目录
背景
放假一周多,闲得没事儿,继续分享对cuda文档的翻译,先声明下我的测试环境:cuda10.0,ubuntu16.04 x86_64,gcc/g++7.0
APOD
官方文档提出的应用优化模型为评估(Assess)、并行化(Parallelize)、优化(Optimize)和部署(Deploy),简称APOD,如下图所示
APOD是一个环形的过程:先投入少量的精力与时间达到最初的优化与加速,然后不断迭代
评估
对于一个已有的项目,第一步是对其进行评估,以定位出需要消耗大量执行时间的代码,以便之后对其进行并行化和加速。另外,通过理解终端用户的需求、限制,再应用阿比达尔定律和古斯塔夫森定律,开发人员可以确定表现力提高的上界,这种提高就是来自于对项目指定部分的加速
并行化
定位好了热点代码和提升目标,开发者就要对代码进行并行化。根据原始代码的不同,并行化方法有两种:调用现成的GPU优化库(cuBLAS、cuFFT或Thrust)和添加预处理指令(hint等)以并行化编译器。
另外,一些应用可能要做一些设计上的重构,以探索或开发并行度,甚至CPU架构为了提高或者保持顺序应用的表现力,也要对并行度进行探索,而CUDA的并行编程语言(CUDA的c/c++、fortran等)旨在尽可能简单地描述这种并行度,同时在支持cuda的gpu设备上开启对应的操作以最大化并行吞吐量。
优化
当每一轮的应用并行化完成后,开发者就可以进行优化以提高表现力了。因为优化方法很多,所以开发者需要理解应用的需求,这样会避免很多不必要的麻烦。优化的层面很多,包括把数据传输和计算并行处理一路向下到细粒度地微调浮点操作序列,此时优化工具就很宝贵,因为它们能对开发者下一步的优化给出建议。
部署
完成了对项目一个或多个部分的GPU加速后,就可以比较加速前和加速后的效果了,也可以把第一步评估中定出的表现力上界拿出来做对比。
最后,重申一遍,最好一次只对项目的某个部分进行APOD过程优化加速,然后再优化别的部分,这样迭代进行可以缩短交付周期。
下面就是对这APOD更详细的讲解
评估
从超级计算机到智能手机,现代处理器越来越依靠并行度来提供好的表现力。大量的核心计算单元(包括控制器、运算器、寄存器和一些缓存)和内存相连,为代码实现并行化提供了条件。
尽管处理器正朝着向开发者提供更加细粒度的并行化的方向发展,但现在很多应用的代码还是串行或者粗粒度的并行,例如将数据分成几个能够并行处理的区,区之间使用MPI通信或共享数据。为了利用包括GPU在内的现代处理器架构,我们头一步就是对项目进行评估,找出热点代码并判断它们能不能被并行化,以及评估工作量
异构计算
cuda编程涉及把代码同时在两个平台运行:主机系统(host,cpu平台)和设备系统(device,支持cuda的英伟达gpu)。尽管英伟达gpu经常跟图像关联在一起,但它们也支持并行运行上千个轻量级线程来进行数字运算,这使得英伟达gpu很适合要并行执行的计算应用。但是,设备系统的设计是和主机系统大相径庭的,因此理解两者的区别和它们如何决定cuda应用的表现力对我们有效使用cuda大有裨益
设备系统和主机系统的区别
主要的区别包括线程模型和物理内存两方面
线程资源
主机系统只能支持少量的并行线程,例如拥有四个十六进制处理器的服务器只能并行运行24个线程,如果CPU支持超线程的话,就可以支持48个;
但在现代英伟达gpu中,最小的执行单元由32个线程组成(称之为伪线程,a warp of threads),如果包含多个执行单元的一个处理器可以支持1536个线程并行,那么如果有16个处理器,那就可以有超过2.4万个线程同时运行
线程
CPU上的线程通常是重量级的实体,操作系统为了提供多线程能力,需要在CPU执行通道开启和关闭时进行线程的交换,而交换两个线程数据时的上下文切换是缓慢的;
相比之下,GPU的线程就很轻量级。在一个典型的系统中,上千个伪线程(每个伪线程包括32个线程)在排队等待工作。如果gpu一定要等一个伪线程完成,他就会执行别的伪线程。由于所有的活动线程都被分配了独立的寄存器,直到它们完成任务时才释放,所以gpu线程之间交换数据时不需要寄存器的交接或者别的工作。
简而言之,cpu核的设计是一次性为一个或两个线程最小化延迟,但gpu是用来处理大量并发、轻量级线程以最大化吞吐量。
内存
主机系统和设备系统拥有独立的物理内存,通过PCI总线相连。两块内存必须时不时相互交流,这一点会在下一节gpu设备上运行的东西中描述
