(一)数据准备
1.爬取京东自营店kindle阅读器的评价数据,对数据进行预处理,使用机器学习算法对评价文本进行舆情分析,预测某用户对本商品的评价是好评还是差评。通过数据分析与模型分析,推测出不同型号(价格)的kindle具有的特征,并根据每种型号的特征向不同需求的顾客推荐。爬取的数据集中包括“评论”、“字数”、“评论的点赞数”、“评论的评论数”、“评论类型”五列,为了找出价值较高的数据。首先利用主成分分析的方法,将“字数”、“评论的点赞数”、“评论的评论数”作为输入变量,得到每条数据的权重,而后抽取好评与差评中,权重最高的各50条记录,进行抽样,利用抽样得到的100条数据进行数据分析。随后,对评论内容进行结巴分析并去除停用词及数字、英文等词(图2-3),并用词云进行结果展示(图2-4);根据图2-4的词云内容可知,558款kindle好评偏多,它的关键词为“白色”、“喜欢”、“看书”、“阅读”等,但也有较多“闪屏”、“问题”字眼;928款kindle主要关键字为“电子书”、“喜欢”、“保护”、“屏幕”、“售后”等;1258款kindle关键字为“喜欢”、“屏幕”、“阅读”、“物流”等。



558款 928款 1258款
2.计算词频
将分词后的语句转换为向量的形式,这里使用CountVectorizer实现转换为词频;并将句号、评论内容、是否好评、单句词频、词汇总词频等存储到excel中,便于下一步的分析,如图。

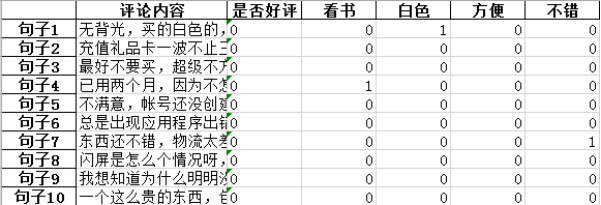
3.计算TF-IDF值
TF-IDF是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。TF-IDF权重计算方法主要用到两个类:CountVectorizer和TfidfTransformer。
①CountVectorizer。CountVectorizer类会将文本中的词语转换为词频矩阵,例如矩阵中包含一个元素a[i][j],它表示j词在i类文本下的词频。它通过fit_transform函数计算各个词语出现的次数,通过get_feature_names()可获取词袋中所有文本的关键字,通过toarray()可看到词频矩阵的结果。②TfidfTransformer用于统计vectorizer中每个词语的TF-IDF值。
下图2-7、2-8是计算评论TF-IDF值的主要代码及结果展示。

图2-7 计算评论TF-IDF值
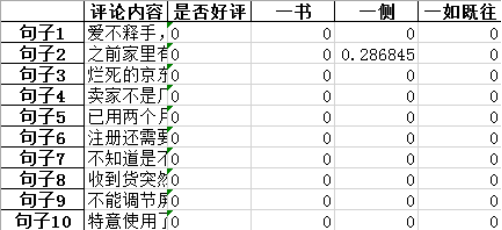
图2-8 TF-IDF值展示
(二)模型构建
模型构建前用LassoCV回归模型进行特征选择,对整个数据集降维,再先后构建决策树、朴素贝叶斯模型。
1.特征选择
首先,这里用生成的词向量文件举例,观察数据预处理中得到的数据集特征。该数据集其实是一个大型的稀疏矩阵,该矩阵中零元素占大多数且维度很高,如1258款的数据集除目标变量“是否好评”外,一共有720个自变量(分出来的全部词)。其实,里面大多数的词对于目标变量没有重要价值,如果全部作为模型的输入变量,构建出模型的质量不会太好,所以很有必要对数据集进行特征选择。
