用相同的采样率得到的结果总是一致的:如果我们能够看到所有可能存在在表中的数据,那么相同的采样率总是能够得到相同的结果(在建表时使用相同的采样表达式),换句话说,系统在不同的时间,不同的服务器,不同表上总以相同的方式对数据进行采样。
例如,我们可以使用采样的方式获取到与不进行采样相同的用户ID的列表。这将表明,你可以在IN子查询中使用采样,或者使用采样的结果与其他查询进行关联。
ARRAY JOIN 子句
ARRAY JOIN子句可以帮助查询进行与数组和nested数据类型的连接。它有点类似arrayJoin函数,但它的功能更广泛。
ARRAY JOIN 本质上等同于INNERT JOIN数组。 例如:
:) CREATE TABLE arrays_test (s String, arr Array(UInt8)) ENGINE = Memory
CREATE TABLE arrays_test
(
s String,
arr Array(UInt8)
) ENGINE = Memory
Ok.
0 rows in set. Elapsed: 0.001 sec.
:) INSERT INTO arrays_test VALUES ('Hello', [1,2]), ('World', [3,4,5]), ('Goodbye', [])
INSERT INTO arrays_test VALUES
Ok.
3 rows in set. Elapsed: 0.001 sec.
:) SELECT * FROM arrays_test
SELECT *
FROM arrays_test
┌─s───────┬─arr─────┐
│ Hello │ [1,2] │
│ World │ [3,4,5] │
│ Goodbye │ [] │
└─────────┴─────────┘
3 rows in set. Elapsed: 0.001 sec.
:) SELECT s, arr FROM arrays_test ARRAY JOIN arr
SELECT s, arr
FROM arrays_test
ARRAY JOIN arr
┌─s─────┬─arr─┐
│ Hello │ 1 │
│ Hello │ 2 │
│ World │ 3 │
│ World │ 4 │
│ World │ 5 │
└───────┴─────┘
5 rows in set. Elapsed: 0.001 sec.
你还可以为ARRAY JOIN子句指定一个别名,这时你可以通过这个别名来访问数组中的数据,但是数据本身仍然可以通过原来的名称进行访问。例如:
:) SELECT s, arr, a FROM arrays_test ARRAY JOIN arr AS a
SELECT s, arr, a
FROM arrays_test
ARRAY JOIN arr AS a
┌─s─────┬─arr─────┬─a─┐
│ Hello │ [1,2] │ 1 │
│ Hello │ [1,2] │ 2 │
│ World │ [3,4,5] │ 3 │
│ World │ [3,4,5] │ 4 │
│ World │ [3,4,5] │ 5 │
└───────┴─────────┴───┘
5 rows in set. Elapsed: 0.001 sec.
当多个具有相同大小的数组使用逗号分割出现在ARRAY JOIN子句中时,ARRAY JOIN会将它们同时执行(直接合并,而不是它们的笛卡尔积)。例如:
:) SELECT s, arr, a, num, mapped FROM arrays_test ARRAY JOIN arr AS a, arrayEnumerate(arr) AS num, arrayMap(x -> x + 1, arr) AS mapped
SELECT s, arr, a, num, mapped
FROM arrays_test
ARRAY JOIN arr AS a, arrayEnumerate(arr) AS num, arrayMap(lambda(tuple(x), plus(x, 1)), arr) AS mapped
┌─s─────┬─arr─────┬─a─┬─num─┬─mapped─┐
│ Hello │ [1,2] │ 1 │ 1 │ 2 │
│ Hello │ [1,2] │ 2 │ 2 │ 3 │
│ World │ [3,4,5] │ 3 │ 1 │ 4 │
│ World │ [3,4,5] │ 4 │ 2 │ 5 │
│ World │ [3,4,5] │ 5 │ 3 │ 6 │
└───────┴─────────┴───┴─────┴────────┘
5 rows in set. Elapsed: 0.002 sec.
:) SELECT s, arr, a, num, arrayEnumerate(arr) FROM arrays_test ARRAY JOIN arr AS a, arrayEnumerate(arr) AS num
SELECT s, arr, a, num, arrayEnumerate(arr)
FROM arrays_test
ARRAY JOIN arr AS a, arrayEnumerate(arr) AS num
┌─s─────┬─arr─────┬─a─┬─num─┬─arrayEnumerate(arr)─┐
│ Hello │ [1,2] │ 1 │ 1 │ [1,2] │
│ Hello │ [1,2] │ 2 │ 2 │ [1,2] │
│ World │ [3,4,5] │ 3 │ 1 │ [1,2,3] │
│ World │ [3,4,5] │ 4 │ 2 │ [1,2,3] │
│ World │ [3,4,5] │ 5 │ 3 │ [1,2,3] │
└───────┴─────────┴───┴─────┴─────────────────────┘
5 rows in set. Elapsed: 0.002 sec.
另外ARRAY JOIN也可以工作在nested数据结构上。例如:
:) CREATE TABLE nested_test (s String, nest Nested(x UInt8, y UInt32)) ENGINE = Memory
CREATE TABLE nested_test
(
s String,
nest Nested(
x UInt8,
y UInt32)
) ENGINE = Memory
Ok.
0 rows in set. Elapsed: 0.006 sec.