除了这几点的主要差别外,另外一些差异会在出现时讲解。使用GPU-CPU进行异构的应用可以综合考虑主机系统和设备系统,以让它们都能够各尽其责,也就是让CPU处理串行任务,GPU处理并行任务
gpu设备上运行的东西
当决定哪些内容要在gpu上运行时,就需要考虑下面内容:
- 设备系统适合同时在大量数据元素上执行的计算,包括在大型数据集(例如矩阵)上面的数学运算,这种运算要同时在上千(而不是上百万)个数据元素上执行。因此,如果我们的代码需要使用成千上万个并行线程时,就可以考虑把它们放到gpu设备上;
- 在设备系统中运行的相邻线程应该在内存访问上有一些一致性。固定的内存访问模板可以让硬件把多组数据的读写合并到一个操作里,这么做是因为数据不能拆分,而且数据量大的话就没有足够的本地性来有效使用L1或者纹理缓存,以至于降低cuda的加速性能;
- 使用cuda时,数据值必须通过PCI总线从主机复制到设备中。这种复制有损于性能因此应该被最小化,分为以下几种情况
1、被少量线程短暂使用的数据不适合在主机和设备之间来回复制,因为开销大于收益。真正应该复制数据的场景应该是当大量线程执行复杂工作时,才进行数据在主机和设备之间的复制。比如对于两个N*N的矩阵,如果要做矩阵加法,那么从两个源矩阵复制给cuda到结果矩阵复制回主机,总共有3N^2个数据会进行传输,而矩阵加法本身的时间复杂度是O(N^2),因此操作和迁移的时间复杂度比为1:3。这个比值越大,数据迁移带来的好处就越明显,例如把矩阵加法换成矩阵乘法(时间复杂度为O(N^3)),时间复杂度比值就成了N,这个收益会随着矩阵的规模的增大而增大。不同的操作有不同的复杂度,因此在决定是否要执行数据在主机和设备之间的传输时,要执行的操作是我们考虑的重要因素之一;
2、 如果发生了数据迁移,那么数据在设备上停留的时间越长越好(也就是数据传输不要太频繁)。程序在多个核上操作一组数据时,应该在两个核函数调用之间让数据一直留在设备上,而不是将中间结果在主机和设备间来回迁移。对于前面的例子,如果要相加的两个矩阵是前置计算的结果,或者相加的结果要被后续计算使用,那么矩阵加法应该在设备上被本地执行。即便序列计算中的某一步在主机上执行更快,我们也要尽量避免数据的迁移,因为数据迁移带来的性能损失可能会抵消为了某一步更快的计算而带来的收益,更详细的讲解请参见主机和设备之间的数据迁移一章。
应用分析
一个应用可以分为数个模块,每个模块用一小段代码完成一个功能。使用分析器,开发者可以识别出热点代码从而开始编译候选对象,以供并行化的实现
分析
首先我们要使用工具去分析我们的可执行程序,例如可以使用Linux自带的gprof。以之前编译的rodinia测试样例为例,讲解一下怎么使用它。使用gprof时,要先在编译选项中加入-pg参数(可以修改Makefile,也可以在gcc或g++后面添加-pg)
CC_FLAGS = -g -fopenmp -O2 -pg然后正常编译,运行(必须先运行才能分析)
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# gcc -g -fopenmp -O2 -c kmeans.c
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# make
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# ./kmeans -i ../../data/kmeans/204800.txt此时会在当前目录下生成gmon.out,这就是分析好的文件
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# ll
total 2104
drwxrwxrwx 2 root root 4096 11月 2 20:30 ./
drwxrwxrwx 25 root root 4096 11月 2 08:59 ../
-rwxrwxrwx 1 root root 7712 12月 11 2015 cluster.c*
-rw-r--r-- 1 root root 10440 11月 2 20:29 cluster.o
-rwxrwxrwx 1 root root 39978 12月 11 2015 getopt.c*
-rwxrwxrwx 1 root root 6854 12月 11 2015 getopt.h*
-rw-r--r-- 1 root root 4920 11月 2 20:29 getopt.o