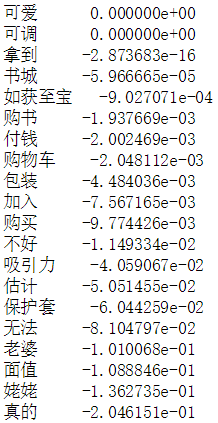
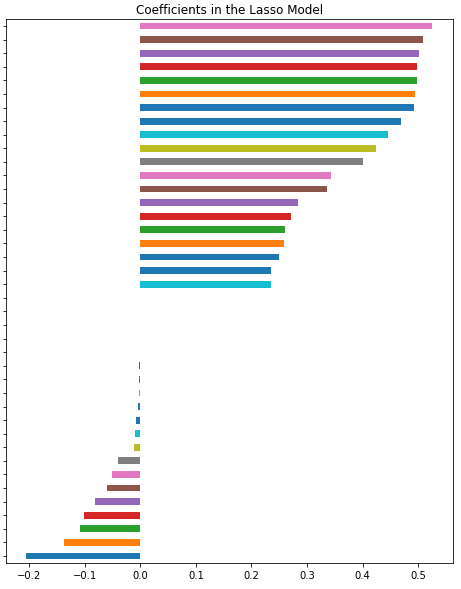
由于该数据集是高纬度稀疏矩阵, LassoCV回归模型正好擅长在高纬度系数矩阵中的一堆特征里面找出对应于目标变量主要的特征,该模型的效果是,可以使得一些特征的系数较小,并使一些绝对值较小的系数直接变为0,如果该变量的系数为0,则说明这个变量不重要,这样就可以在后续的操作中根据这个把不重要的变量筛选掉,从而增强模型的泛化能力,因此可以通过该模型计算出各个变量系数的结果来区分变量的重要性,以及筛选掉那些并不重要的变量
如图3-1所示,可知该模型信息与该模型最终筛选掉了653个无关变量,最终保留了67个重要变量。


LassoCV回归模型
再将模型结果根据计算出的系数进行排序,打印出前20个和后20个进行观察,如图所示。



3.构建朴素贝叶斯、神经网络模型
1)训练朴素贝叶斯模型使用tf-idf值的文件,同样经过LassoCV回归模型特征选择后,采用训练集70%,测试集30%的模式进行模型的训练与测试,如图3-8所示,其模型准确率与决策树一样达到97%,召回率与F值均为97%,模型效果很好。
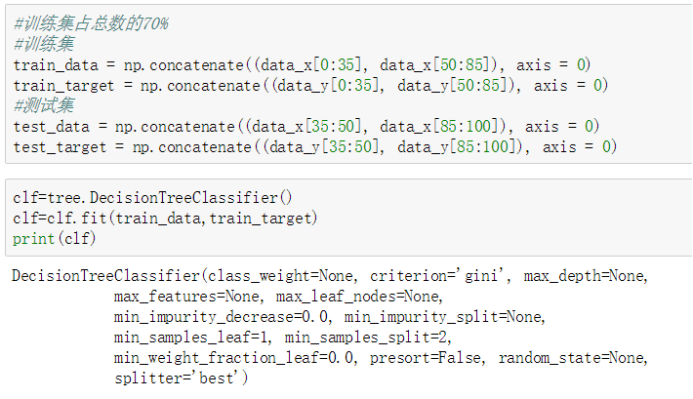
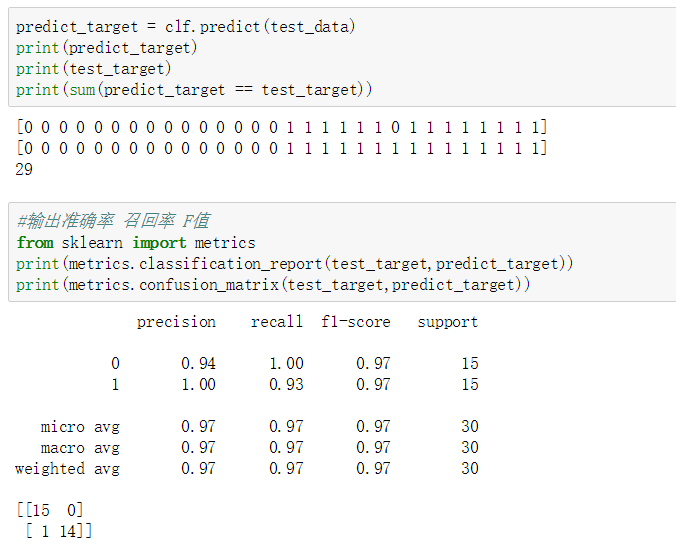
图 3-8 朴素贝叶斯模型
2)训练神经网络同样使用与朴素贝叶斯一样的数据集,模型构建及测试如图3-9所示,测试集中有28个预测正确,准确率达到93.3%,召回率与F值均为93%,模型效果不错。
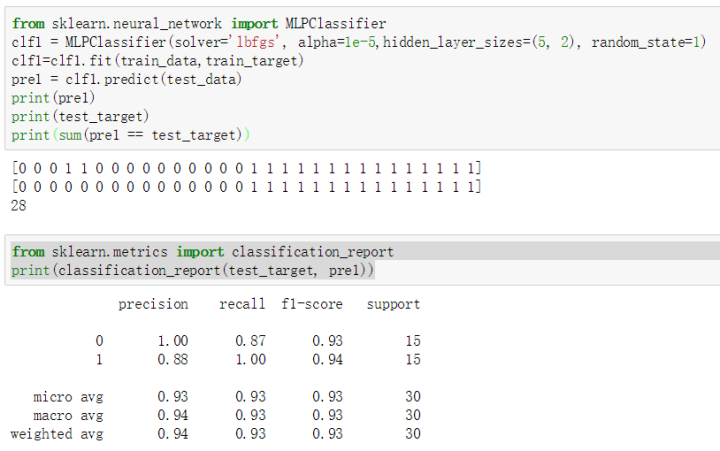
图 3-9 神经网络模型
4.模型结论
对模型结果进行分析,首先我们分析特征选择模型筛选出的对于顾客体验有关联的40个词,把每种型号的词分为“与商品特征相关”、“与客户体验相关”两类词,同时剔除无关词语如:
1.情绪化词语(对于推测商品特征没帮助),如'喜欢'、'不好'、'强烈推荐'、'没用'
2.词意不确定的词语
3.无意义词语,结合决策树中的关键词,最终得出结论如下表所示。
|
|
558款 |
928款 |
1258款 |
| 与商品特征相关 |
'跳字','插头','彩色','功能','光线','轻便','白色' |
'黑色','处理速度','字迹','充电','保护套','分辨率' |
'保护套','电量','数据线','味道','塑料','屏幕','纸质','内存' |
| 与客户体验相关 |
'划痕','服务态度','好看','方便','眼睛','轻便','沉沉的' |
'堪比','纠结','轻便','眼睛','舒服','晚上' |
'用券','价格','免息','方便','礼物' |
| 官方数据 |
入门款 分辨率:167ppi 无阅读灯 重量:161克 内存:4G 防水:无 |
经典款 分辨率:300ppi 有阅读灯 重量:161克 内存:8G 防水:IPX8 |
漫画款 分辨率:300ppi 有阅读灯 重量:161克 内存:32G 防水:IPX8 |
| 决策树重要词语(括号中为补充解释) |
'方便'、(受欢迎)'白色'、(不)'伤眼' |
