京东商品爬虫
从https://list.jd.com/list.html?cat=670%2C671%2C673&page=1&s=57&click=0站点进行商品图片爬虫
分别爬取手机,pad,笔记本和台式机商品图片各1万张
#爬虫代码
import re
import requests
from multiprocessing.pool import Pool
from lxml import etree
import time
#爬取每页商品图片url
def crawl(url, page):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
text = requests.get(url, headers=headers).text
html = etree.HTML(text)
img_urls = html.xpath("//div[@class='gl-i-wrap']/div[@class='p-img']/a/img/@data-lazy-img")
img_urls = list(map(lambda url: "http:" + url, img_urls))
return img_urls
#下载图片到本地方法
def download_img_multipro(img_down_param):
file_path = "./data/com_img/" + str(img_down_param[0]) +".jpg"
with open(file_path, "wb") as f:
f.write(requests.get(img_down_param[1]).content)
print(file_path + "下载完成")
#主程序
if __name__ == '__main__':
n = 0
#循环抓取三百多页
for i in range(1, 316):
#构造url
url = "https://list.jd.com/list.html?cat=670%2C671%2C673&page={}&s=57&click=0".format(i)
#获取该页的商品url列表
img_urls = crawl(url, i)
#定义图片命名数字
img_count = len(img_urls) + n
img_name = [j for j in range(n, img_count)]
n = img_count
#构造下载图片的实参,存储路径和图片url组成的元组组成的列表
img_down_param = zip(img_name, img_urls)
#创建进程池
pool = Pool(processes=5)
#启动多进程下载
pool.map(download_img_multipro, img_down_param)
#封闭进程池并使主进程阻塞,等待子进程结束
pool.close()
pool.join()
爬取结果
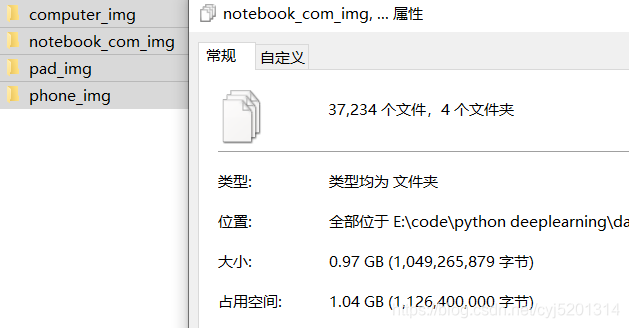
抓取的四种类别图片分别存储在同一相对路径的四个文件夹,分别代表台式机,笔记本,pad和手机
制作数据集
利用opencv将单张图片的RGB像素值读取出来,用一个向量保存(注意这里用opencv读取的像素值实际为BGR即蓝绿红)
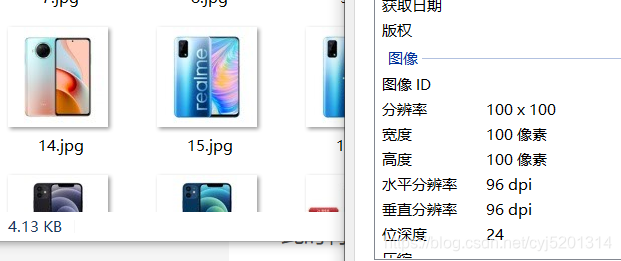
全部商品图片均为220 * 220 像素,三通道。
若将单个图片用一个向量保存,则该向量维度为 220 * 220 * 3 = 145200 显然这个向量过大
这里考虑利用opencv将每张图片压缩至100 * 100 ,此时所需向量维度为30000,可以接受
代码如下:
def compress_dataset():
"""
压缩图片数据到100 * 100
:return:
"""
#四个迭代器用于遍历四个文件夹
num_phone = range(9549)
num_pad = range(9300)
num_notebook = range(9360)
num_computer = range(9025)
globle_num = 0
#遍历手机图片文件夹
for i in num_phone:
#构造图片文件路径+文件名
file_path = "./dataset/phone_img/" + str(i) + ".jpg"
#处理异常,同时将无效图片剔除
try:
#读出原图片
np_3_img = cv2.imread(file_path)
#压缩图片
out = cv2.resize(np_3_img, dsize=(100, 100), interpolation=cv2.INTER_AREA)
#将压缩后的图片写道本地保存
cv2.imwrite("./dataset/compress_dataset/phone_img/" + str(globle_num) + ".jpg", out)
globle_num += 1
print("压缩写入成功", globle_num)
except:
print("出现异常")
globle_num = 0
for i in num_pad:
try:
file_path = "./dataset/pad_img/" + str(i) + ".jpg"
np_3_img = cv2.imread(file_path)
out = cv2.resize(np_3_img, dsize=(100, 100), interpolation=cv2.INTER_AREA)
cv2.imwrite("./dataset/compress_dataset/pad_img/" + str(globle_num) + ".jpg", out)
globle_num += 1
print("压缩写入成功")
except:
print("出现异常")
globle_num = 0
for i in num_notebook:
try:
file_path = "./dataset/notebook_com_img/" + str(i) + ".jpg"
np_3_img = cv2.imread(file_path)
out = cv2.resize(np_3_img, dsize=(100, 100), interpolation=cv2.INTER_AREA)
cv2.imwrite("./dataset/compress_dataset/notebook_com_img/" + str(globle_num) + ".jpg", out)