:) INSERT INTO nested_test VALUES ('Hello', [1,2], [10,20]), ('World', [3,4,5], [30,40,50]), ('Goodbye', [], [])
INSERT INTO nested_test VALUES
Ok.
3 rows in set. Elapsed: 0.001 sec.
:) SELECT * FROM nested_test
SELECT *
FROM nested_test
┌─s───────┬─nest.x──┬─nest.y─────┐
│ Hello │ [1,2] │ [10,20] │
│ World │ [3,4,5] │ [30,40,50] │
│ Goodbye │ [] │ [] │
└─────────┴─────────┴────────────┘
3 rows in set. Elapsed: 0.001 sec.
:) SELECT s, nest.x, nest.y FROM nested_test ARRAY JOIN nest
SELECT s, `nest.x`, `nest.y`
FROM nested_test
ARRAY JOIN nest
┌─s─────┬─nest.x─┬─nest.y─┐
│ Hello │ 1 │ 10 │
│ Hello │ 2 │ 20 │
│ World │ 3 │ 30 │
│ World │ 4 │ 40 │
│ World │ 5 │ 50 │
└───────┴────────┴────────┘
5 rows in set. Elapsed: 0.001 sec.
当你在ARRAY JOIN指定nested数据类型的名称时,其作用与与包含所有数组元素的ARRAY JOIN相同,例如:
:) SELECT s, nest.x, nest.y FROM nested_test ARRAY JOIN nest.x, nest.y
SELECT s, `nest.x`, `nest.y`
FROM nested_test
ARRAY JOIN `nest.x`, `nest.y`
┌─s─────┬─nest.x─┬─nest.y─┐
│ Hello │ 1 │ 10 │
│ Hello │ 2 │ 20 │
│ World │ 3 │ 30 │
│ World │ 4 │ 40 │
│ World │ 5 │ 50 │
└───────┴────────┴────────┘
5 rows in set. Elapsed: 0.001 sec.
这种方式也是可以运行的:
:) SELECT s, nest.x, nest.y FROM nested_test ARRAY JOIN nest.x
SELECT s, `nest.x`, `nest.y`
FROM nested_test
ARRAY JOIN `nest.x`
┌─s─────┬─nest.x─┬─nest.y─────┐
│ Hello │ 1 │ [10,20] │
│ Hello │ 2 │ [10,20] │
│ World │ 3 │ [30,40,50] │
│ World │ 4 │ [30,40,50] │
│ World │ 5 │ [30,40,50] │
└───────┴────────┴────────────┘
5 rows in set. Elapsed: 0.001 sec.
为了方便使用原来的nested类型的数组,你可以为nested类型定义一个别名。例如:
:) SELECT s, n.x, n.y, nest.x, nest.y FROM nested_test ARRAY JOIN nest AS n
SELECT s, `n.x`, `n.y`, `nest.x`, `nest.y`
FROM nested_test
ARRAY JOIN nest AS n
┌─s─────┬─n.x─┬─n.y─┬─nest.x──┬─nest.y─────┐
│ Hello │ 1 │ 10 │ [1,2] │ [10,20] │
│ Hello │ 2 │ 20 │ [1,2] │ [10,20] │
│ World │ 3 │ 30 │ [3,4,5] │ [30,40,50] │
│ World │ 4 │ 40 │ [3,4,5] │ [30,40,50] │
│ World │ 5 │ 50 │ [3,4,5] │ [30,40,50] │
└───────┴─────┴─────┴─────────┴────────────┘
5 rows in set. Elapsed: 0.001 sec.
使用arrayEnumerate函数的示例:
:) SELECT s, n.x, n.y, nest.x, nest.y, num FROM nested_test ARRAY JOIN nest AS n, arrayEnumerate(nest.x) AS num
SELECT s, `n.x`, `n.y`, `nest.x`, `nest.y`, num
FROM nested_test
ARRAY JOIN nest AS n, arrayEnumerate(`nest.x`) AS num
┌─s─────┬─n.x─┬─n.y─┬─nest.x──┬─nest.y─────┬─num─┐
│ Hello │ 1 │ 10 │ [1,2] │ [10,20] │ 1 │
│ Hello │ 2 │ 20 │ [1,2] │ [10,20] │ 2 │
│ World │ 3 │ 30 │ [3,4,5] │ [30,40,50] │ 1 │
│ World │ 4 │ 40 │ [3,4,5] │ [30,40,50] │ 2 │
│ World │ 5 │ 50 │ [3,4,5] │ [30,40,50] │ 3 │
└───────┴─────┴─────┴─────────┴────────────┴─────┘
5 rows in set. Elapsed: 0.002 sec.
在一个查询中只能出现一个ARRAY JOIN子句。
如果在WHERE/PREWHERE子句中使用了ARRAY JOIN子句的结果,它将优先于WHERE/PREWHERE子句执行,否则它将在WHERE/PRWHERE子句之后执行,以便减少计算。
JOIN 子句
JOIN子句用于连接数据,作用与SQL JOIN的定义相同。
注意
与 ARRAY JOIN 没有关系.
SELECT <expr_list>
FROM <left_subquery>
[GLOBAL] [ANY|ALL] INNER|LEFT|RIGHT|FULL|CROSS [OUTER] JOIN <right_subquery>
(ON <expr_list>)|(USING <column_list>) ...