(重要)'晚上'、'轻便'、(美观)'保护套' |
(好)'屏幕'、(价格)'免息'、'方便' |
| 结论 |
入门款有基础功能,购买该款的人群主要为了方便、不伤眼看书舒服,要求较低。该款白色更受欢迎,侧面说明购买该款的人女性居多 |
经典款在入门款的基础上加了阅读灯,提升了分辨率。购买该款的人群相比于入门款主要为了阅读轻便舒服、晚上阅读方便、分辨率更高、处理速度更快。且比入门款更加在意保护套,说明购买这一款的人群更加注重美观 |
漫画款在经典款的基础上增加了大内存。购买该款的人群主要为了高质量的屏幕以及大的内存。由于该款价格较高,购买的人较注意购买时分期免息的优惠。侧面说明购买kindle的人群价格接受分界线在1000元左右 |
(三)数据分析
主题分析-潜在语义分析模型(LSA)与文档主题生成模型(LDA)
1 传统向量空间模型的缺陷
向量空间模型简单的基于单词的出现与否以及TF-IDF等信息来进行检索,但是“说了或者写了哪些单词”和“真正想表达的意思”之间有很大的区别,其中两 个重要的阻碍是单词的多义性(polysems)和同义性(synonymys)。多义性指的是一个单词可能有多个意思,比如Apple,既可以指水果苹果,也可以指苹果公司;而同义性指的是多个不同的词可能表示同样的意思,比如search和find。
2 潜在语义分析模型(LSA)
我们希望找到一种模型,能够捕获到单词之间的相关性。如果两个单词之间有很强的相关性,那么当一个单词出现时,往往意味着另一个单词也应该出现(同义词);反之,如果查询语句或者文档中的某个单词和其他单词的相关性都不大,那么这个词很可能表示的是另外一个意思(比如在讨论互联网的文章中,Apple 更可能指的是Apple公司,而不是水果) 。
LSA(LSI)使用SVD来对单词-文档矩阵进行分解。SVD可以看作是从单词-文档矩阵中发现不相关的索引变量(因子),将原来的数据映射到语义空间内。在单词-文档矩阵中不相似的两个文档,可能在语义空间内比较相似。我们是一个使用sklearn中的TruncatedSVD进行文本主题分析。
1)实现步骤
(1)将数据填充空白值处理后抽样50条差评(或差评)。
(2)分词、停用词处理得到如图4-1的结果。
(3)将(2)的结果作为输入,调用TfidfVectorizer.fit_transform方法得到词向量矩阵
(4)设定主题数、能代表主题的文档数、主题的关键词数,调用TruncatedSVD方法处理
(5)打印结果。
2)结论解读
我们选定3个有代表性的主题(topic),每个主题选取3个代表性的文档,每个主题选取5个关键词(key word)。得到结果如表3-1,3-2所示。
表4-1 差评结果(实例)
| topic 0 |
topic 1 |
topic 2 |
|
| Keyword 0 |
京东 |
翻页 |
客服 |
| Keyword 1 |
东西 |
屏幕 |
不好 |
| Keyword 2 |
快递 |
左侧 |
态度 |
| Keyword 3 |
客服 |
一页 |
咨询 |
| doc 0 |
快递超级慢,本来送给老师的教师节礼物,竟然过了几天才到!不是说京东自营第二天可以送达的吗?又欺骗顾客,投诉还无效~~第一次这么失望 |