-rw-r--r-- 1 root root 3527 11月 2 20:30 gmon.out
-rwxr-xr-x 1 root root 65344 11月 2 20:29 kmeans*
-rwxrwxrwx 1 root root 13058 12月 11 2015 kmeans.c*
-rwxrwxrwx 1 root root 8621 12月 11 2015 kmeans_clustering.c*
-rw-r--r-- 1 root root 12304 11月 2 20:29 kmeans_clustering.o
-rwxrwxrwx 1 root root 10890 12月 11 2015 kmeans_cuda.cu*
-rwxrwxrwx 1 root root 5739 12月 11 2015 kmeans_cuda_kernel.cu*
-rw-r--r-- 1 root root 25024 11月 2 20:29 kmeans_cuda.o
-rwxrwxrwx 1 root root 3463 12月 11 2015 kmeans.h*
-rw-r--r-- 1 root root 1790384 11月 2 20:29 kmeans.h.gch
-rw-r--r-- 1 root root 29352 11月 2 20:29 kmeans.o
-rwxrwxrwx 1 root root 755 11月 2 20:28 Makefile*
-rwxrwxrwx 1 root root 2145 12月 11 2015 Makefile_nvidia*
-rw-r--r-- 1 root root 6169 11月 2 20:30 profile.txt
-rwxrwxrwx 1 root root 591 12月 11 2015 README*
-rwxrwxrwx 1 root root 3031 12月 11 2015 rmse.c*
-rw-r--r-- 1 root root 15152 11月 2 20:29 rmse.o
-rwxrwxrwx 1 root root 42 12月 11 2015 run*
-rwxrwxrwx 1 root root 28418 12月 11 2015 unistd.h*然后使用gprof对刚刚运行的可执行文件进行分析,把结果重定向到profile.txt中
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# gprof ./kmeans > profile.txt最后查看一下结果
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans# cat profile.txt
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls Ts/call Ts/call name
100.06 0.01 0.01 kmeansCuda
0.00 0.01 0.00 1 0.00 0.00 cluster
0.00 0.01 0.00 1 0.00 0.00 kmeans_clustering
....
Call graph (explanation follows)
granularity: each sample hit covers 2 byte(s) for 99.94% of 0.01 seconds
index % time self children called name
<spontaneous>
[1] 100.0 0.01 0.00 kmeansCuda [1]
-----------------------------------------------
0.00 0.00 1/1 setup [16]
[2] 0.0 0.00 0.00 1 cluster [2]
0.00 0.00 1/1 kmeans_clustering [3]
-----------------------------------------------
0.00 0.00 1/1 cluster [2]
[3] 0.0 0.00 0.00 1 kmeans_clustering [3]
-----------------------------------------------
....