可以使用具体的表名来代替<left_subquery>与<right_subquery>。但这与使用SELECT * FROM table子查询的方式相同。除非你的表是[Join](../operations/table_engines/join.md 支持的JOIN类型
INNER JOIN
LEFT OUTER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
CROSS JOIN
你可以跳过默认的OUTER关键字。
ANY 与 ALL
在使用ALL修饰符对JOIN进行修饰时,如果右表中存在多个与左表关联的数据,那么系统则将右表中所有可以与左表关联的数据全部返回在结果中。这与SQL标准的JOIN行为相同。 在使用ANY修饰符对JOIN进行修饰时,如果右表中存在多个与左表关联的数据,那么系统仅返回第一个与左表匹配的结果。如果左表与右表一一对应,不存在多余的行时,ANY与ALL的结果相同。
你可以在会话中通过设置 join_default_strictness 来指定默认的JOIN修饰符。
GLOBAL distribution
当使用普通的JOIN时,查询将被发送给远程的服务器。并在这些远程服务器上生成右表并与它们关联。换句话说,右表来自于各个服务器本身。
当使用GLOBAL ... JOIN,首先会在请求服务器上计算右表并以临时表的方式将其发送到所有服务器。这时每台服务器将直接使用它进行计算。
使用GLOBAL时需要小心。更多信息,参阅 Distributed subqueries 部分。
使用建议
从子查询中删除所有JOIN不需要的列。
当执行JOIN查询时,因为与其他阶段相比没有进行执行顺序的优化:JOIN优先于WHERE与聚合执行。因此,为了显示的指定执行顺序,我们推荐你使用子查询的方式执行JOIN。
示例:
SELECT
CounterID,
hits,
visits
FROM
(
SELECT
CounterID,
count() AS hits
FROM test.hits
GROUP BY CounterID
) ANY LEFT JOIN
(
SELECT
CounterID,
sum(Sign) AS visits
FROM test.visits
GROUP BY CounterID
) USING CounterID
ORDER BY hits DESC
LIMIT 10
┌─CounterID─┬───hits─┬─visits─┐
│ 1143050 │ 523264 │ 13665 │
│ 731962 │ 475698 │ 102716 │
│ 722545 │ 337212 │ 108187 │
│ 722889 │ 252197 │ 10547 │
│ 2237260 │ 196036 │ 9522 │
│ 23057320 │ 147211 │ 7689 │
│ 722818 │ 90109 │ 17847 │
│ 48221 │ 85379 │ 4652 │
│ 19762435 │ 77807 │ 7026 │
│ 722884 │ 77492 │ 11056 │
└───────────┴────────┴────────┘
子查询不允许您设置别名或在其他地方引用它们。 USING中指定的列必须在两个子查询中具有相同的名称,而其他列必须具有不同的名称。您可以通过使用别名的方式来更改子查询中的列名(示例中就分别使用了'hits'与'visits'别名)。
USING子句用于指定要进行链接的一个或多个列,系统会将这些列在两张表中相等的值连接起来。如果列是一个列表,不需要使用括号包裹。同时JOIN不支持其他更复杂的Join方式。
右表(子查询的结果)将会保存在内存中。如果没有足够的内存,则无法运行JOIN。
只能在查询中指定一个JOIN。若要运行多个JOIN,你可以将它们放入子查询中。
每次运行相同的JOIN查询,总是会再次计算 - 没有缓存结果。 为了避免这种情况,可以使用‘Join’引擎,它是一个预处理的Join数据结构,总是保存在内存中。更多信息,参见“Join引擎”部分。
在一些场景下,使用IN代替JOIN将会得到更高的效率。在各种类型的JOIN中,最高效的是ANY LEFT JOIN,然后是ANY INNER JOIN,效率最差的是ALL LEFT JOIN以及ALL INNER JOIN。
如果你需要使用JOIN来关联一些纬度表(包含纬度属性的一些相对比较小的表,例如广告活动的名称),那么JOIN可能不是好的选择,因为语法负责,并且每次查询都将重新访问这些表。对于这种情况,您应该使用“外部字典”的功能来替换JOIN。更多信息,参见 外部字典 部分。
Null的处理
JOIN的行为受 join_use_nulls 的影响。当join_use_nulls=1时,JOIN的工作与SQL标准相同。
如果JOIN的key是 Nullable 类型的字段,则其中至少一个存在 NULL 值的key不会被关联。
WHERE 子句
如果存在WHERE子句, 则在该子句中必须包含一个UInt8类型的表达式。 这个表达是通常是一个带有比较和逻辑的表达式。 这个表达式将会在所有数据转换前用来过滤数据。
如果在支持索引的数据库表引擎中,这个表达式将被评估是否使用索引。
PREWHERE 子句
这个子句与WHERE子句的意思相同。主要的不同之处在于表数据的读取。 当使用PREWHERE时,首先只读取PREWHERE表达式中需要的列。然后在根据PREWHERE执行的结果读取其他需要的列。
如果在过滤条件中有少量不适合索引过滤的列,但是它们又可以提供很强的过滤能力。这时使用PREWHERE是有意义的,因为它将帮助减少数据的读取。
例如,在一个需要提取大量列的查询中为少部分列编写PREWHERE是很有作用的。