没有送充电头,屏幕感觉还行,右侧翻页没问题,左侧翻页混乱,经常是左侧也是下一页 |
买到的kindle有问题,咨询客服,态度很差,很不好的一次购买体验! |
| doc 1 |
第一次碰到这么慢的京东快递,绝对差评,以后买东西要考虑转其他商城了。差评差评差评 |
东西收到了,感觉不错,屏幕翻页的时候很闪,很不习惯,答应送的50元购书劵没有送,差评 |
不到俩月,出现三次这个情况,前两次自己解决了。这次彻底坏了,练习了售后,说是更换一个官方维修机。哎……可能是运气不好吧 |
| doc 2 |
失望至极 朋友说京东自营可以 结果一直闪屏 真不知道网评那么好哪来的 便宜无好货 哎上当 |
显示屏保的时候居然能看到下面一页的字!翻页的时候闪到头晕,翻页过程中经常出现黑色的屏闪,朋友家的那个就没有这种问题! |
不满意,有问题咨询。买之前客户态度很好。买过以后态度恶劣。连消息都不理。过段差评。而且注册账号,我了过凉。简直要人命 |
在此例中,3个topic可以理解为京东快递、屏幕及翻页、客服态度。这时便可向消费者传递信息,此商品的槽点在于京东快递不给力,屏幕和翻页问题,客服态度差。若消费害怕出现上述同样的问题,则不推荐购买。
表4-2 好评结果(实例)
|
|
topic 0 |
topic 1 |
topic 2 |
| Keyword 0 |
看书 |
屏幕 |
闪屏 |
| Keyword 1 |
真的 |
入门 |
现象 |
| Keyword 2 |
阅读 |
完美 |
真的 |
| Keyword 3 |
不错 |
舒服 |
接受 |
| doc 0 |
买 正好 新品 下手 拿到 失望 阅读 效果 确实 很棒 特别 电子 墨水 屏 真的 舒服 一点 不 伤 眼睛 关键 纸 快递 很快 包装 确实 令人 失望 裸机 加 塑料包装 真的 担心 物流 中途 机子 弄烂 幸好 看书 买个 操作 迟钝 换 闪 手机 灵敏 阅读 体验 很棒 系统 算是 预期 效果 |
入门 版 阅读 灯 屏幕 不平 新版 犹豫 久 到货 查看 手感 棒 入门 版款 更让人 心动 广告 关 速度 很快 后期 反馈 可用 容量 自我感觉 舒服 |
闪屏 现象 之外 操作 延迟 接受 心理准备 不错 产品 期待 很 久 阅读器 喜欢 包装 真的 简单 粗暴 哈哈哈哈 |
| doc 1 |
阅读器 买 评价 质量 不错 轻 出门 携带 轻巧 负担 放 包里 没什么 京东 物流 不错 快递 师傅 态度 机器 包装 简单 操作 繁琐 平时 手机 习惯 习惯 几本书 看书 闪频 还好 确实 眼 晴好 受点 买 想 戒 手机 不知 戒 会员 优惠 点太力 机器 到手 颜值力 字 调节 买 外壳 随身带 研究 透 机器 开机 待机时间 还好 希望 阅读 体验 |
压 泡面 神器 阅读 灯光 线 均匀 屏幕 平整 再藏尘 升级 超值 续航 差点 天 充电 显示 效果 细腻 入门 款 好多 字号 字体大小 入门 款 一点 |
关注 新品 很 久 下单 心心念念 物流 特别 其他人 说 包装 简陋 挺书券 充电器 充电 开机 卡顿 闪屏 现象 阅读 一会 闪屏 现象 发现 减少 闪屏 技巧 翻页 按着 左下角 部位 按着 左下角 稍微 往 上 部位 闪屏 阅读 体验 喜欢 |