Index by function name
[2] cluster [1] kmeansCuda [3] kmeans_clustering
root@rtlab-computer:/home/rtlab/szc/rodinia_3.1/cuda/kmeans#可以看到各个函数的执行情况,明摆着kmeansCuda几乎占用了全部的执行时间,因此这个函数就是我们的热点代码。
运行在cuda上的应用程序的性能提升完全取决于它的并行化程度,因此不能充分并行化的代码应该运行在CPU上,除非这么做会导致CPU和GPU之间通信带来的额外开销。
缩放
理解应用可以如何缩放有利于我们设置期望并规划出增量并行化的计划。应用缩放分为强缩放和弱缩放。
强缩放
强缩放用来测量在问题规模固定的情况下,解决方案的耗时是如何随着处理器的增加而减少的。表现为线性强缩放的应用的加速效果可以随着处理器的数量的增加而增加。
强缩放通常和阿比达尔定律联系在一起。阿比达尔定律指明了通过并行化一个串行程序的不同部分可以达到的最大加速期望值S,其公式如下图所示
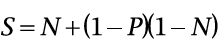
其中,P表示整个串行程序中可并行代码的执行时长,N表示处理器数量。显然,N越大,P/N越小,如果N非常大,S就成了1/(1 - P)。那么此时,如果当前的串行程序中有3/4可以被并行化,其最大加速值S就为4。
只可惜,现实中的应用并不表现为完全的线性强缩放,应用里表现为线性强缩放的部分也不多。但即便如此,我们也可以从阿比达尔定律中发现,程序中可并行部分占全部代码的比率P越大,加速值就越大。如果P很小,处理器数量N再多也是枉然。因此,对于一个固定规模的问题,我们应该增大P值,也就是尽可能让我们程序中可并行执行的部分增多。
弱缩放
有强就有弱,弱缩放用来测量总体问题规模随着处理器数量的增加而增大的情况下,解决方案耗时的变化情况。注意有一个前提,那就是虽然总体问题的规模随着处理器数量的增加而增大,但是单个处理器要处理的问题规模是不变的。
弱缩放通常和古斯塔夫森定律联系在一起。古斯塔夫森定律指明了在问题规模随着处理器数量的增大而增大时,最大加速值S的变化情况,其公式如下图所示
P和N的含义还是和阿比达尔定律中的一样,分别表示整个串行程序中可并行代码的执行时长和处理器数量。
古斯塔夫森定律表明,随着系统规模的增大,限制我们的不是问题规模而是执行时间。另外,古斯塔夫森定律假设可并行执行代码占总程序的比重是固定的,从而反映了面对规模渐长的问题时产生的额外的设置和处理开销
应用
对于一个应用而言。理解它适合哪种缩放对于评估它的最大加速值很重要。对于一些问题规模不变的应用,显然只适用强缩放,一个例子就是为两个分子间的反应建模,这里问题规模显然是固定的;对于另外一些问题,它们的规模会随着处理器的增加而增大,例如把流体或结构体建模成网格或网络,并进行一些蒙特卡洛模拟,此时问题规模的增加会提供更高的精确度。
当我们生成并分析好了我们的程序后,我们就应该分析如果处理器数量改变,我们的问题规模会如何变化,从而应用阿比达尔或者古斯塔夫森定律来计算加速值的上限。
并行化
定位好了热点代码和提升目标,开发者就要对代码进行并行化。根据原始代码的不同,并行化方法有两种:调用现成的GPU优化库(cuBLAS、cuFFT或Thrust)和添加预处理指令(hint等)以并行化编译器。
另外,一些应用可能要做一些设计上的重构,以探索或开发并行度,甚至CPU架构为了提高或者保持顺序应用的表现力,也要对并行度进行探索,而CUDA的并行编程语言(CUDA的c/c++、fortran等)旨在尽可能简单地描述这种并行度,同时在支持cuda的gpu设备上开启对应的操作以最大化并行吞吐量。