PREWHERE 仅支持*MergeTree系列引擎。
在一个查询中可以同时指定PREWHERE和WHERE,在这种情况下,PREWHERE优先于WHERE执行。
值得注意的是,PREWHERE不适合用于已经存在于索引中的列,因为当列已经存在于索引中的情况下,只有满足索引的数据块才会被读取。
如果将'optimize_move_to_prewhere'设置为1,并且在查询中不包含PREWHERE,则系统将自动的把适合PREWHERE表达式的部分从WHERE中抽离到PREWHERE中。
GROUP BY 子句
这是列式数据库管理系统中最重要的一部分。
如果存在GROUP BY子句,则在该子句中必须包含一个表达式列表。其中每个表达式将会被称之为“key”。 SELECT,HAVING,ORDER BY子句中的表达式列表必须来自于这些“key”或聚合函数。简而言之,被选择的列中不能包含非聚合函数或key之外的其他列。
如果查询表达式列表中仅包含聚合函数,则可以省略GROUP BY子句,这时会假定将所有数据聚合成一组空“key”。
Example:
SELECT
count(),
median(FetchTiming > 60 ? 60 : FetchTiming),
count() - sum(Refresh)
FROM hits
与SQL标准不同的是,如果表中不存在任何数据(可能表本身中就不存在任何数据,或者由于被WHERE条件过滤掉了),将返回一个空结果,而不是一个包含聚合函数初始值的结果。
与MySQL不同的是(实际上这是符合SQL标准的),你不能够获得一个不在key中的非聚合函数列(除了常量表达式)。但是你可以使用‘any’(返回遇到的第一个值)、max、min等聚合函数使它工作。
Example:
SELECT
domainWithoutWWW(URL) AS domain,
count(),
any(Title) AS title -- getting the first occurred page header for each domain.
FROM hits
GROUP BY domain
GROUP BY子句会为遇到的每一个不同的key计算一组聚合函数的值。
在GROUP BY子句中不支持使用Array类型的列。
常量不能作为聚合函数的参数传入聚合函数中。例如: sum(1)。这种情况下你可以省略常量。例如:count()。
NULL 处理
对于GROUP BY子句,ClickHouse将 NULL 解释为一个值,并且支持NULL=NULL。
下面这个例子将说明这将意味着什么。
假设你有这样一张表:
┌─x─┬────y─┐
│ 1 │ 2 │
│ 2 │ ᴺᵁᴸᴸ │
│ 3 │ 2 │
│ 3 │ 3 │
│ 3 │ ᴺᵁᴸᴸ │
└───┴──────┘
运行SELECT sum(x), y FROM t_null_big GROUP BY y你将得到如下结果:
┌─sum(x)─┬────y─┐
│ 4 │ 2 │
│ 3 │ 3 │
│ 5 │ ᴺᵁᴸᴸ │
└────────┴──────┘
你可以看到GROUP BY为y=NULL的聚合了x。
如果你在向GROUP BY中放入几个key,结果将列出所有的组合可能。就像NULL是一个特定的值一样。
WITH TOTALS 修饰符
如果你指定了WITH TOTALS修饰符,你将会在结果中得到一个被额外计算出的行。在这一行中将包含所有key的默认值(零或者空值),以及所有聚合函数对所有被选择数据行的聚合结果。
该行仅在JSON*, TabSeparated*, Pretty*输出格式中与其他行分开输出。
在JSON*输出格式中,这行将出现在Json的‘totals’字段中。在TabSeparated*输出格式中,这行将位于其他结果之后,同时与其他结果使用空白行分隔。在Pretty*输出格式中,这行将作为单独的表在所有结果之后输出。
当WITH TOTALS与HAVING子句同时存在时,它的行为受‘totals_mode’配置的影响。 默认情况下,totals_mode = 'before_having',这时WITH TOTALS将会在HAVING前计算最多不超过max_rows_to_group_by行的数据。
在group_by_overflow_mode = 'any'并指定了max_rows_to_group_by的情况下,WITH TOTALS的行为受totals_mode的影响。
after_having_exclusive - 在HAVING后进行计算,计算不超过max_rows_to_group_by行的数据。
after_having_inclusive - 在HAVING后进行计算,计算不少于max_rows_to_group_by行的数据。
after_having_auto - 在HAVING后进行计算,采用统计通过HAVING的行数,在超过不超过‘max_rows_to_group_by’指定值(默认为50%)的情况下,包含所有行的结果。否则排除这些结果。
totals_auto_threshold - 默认 0.5,是after_having_auto的参数。
如果group_by_overflow_mode != 'any'并没有指定max_rows_to_group_by情况下,所有的模式都与after_having相同。
你可以在子查询,包含子查询的JOIN子句中使用WITH TOTALS(在这种情况下,它们各自的总值会被组合在一起)。
GROUP BY 使用外部存储设备
你可以在GROUP BY中允许将临时数据转存到磁盘上,以限制对内存的使用。 max_bytes_before_external_group_by这个配置确定了在GROUP BY中启动将临时数据转存到磁盘上的内存阈值。如果你将它设置为0(这是默认值),这项功能将被禁用。