| doc 2 |
入手 晚超 爱 阅读 早买 神器 手机 看书 眼睛 实在 受不了 干涩 发涨 电子 墨水 纸书 手机 强太 安心 看书 闪屏 不可避免 接受 乳鸭图 保护 壳 做工 不错 套 好看 |
入门 版 阅读 灯 屏幕 不平 新版 犹豫 久 到货 查看 手感 棒 入门 版款 更让人 心动 广告 关 速度 很快 后期 反馈 可用 容量 自我感觉 舒服 |
物流 超级 早上 九点 前 拍 当天 下午 四五点 收到 机器 迷你 放 接口 比例 视觉效果 不错 纸质 书 待机 显示 内容 书本 间歇 翻页 闪屏 技术 办法 解决 依然 |
在此例中,3个topic可以理解为看书阅读、屏幕完美、闪屏。这时便可向消费者传递信息,该商品的亮点在于看书阅读体验好,屏幕体验效果好,但存在闪屏现象需要注意,不过问题不大。
以往消费者购买某商品,需要浏览大量评论并反复对比好评差评,LSA精简了评论信息,不仅能实现一定程度的聚类,帮助筛选主要信息,提取关键词,更能将有代表性的具体文档提供提给消费者,为语义分析提供一定的依据。
3)LSA的不足与LDA的优点
上例中,LSA对TF-IDF进行处理得出结论,而IDF值的大小表示某词在所有文档中重要程度,IDF值越大,说明某词区别于其他词的程度就越大;相反,在所有的差评或好评中,我们希望找到大家共同出现的问题,对于某些个别问题我们可以忽略。同时,LSA利用分解SVD进行处理,主要是对分类任务进行降维。消除了同义词、多义词的影响,但LSA的概率模型假设文档和词的分布是服从联合正态分布的,但从观测数据来看是服从泊松分布。LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
4)LDA实现及结果
(1)权重排序后抽样好评差评各50条
(2)处理数据得到词频矩阵
(3)设定主题数、关键词数、支持文档数
(4)调用LatentDirichletAllocation方法进行处理得到表4-3和4-4的结果
表4-3 差评结果(实例)
|
|
topic 0 |
topic 1 |
topic 2 |
| Keyword 0 |
京东 |
客服 |
退货 |
| Keyword 1 |
下单 |
东西 |
不好 |
| Keyword 2 |
购物 |
套装 |
时间 |
| Keyword 3 |
商品 |
不错 |
闪屏 |
| doc 0 |
吐槽 京东 定价 体系 价格 变 充分利用 规则 月 日 下单 买个 套装 元 说 保价 天到 第天 价格 元书券 元书券 外壳 颜色 有变 客服 电话 教科书 式 道歉 关注 促销 活动 商品 解决 价格 短时间 随意 变 任性 变 遭遇 几次 吃亏 留意到 关注 傻子 耍 想想 细思极 恐 京东 只能 比价 下单 真买 |
物流 磨磨 唧唧 倒 说 发货 慢 货品 早 配送 站 平时 速度 配送 速度 速度 东西 配送 站 早晨 躺 尸 物流 信息 派送 信息 实在 焦急 问 网上 客服 回应 通知 告诉 东北 下雪 影响 下雪 天气 依旧 派送 期间 无数次 骚扰 客服 答案 依旧 换 电话 客服 手机号 催说 地址 详细 送错 配送 站 帮 转交 送过来 告知 丢件 问钱 说一千 这才 调 监控 仔细 排查 中午 找到 去向 下午 送来 算算 配送 站 第三天 送来 期间 态度 不错 配送 流程 扎心 操碎 母亲 心 |