globle_num += 1
print("压缩写入成功")
except:
print("出现异常")
globle_num = 0
for i in num_computer:
try:
file_path = "./dataset/computer_img/" + str(i) + ".jpg"
np_3_img = cv2.imread(file_path)
out = cv2.resize(np_3_img, dsize=(100, 100), interpolation=cv2.INTER_AREA)
cv2.imwrite("./dataset/compress_dataset/computer_img/" + str(globle_num) + ".jpg", out)
globle_num += 1
print("压缩写入成功")
except:
print("出现异常")
此时将全部图片压缩成100 * 100像素并保存至本地
利用卷积神经网络进行图像分类
#构建网络
from keras import layers
from keras import models
model = models.Sequential()
#卷积层1 输入张量为图像的像素矩阵
model.add(layers.Conv2D(32,(3,3), activation="relu", input_shape=(110,110,3)))
#池化层1,最大池化
model.add(layers.MaxPooling2D((2,2)))
#卷积层2
model.add(layers.Conv2D(64,(3,3),activation="relu"))
#池化层2
model.add(layers.MaxPooling2D((2,2)))
#卷积层3
model.add(layers.Conv2D(128,(3,3),activation="relu"))
#池化层3
model.add(layers.MaxPooling2D((2,2)))
#卷积层4
model.add(layers.Conv2D(128,(3,3),activation="relu"))
#池化层4
model.add(layers.MaxPooling2D((2,2)))
#将输出张量拉平
model.add(layers.Flatten())
#随机删去此层一般的参数以防止过拟合
model.add(layers.Dropout(0.5))
#全连接层
model.add(layers.Dense(512, activation="relu"))
#输出层,softmax激活,输出概率值
model.add(layers.Dense(4, activation="softmax"))
编译网络
#编译模型
from keras import optimizers
#使用分类交叉熵损失函数,准确率作衡量指标
model.compile(loss="categorical_crossentropy",
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=["accuracy"]
)
数据预处理
利用keras图像数据生成器将本地路径的图形数据读取出来,返回生成器给网络训练使用
#数据预处理
from keras.preprocessing.image import ImageDataGenerator
#存储数据的路径
train_img_dir = "E:/code/python deeplearning/dataset/compress_dataset/train"
validation_img_dir = "E:\\code\\python deeplearning\\dataset\\compress_dataset\\validation"
#数据生成器,将原像素值压缩到0-1之间并对训练数据进行数据增强
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1./255,)
#训练数据生成器
train_generator = train_datagen.flow_from_directory(
train_img_dir,
target_size=(110,110),
batch_size=128,
class_mode="categorical"
)
#验证数据生成器
validation_generator = test_datagen.flow_from_directory(
validation_img_dir,
target_size=(110,110),
batch_size=128,
class_mode="categorical"
)

训练集共三万多张,验证集五千多张
模型训练
将数据生成器传给模型训练,批量大小为128,训练一代共250个批次,验证共40个批次,共训练5轮
history = model.fit_generator(
train_generator,
steps_per_epoch=250,
epochs=5,
validation_data=validation_generator,
validation_steps=40
)
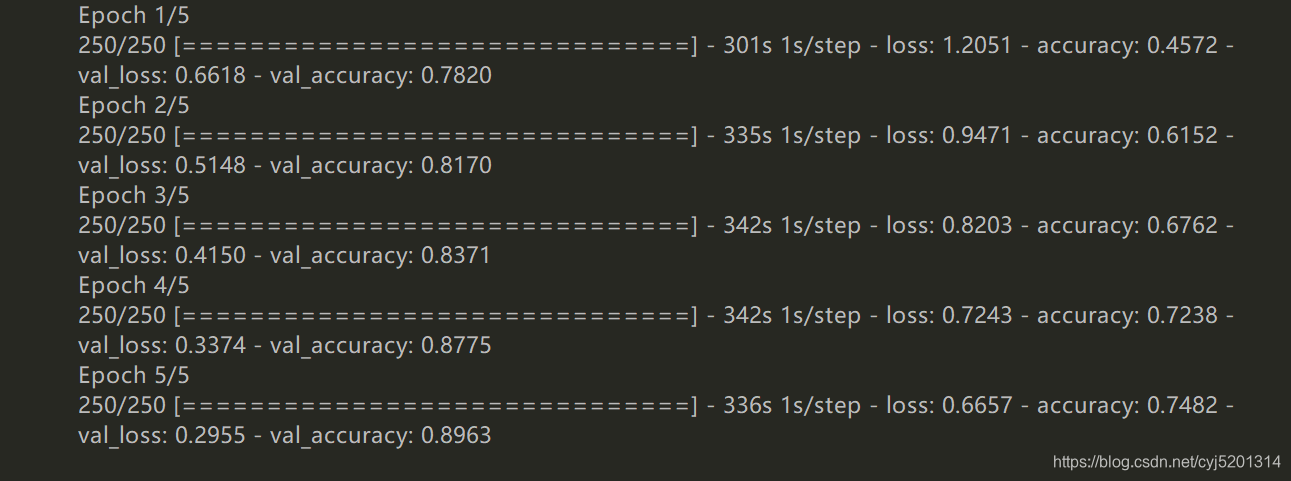
结果显示,训练集准确率达到近75%,验证集准确率达到近90%。结果表现良好
验证集准确率高于训练集是由于模型做了较强的防止过拟合操作,比如随机删去一般网络参数,作正则化惩罚项等,所以在训练集上学习速度较慢,模型过拟合的速度也很慢,所有最终在验证集上表现更好,这也符合模型的训练初衷
最终测试模型
#生成测试数据
test_datagen = ImageDataGenerator(rescale=1./255,)
test_img_dir = "E:\\code\\python deeplearning\\dataset\\compress_dataset\\test"
test_generator = test_datagen.flow_from_directory(
test_img_dir,
target_size=(110,110),
batch_size=128,
class_mode="categorical"
)
传入测试数据测试
res = model.evaluate_generator(test_generator, steps=40)

结果显示,达到近90的测试准确率