当使用max_bytes_before_external_group_by时,我们建议将max_memory_usage设置为它的两倍。这是因为一个聚合需要两个阶段来完成:(1)读取数据并形成中间数据 (2)合并中间数据。临时数据的转存只会发生在第一个阶段。如果没有发生临时文件的转存,那么阶段二将最多消耗与1阶段相同的内存大小。
例如:如果将max_memory_usage设置为10000000000并且你想要开启外部聚合,那么你需要将max_bytes_before_external_group_by设置为10000000000的同时将max_memory_usage设置为20000000000。当外部聚合被触发时(如果刚好只形成了一份临时数据),它的内存使用量将会稍高与max_bytes_before_external_group_by。
在分布式查询处理中,外部聚合将会在远程的服务器中执行。为了使请求服务器只使用较少的内存,可以设置distributed_aggregation_memory_efficient为1。
当合并被刷到磁盘的临时数据以及合并远程的服务器返回的结果时,如果在启动distributed_aggregation_memory_efficient的情况下,将会消耗1/256 * 线程数的总内存大小。
当启动外部聚合时,如果数据的大小小于max_bytes_before_external_group_by设置的值(数据没有被刷到磁盘中),那么数据的聚合速度将会和没有启动外部聚合时一样快。如果有临时数据被刷到了磁盘中,那么这个查询的运行时间将会被延长几倍(大约是3倍)。
如果你在GROUP BY后面存在ORDER BY子句,并且ORDER BY后面存在一个极小限制的LIMIT,那么ORDER BY子句将不会使用太多内存。 否则请不要忘记启动外部排序(max_bytes_before_external_sort)。
LIMIT N BY 子句
LIMIT N BY子句和LIMIT没有关系, LIMIT N BY COLUMNS 子句可以用来在每一个COLUMNS分组中求得最大的N行数据。我们可以将它们同时用在一个查询中。LIMIT N BY子句中可以包含任意多个分组字段表达式列表。
示例:
SELECT
domainWithoutWWW(URL) AS domain,
domainWithoutWWW(REFERRER_URL) AS referrer,
device_type,
count() cnt
FROM hits
GROUP BY domain, referrer, device_type
ORDER BY cnt DESC
LIMIT 5 BY domain, device_type
LIMIT 100
查询将会为每个domain, device_type的组合选出前5个访问最多的数据,但是结果最多将不超过100行(LIMIT n BY + LIMIT)。
HAVING 子句
HAVING子句可以用来过滤GROUP BY之后的数据,类似于WHERE子句。 WHERE于HAVING不同之处在于WHERE在聚合前(GROUP BY)执行,HAVING在聚合后执行。 如果不存在聚合,则不能使用HAVING。
ORDER BY 子句
如果存在ORDER BY 子句,则该子句中必须存在一个表达式列表,表达式列表中每一个表达式都可以分配一个DESC或ASC(排序的方向)。如果没有指明排序的方向,将假定以ASC的方式进行排序。其中ASC表示按照升序排序,DESC按照降序排序。示例:ORDER BY Visits DESC, SearchPhrase
对于字符串的排序来讲,你可以为其指定一个排序规则,在指定排序规则时,排序总是不会区分大小写。并且如果与ASC或DESC同时出现时,排序规则必须在它们的后面指定。例如:ORDER BY SearchPhrase COLLATE 'tr' - 使用土耳其字母表对它进行升序排序,同时排序时不会区分大小写,并按照UTF-8字符集进行编码。
我们推荐只在少量的数据集中使用COLLATE,因为COLLATE的效率远低于正常的字节排序。
针对排序表达式中相同值的行将以任意的顺序进行输出,这是不确定的(每次都可能不同)。 如果省略ORDER BY子句,则结果的顺序也是不固定的。
NaN 和 NULL 的排序规则:
当使用NULLS FIRST修饰符时,将会先输出NULL,然后是NaN,最后才是其他值。
当使用NULLS LAST修饰符时,将会先输出其他值,然后是NaN,最后才是NULL。
默认情况下与使用NULLS LAST修饰符相同。
示例:
假设存在如下一张表
┌─x─┬────y─┐
│ 1 │ ᴺᵁᴸᴸ │
│ 2 │ 2 │
│ 1 │ nan │
│ 2 │ 2 │
│ 3 │ 4 │
│ 5 │ 6 │
│ 6 │ nan │
│ 7 │ ᴺᵁᴸᴸ │
│ 6 │ 7 │
│ 8 │ 9 │
└───┴──────┘
运行查询 SELECT * FROM t_null_nan ORDER BY y NULLS FIRST 将获得如下结果:
┌─x─┬────y─┐
│ 1 │ ᴺᵁᴸᴸ │
│ 7 │ ᴺᵁᴸᴸ │
│ 1 │ nan │
│ 6 │ nan │
│ 2 │ 2 │
│ 2 │ 2 │
│ 3 │ 4 │
│ 5 │ 6 │
│ 6 │ 7 │
│ 8 │ 9 │
└───┴──────┘
当使用浮点类型的数值进行排序时,不管排序的顺序如何,NaNs总是出现在所有值的后面。换句话说,当你使用升序排列一个浮点数值列时,NaNs好像比所有值都要大。反之,当你使用降序排列一个浮点数值列时,NaNs好像比所有值都小。