第一 时间 预订 此款 第一 时间 付 尾款 预订 多花 块钱 发货 拖 半个 多月 好多 买 收到 货 焦急 等待 中 一个多月 送 电子书 券未 到 账 不知 猴年马月 |
| doc 1 |
商品 京东 服务 套装 寄过来 变 裸机 投诉 告知 外壳 选 京东 购物 糟心 京东 服务 越来越 差 |
补发 购书 券 售后 态度 超级 解决 京东 专属 客服 店铺 客服 两边 踢皮球 可想而知 真 碰到问题 京东 售后 坑 |
特别 不好 打开 闪屏 做 操作 差点 眼镜 晃坏 果断 退货 |
| doc 2 |
商品 不错 京东 物流 只用 袋子 送过来 袋子 折损 好好 包装 套装 售货 清单 里 外壳 发过来 外壳 返京 豆 不爽 |
阅读器 皮套 订 收到 阅读器 保护套 没收 两个 包裹 京东 快递 员 说 包裹 问 客服 没 人 回应 |
莫名其妙 商店 英文 账户 买书 找 不到 这是 第三个 前 两个 设置 情况 先是 半天 不上 账号 买 书 一本 找 不到 |
在此例中,3个topic可以理解为商品折损,物流慢,闪屏。消费者购买时需要主要这些问题。
表4-4 好评结果(实例)
|
|
topic 0 |
topic 1 |
topic 2 |
| Keyword 0 |
屏幕 |
屏幕 |
看书 |
| Keyword 1 |
阅读 |
完美 |
不错 |
| Keyword 2 |
入门 |
看书 |
阅读 |
| Keyword 3 |
终于 |
不错 |
真的 |
| doc 0 |
心 水 终于 到手 有过 一款 一代 送给 朋友 想着 买 终于 入手 一代 摸 质感 更好 重 显示 效果 那种 清晰 简单 配置 推荐 纠结 容量 小伙伴 买 版本 反馈 周期长 看书 实际上 够用 都行 翻倍 不行 哈哈哈 真的 值得 |
基础 班 用户 买 基础 版 担心 吃 灰 发现 好用 升级 理由 因素 像素 说 基础 版 够用 真的 无法忍受 毛刺 感 很 强 忘记 屏幕 电子 背光 因素 基础 版 背光 确实 场景 一体化 屏幕 清爽 不易 积灰 整体性 更强 内存 升级 意义 |
阅读器 买 评价 质量 不错 轻 出门 携带 轻巧 负担 放 包里 没什么 京东 物流 不错 快递 师傅 态度 机器 包装 简单 操作 繁琐 平时 手机 习惯 习惯 几本书 看书 闪频 还好 确实 眼 晴好 受点 买 想 戒 手机 不知 戒 会员 优惠 点太力 机器 到手 颜值力 字 调节 买 外壳 随身带 研究 透 机器 开机 待机时间 还好 希望 阅读 体验 |
| doc 1 |
这 是 家 第三个 新款 入门 版 分辨率 高初 代高加 注音 反应速度 初代 流畅 出厂 固件 系统 最新 客服 建议 官网 更新 链接 下载 费劲 放弃 尺寸 初代 轻薄 屏幕 边框 一体 插头 挺好用 评论 屏幕 坏点 广告 挺 喜欢 推荐书 想着 关新 服务 书 找到 关键 书 设备 太 春节 京东 送货 赞 |