如果你在ORDER BY子句后面存在LIMIT并给定了较小的数值,则将会使用较少的内存。否则,内存的使用量将与需要排序的数据成正比。对于分布式查询,如果省略了GROUP BY,则在远程服务器上执行部分排序,最后在请求服务器上合并排序结果。这意味这对于分布式查询而言,要排序的数据量可以大于单台服务器的内存。
如果没有足够的内存,可以使用外部排序(在磁盘中创建一些临时文件)。可以使用max_bytes_before_external_sort来设置外部排序,如果你讲它设置为0(默认),则表示禁用外部排序功能。如果启用该功能。当要排序的数据量达到所指定的字节数时,当前排序的结果会被转存到一个临时文件中去。当全部数据读取完毕后,所有的临时文件将会合并成最终输出结果。这些临时文件将会写到config文件配置的/var/lib/clickhouse/tmp/目录中(默认值,你可以通过修改'tmp_path'配置调整该目录的位置)。
查询运行使用的内存要高于‘max_bytes_before_external_sort’,为此,这个配置必须要远远小于‘max_memory_usage’配置的值。例如,如果你的服务器有128GB的内存去运行一个查询,那么推荐你将‘max_memory_usage’设置为100GB,‘max_bytes_before_external_sort’设置为80GB。
外部排序效率要远低于在内存中排序。
SELECT 子句
在完成上述列出的所有子句后,将对SELECT子句中的表达式进行分析。 具体来讲,如果在存在聚合函数的情况下,将对聚合函数之前的表达式进行分析。 聚合函数与聚合函数之前的表达式都将在聚合期间完成计算(GROUP BY)。 就像他们本身就已经存在结果上一样。
DISTINCT 子句
如果存在DISTINCT子句,则会对结果中的完全相同的行进行去重。 在GROUP BY不包含聚合函数,并对全部SELECT部分都包含在GROUP BY中时的作用一样。但该子句还是与GROUP BY子句存在以下几点不同:
可以与GROUP BY配合使用。
当不存在ORDER BY子句并存在LIMIT子句时,查询将在同时满足DISTINCT与LIMIT的情况下立即停止查询。
在处理数据的同时输出结果,并不是等待整个查询全部完成。
在SELECT表达式中存在Array类型的列时,不能使用DISTINCT。
DISTINCT可以与 NULL一起工作,就好像NULL仅是一个特殊的值一样,并且NULL=NULL。换而言之,在DISTINCT的结果中,与NULL不同的组合仅能出现一次。
LIMIT 子句
LIMIT m 用于在查询结果中选择前m行数据。 LIMIT n, m 用于在查询结果中选择从n行开始的m行数据。
‘n’与‘m’必须是正整数。
如果没有指定ORDER BY子句,则结果可能是任意的顺序,并且是不确定的。
UNION ALL 子句
UNION ALL子句可以组合任意数量的查询,例如:
SELECT CounterID, 1 AS table, toInt64(count()) AS c
FROM test.hits
GROUP BY CounterID
UNION ALL
SELECT CounterID, 2 AS table, sum(Sign) AS c
FROM test.visits
GROUP BY CounterID
HAVING c > 0
仅支持UNION ALL,不支持其他UNION规则(UNION DISTINCT)。如果你需要UNION DISTINCT,你可以使用UNION ALL中包含SELECT DISTINCT的子查询的方式。
UNION ALL中的查询可以同时运行,它们的结果将被混合到一起。
这些查询的结果结果必须相同(列的数量和类型)。列名可以是不同的。在这种情况下,最终结果的列名将从第一个查询中获取。UNION会为查询之间进行类型转换。例如,如果组合的两个查询中包含相同的字段,并且是类型兼容的Nullable和non-Nullable,则结果将会将该字段转换为Nullable类型的字段。
作为UNION ALL查询的部分不能包含在括号内。ORDER BY与LIMIT子句应该被应用在每个查询中,而不是最终的查询中。如果你需要做最终结果转换,你可以将UNION ALL作为一个子查询包含在FROM子句中。
INTO OUTFILE 子句
INTO OUTFILE filename 子句用于将查询结果重定向输出到指定文件中(filename是一个字符串类型的值)。 与MySQL不同,执行的结果文件将在客户端建立,如果文件已存在,查询将会失败。 此命令可以工作在命令行客户端与clickhouse-local中(通过HTTP借口发送将会失败)。
默认的输出格式是TabSeparated(与命令行客户端的批处理模式相同)。
FORMAT 子句
'FORMAT format' 子句用于指定返回数据的格式。 你可以使用它方便的转换或创建数据的转储。 更多信息,参见“输入输出格式”部分。 如果不存在FORMAT子句,则使用默认的格式,这将取决与DB的配置以及所使用的客户端。对于批量模式的HTTP客户端和命令行客户端而言,默认的格式是TabSeparated。对于交互模式下的命令行客户端,默认的格式是PrettyCompact(它有更加美观的格式)。
当使用命令行客户端时,数据以内部高效的格式在服务器和客户端之间进行传递。客户端将单独的解析FORMAT子句,以帮助数据格式的转换(这将减轻网络和服务器的负载)。
IN 运算符
对于IN、NOT IN、GLOBAL IN、GLOBAL NOT IN操作符被分别实现,因为它们的功能非常丰富。
运算符的左侧是单列或列的元组。
示例:
SELECT UserID IN (123, 456) FROM ...