带质 保单 公司 同事 买 领导 推荐书 电子书 不错 书 够用 字体 调节 大小 调整 亮度 免费 推送 文章 不错 够用 快递 太 简陋 原装 薄 盒子 屏幕 压碎 幸好 顺丰 快递 肯定 摔次 |
买 正好 新品 下手 拿到 失望 阅读 效果 确实 很棒 特别 电子 墨水 屏 真的 舒服 一点 不 伤 眼睛 关键 纸 快递 很快 包装 确实 令人 失望 裸机 加 塑料包装 真的 担心 物流 中途 机子 弄烂 幸好 看书 买个 操作 迟钝 换 闪 手机 灵敏 阅读 体验 很棒 系统 算是 预期 效果 |
| doc 2 |
利益 相关 用户 先 评价 超级 赞取 快递 拿错 真的 超薄 工艺 更新换代 新 屏幕 阴阳 屏 反正 屏幕 坏点 多存 点儿 书以 供 出差 路上 买 实有 接受 系统 存储管理 软件 占 一部分 容量 防水 仔细 想想 真的 超赞 生活 中 威胁 解决 买 顺便 买 套子 平时 爱惜 不用 买膜 超赞 跟前 一代 相比 阴阳 屏 真的 屏幕 歪斜 赞 |
平面 很爽 待机时间 蛮长配 套餐 买 外壳 不错 看书 网购 有时候 懒得 评价 京东 配送 服务 一流 送货 快递 员 态度 送货上门 希望 京东 越做越 提供 更好 商品 服务 |
久 评论 压 泡面 神器 看书 真的 躺 床上 用手 不 累加 壳 加壳 磁吸 控制 屏幕 唤醒 睡眠 晚上 睡不着 看看书 瞬间 想 睡觉 清晰度 够 放大 用眼 真的 舒服 比看 电脑 舒服 不用 打印 适合 深度 阅读 文献 适合 快速 浏览 文献 翻页 真的 慢 用 邮件 小说 算 反应速度 真的 很慢 很慢 用惯 手机 电脑 肯定 莫名 缓慢 反应速度 有利于 专注 阅读 状态 说 神器 值得 拥有 |
这三个topic可以理解为商品入手体验好,屏幕清爽,看书体验好。若满足消费者需求,则可以考虑购买。
3数据分析结论
通过以上介绍的方法,分析数据集,分别得出三款kindle的好评、差评结论
| 558款关键词及解读 |
928款关键词及解读 |
1258款关键词及解读 |
|
| 好评 |
京东, 喜欢, 特别, 看书 |
电子书, 喜欢, 开心, 希望 |
屏幕, 阅读, 入门, 终于 |
| 阅读, 真的, 不错, 学生 |
不错, 阅读, 看书, 喜欢 |
屏幕, 完美, 看书, 不错 |
|
| 看书, 喜欢, 白色, 晚上 |
真的, 京东, 手机, 体验 |
看书, 不错, 阅读, 真的 |
|
| 快递服务好,阅读体验好,白色好看 |
护眼,专注阅读,比手机阅读体验好 |
商品入手体验好,屏幕清爽,看书体验好 |
|
| 差评 |
充电, 翻页, 收到, 一点 |
电子书, 错误, 内容, 两天 |
京东, 下单, 购物, 商品 |
| 京东, 自营, 电子书, 失望 |
屏幕, 闪屏, 郁闷, 确实 |
客服, 东西, 套装, 不错 |
|
| 客服, 产品, 包装, 体验 |
京东, 东西, 不错, 看书 |
退货, 不好, 时间, 闪屏 |
|
| 充电充不进去,客服态度差,京东自营物流和设备差 |
电子书内容少,屏幕闪屏 |
商品折损,物流慢,闪屏。 |