SELECT (CounterID, UserID) IN ((34, 123), (101500, 456)) FROM ...
如果左侧是单个列并且是一个索引,并且右侧是一组常量时,系统将使用索引来处理查询。
不要在列表中列出太多的值(百万)。如果数据集很大,将它们放入临时表中(可以参考“”), 然后使用子查询。 Don\'t list too many values explicitly (i.e. millions). If a data set is large, put it in a temporary table (for example, see the section "External data for query processing"), then use a subquery.
右侧可以是一个由常量表达式组成的元组列表(像上面的例子一样),或者是一个数据库中的表的名称,或是一个包含在括号中的子查询。
如果右侧是一个表的名字(例如,UserID IN users),这相当于UserID IN (SELECT * FROM users)。在查询与外部数据表组合使用时可以使用该方法。例如,查询与包含user IDS的‘users’临时表一起被发送的同时需要对结果进行过滤时。
如果操作符的右侧是一个Set引擎的表时(数据总是在内存中准备好),则不会每次都为查询创建新的数据集。
子查询可以指定一个列以上的元组来进行过滤。 示例:
SELECT (CounterID, UserID) IN (SELECT CounterID, UserID FROM ...) FROM ...
IN操作符的左右两侧应具有相同的类型。
IN操作符的子查询中可以出现任意子句,包含聚合函数与lambda函数。 示例:
SELECT
EventDate,
avg(UserID IN
(
SELECT UserID
FROM test.hits
WHERE EventDate = toDate('2014-03-17')
)) AS ratio
FROM test.hits
GROUP BY EventDate
ORDER BY EventDate ASC
┌──EventDate─┬────ratio─┐
│ 2014-03-17 │ 1 │
│ 2014-03-18 │ 0.807696 │
│ 2014-03-19 │ 0.755406 │
│ 2014-03-20 │ 0.723218 │
│ 2014-03-21 │ 0.697021 │
│ 2014-03-22 │ 0.647851 │
│ 2014-03-23 │ 0.648416 │
└────────────┴──────────┘
为3月17日之后的每一天计算与3月17日访问该网站的用户浏览网页的百分比。 IN子句中的子查询仅在单个服务器上运行一次。不能够是相关子查询。
NULL 处理
在处理中,IN操作符总是假定 NULL 值的操作结果总是等于0,而不管NULL位于左侧还是右侧。NULL值不应该包含在任何数据集中,它们彼此不能够对应,并且不能够比较。
下面的示例中有一个t_null表:
┌─x─┬────y─┐
│ 1 │ ᴺᵁᴸᴸ │
│ 2 │ 3 │
└───┴──────┘
运行查询SELECT x FROM t_null WHERE y IN (NULL,3)将得到如下结果:
┌─x─┐
│ 2 │
└───┘
你可以看到在查询结果中不存在y = NULL的结果。这是因为ClickHouse无法确定NULL是否包含在(NULL,3)数据集中,对于这次比较操作返回了0,并且在SELECT的最终输出中排除了这行。
SELECT y IN (NULL, 3)
FROM t_null
┌─in(y, tuple(NULL, 3))─┐
│ 0 │
│ 1 │
└───────────────────────┘
分布式子查询
对于带有子查询的(类似与JOINs)IN中,有两种选择:普通的IN/JOIN与GLOBAL IN / GLOBAL JOIN。它们对于分布式查询的处理运行方式是不同的。
!!! 注意 请记住,下面描述的算法可能因为根据 settings 配置的不同而不同。
当使用普通的IN时,查询总是被发送到远程的服务器,并且在每个服务器中运行“IN”或“JOIN”子句中的子查询。
当使用GLOBAL IN / GLOBAL JOIN时,首先会为GLOBAL IN / GLOBAL JOIN运行所有子查询,并将结果收集到临时表中,并将临时表发送到每个远程服务器,并使用该临时表运行查询。
对于非分布式查询,请使用普通的IN / JOIN。
在分布式查询中使用IN / JOIN子句中使用子查询需要小心。
让我们来看一些例子。假设集群中的每个服务器都存在一个正常表local_table。与一个分布式表distributed_table。
对于所有查询distributed_table的查询,查询会被发送到所有的远程服务器并使用local_table表运行查询。
例如,查询
SELECT uniq(UserID) FROM distributed_table
将发送如下查询到所有远程服务器
SELECT uniq(UserID) FROM local_table
这时将并行的执行它们,直到达到可以组合数据的中间结果状态。然后中间结果将返回到请求服务器并在请求服务器上进行合并,最终将结果发送给客户端。
现在让我运行一个带有IN的查询:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
计算两个站点的用户交集。
此查询将被发送给所有的远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
换句话说,IN子句中的数据集将被在每台服务器上被独立的收集,仅与每台服务器上的本地存储上的数据计算交集。
如果您已经将数据分散到了集群的每台服务器上,并且单个UserID的数据完全分布在单个服务器上,那么这将是正确且最佳的查询方式。在这种情况下,所有需要的数据都可以在每台服务器的本地进行获取。否则,结果将是不准确的。我们将这种查询称为“local IN”。
为了修正这种在数据随机分布的集群中的工作,你可以在子查询中使用distributed_table。查询将更改为这样:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
此查询将被发送给所有的远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
子查询将在每个远程服务器上执行。因为子查询使用分布式表,所有每个远程服务器上的子查询将查询再次发送给所有的远程服务器
SELECT UserID FROM local_table WHERE CounterID = 34
例如,如果你拥有100台服务器的集群,执行整个查询将需要10,000次请求,这通常被认为是不可接受的。
在这种情况下,你应该使用GLOBAL IN来替代IN。让我们看一下它是如何工作的。
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID GLOBAL IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
在请求服务器上运行子查询
SELECT UserID FROM distributed_table WHERE CounterID = 34
将结果放入内存中的临时表中。然后将请求发送到每一台远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID GLOBAL IN _data1
临时表_data1也会随着查询一起发送到每一台远程服务器(临时表的名称由具体实现定义)。
这比使用普通的IN更加理想,但是,请注意以下几点:
创建临时表时,数据不是唯一的,为了减少通过网络传输的数据量,请在子查询中使用DISTINCT(你不需要在普通的IN中这么做)
临时表将发送到所有远程服务器。其中传输不考虑网络的拓扑结构。例如,如果你有10个远程服务器存在与请求服务器非常远的数据中心中,则数据将通过通道发送数据到远程数据中心10次。使用GLOBAL IN时应避免大数据集。
当向远程服务器发送数据时,网络带宽的限制是不可配置的,这可能会网络的负载造成压力。
尝试将数据跨服务器分布,这样你将不需要使用GLOBAL IN。
如果你需要经常使用GLOBAL IN,请规划你的ClickHouse集群位置,以便副本之间不存在跨数据中心,并且它们之间具有快速的网络交换能力,以便查询可以完全在一个数据中心内完成。
另外,在GLOBAL IN子句中使用本地表也是有用的,比如,本地表仅在请求服务器上可用,并且您希望在远程服务器上使用来自本地表的数据。
Extreme Values
除了结果外,你还可以获得结果列的最大值与最小值,可以将extremes配置设置成1来做到这一点。最大值最小值的计算是针对于数字类型,日期类型进行计算的,对于其他列,将会输出默认值。
额外计算的两行结果 - 最大值与最小值,这两行额外的结果仅在JSON*, TabSeparated*, and Pretty* 格式与其他行分开的输出方式输出,不支持其他输出格式。
在JSON*格式中,Extreme值在单独的'extremes'字段中。在TabSeparated*格式中,在其他结果与'totals'之后输出,并使用空行与其分隔。在Pretty* 格式中,将在其他结果与'totals'后以单独的表格输出。
如果在计算Extreme值的同时包含LIMIT。extremes的计算结果将包含offset跳过的行。在流式的请求中,它可能还包含多余LIMIT的少量行的值。
注意事项
不同于MySQL, GROUP BY与ORDER BY子句不支持使用列的位置信息作为参数,但这实际上是符合SQL标准的。 例如,GROUP BY 1, 2将被解释为按照常量进行分组(即,所有的行将会被聚合成一行)。
可以在查询的任何部分使用AS。
可以在查询的任何部分添加星号,而不仅仅是表达式。在分析查询时,星号被替换为所有的列(不包含MATERIALIZED与ALIAS的列)。 只有少数情况下使用星号是合理的:
创建表转储时。
对于仅包含几个列的表,如系统表.
获取表中的列信息。在这种情况下应该使用LIMIT 1。但是,更好的办法是使用DESC TABLE。
当使用PREWHERE在少数的几个列上做强过滤时。
在子查询中(因为外部查询不需要的列被排除在子查询之外)。
在所有的其他情况下,我们不建议使用星号,因为它是列式数据库的缺点而不是优点。
- 其他略–详见官方入门文档
五、一些需要说明的东西:
-
prewhere vs where
clickhouse是列数据库:
prewhere条件可以在取源数据的时候只取符合规则的数据到内存中,加快计算速度;
where是读入数据后,再在内存中找符合条件的,较慢,但where可以在join后,对合成的表起作用。 -
join
clickhouse的每个表只能join一次,如果需要join多个表,需要每次用select包裹一层。
基本用法为 :
all/any + inner/left/right/full outer + join table/(select …) using (column1, column2)
all join所有符合条件的行,
any join第一个遇到的符合条件的行;
using ()内是用于匹配的列,名字必须相同,括号不能省略(缺括号不会报错)。
我们找到一些技巧,减少join的层数:
用in:eg. uid in (select uid from xxxx)
clickhouse的in计算方式和mysql不同,速度很快。
用union all + group by + maxIf:
此外,有些表物理部署在不同机器上,比如nxlog.*,这些表用于join和in时,需要加关键字global,变为global join和global in。 -
常用统计函数
count() 计数
uniqExact(column) 统计唯一值单列
uniqExact(array(column1, column2)) = countDistinct(column1,column2) 统计唯一值多列组合
max() min() avg() sum() 字面意思
argMax(a,b) argMin() b最大、小时a的值
quantile(a)(x) x的a分位数,0<a<1
-If, eg. uniqExactIf(uid, 条件), 只统计符合条件的值
any() 任意,用于举例
arrayJoin() 可以把一行变为多行。