我们可以使用一些关键策略来将串行代码并行化,但是具体如何应用就是一个复杂且具体的问题了,这里对这些策略进行简介
并行化库
将应用并行化的最直接方法就是使用cuda提供的现成库,这些库使用了英伟达的并行架构。cuda工具包提供了大量用来在英伟达gpu上进行对项目细粒度调整的库,比如cuBLAS、cuFFT等。当这些库完美匹配应用的需求时,它们的用处就很大。例如,使用了别的BLAS库的程序可以很容易地转到cuBLAS,尽管基本不使用线性代数的应用也不怎么使用cuBLAS。同样,cuFFT和FFTW也有着相似的接口。
另外一个值得注意的是Thrust,这是一个和标准C++模板库相似的并行C++模板库,它提供了大量数据并行操作比如scan、sort、reduce等,我们可以把这些函数组合在一起来用简明可读的代码实现复杂的算法。通过用这些高抽象的函数来描述我们的算法,我们可以让Thrust自动选择最有效的实现。结果就是,我们可以使用Thrust来迅速构造cuda应用的原型,同时保证代码的表现力和鲁棒性
并行化编译器
并行化串行代码的另一种常用方法就是使用并行编译器,一般这意味着我们要使用基于指令的方法,这些方法让程序员使用#pragma或者其他类似的注解来给编译器指明哪些代码在不用修改的情况下就可以使用并行编译,然后编译器就使用相关指令来把计算映射到并行架构中
OpenACC标准提供了一系列的编译指令来把C/C++、Fortran中的循环和代码段从CPU中卸载到CUDA GPU这样的加速器中,但相关细节被隐藏在了支持OpenACC的编译器和运行环境中
并行化代码
对于那些要求现存并行库或并行编译器不能提供的函数的应用,我们可以使用并行编程语言比如cuda c/c++来把现有代码无缝转换成并行代码。一旦我们在应用分析中定位了热点代码并且确定修改代码是最好的方法,我们可以使用cuda c/c++来把我们的热点代码并行化为cuda核。而后我们可以把这个核启动到gpu上,然后在不需要对剩下代码进行大量重写的情况下获得结果。
当我们的应用运行时间大部分花在几个相对独立的部分上时,这个方法是最为直接的。相反,对于那些在不同部分上运行耗时相对平均的应用,这个方法就不太好使。对于这种情况,一定程度上的代码重构可以帮助我们提高并行性,但记住这种重构工作应该有利于所有架构的未来发展,不仅是CPU架构,也要考虑GPU架构。
得到正确的结果
所有的计算任务都是为了得到正确的结果,但是在并行系统中,我们可能遇到在串行系统中不曾遇到的问题,包括:线程问题、由于浮点值计算方法而导致的异常值、以及操作CPU和GPU方式的不同而引发的问题等,这一章将会检验这些影响返回数据正确性的问题,并指出合适的解决方法
验证
对于任何程序修改,一个正确性验证的关键方法就是建立一些机制,在这种机制中,我们可以使用之前具有代表性的输入产生的正确输出来和新的结果作比较。在每一次代码更改后,我们都要保证在某个验证机制下,使用任何评判标准都可以得到匹配的结果。有时需要实际值和预期值有位级别的相等,尽管这在使用浮点运算时就有点儿不现实。别的算法就可能要求实际值和预期值在一定范围内相等即可,也就是有一定的容错度。
上面关于验证数字结果的方法也可以被扩展到验证表现性的结果上,也就是说我们要确定我们做的每个改变不但是正确的,而且提高了表现力(有时还需要量化)。在我们的APOD循环中嵌入这些检查有助于确保我们尽快地达到预期效果
除了比较结果和表现力,我们可以微观到在代码结构中进行单元测试。例如,我们可以把很多__device__函数写成一个cuda核(而不是一个大的__global__函数),这样每个__device__函数可以在把它们整合到一起之前进行独立的测试。
例如,许多核除了作实际的计算外,还有很多复杂的取址逻辑来操作内存。如果我们在执行计算部分前就分别地测试了取址逻辑,后续的调试工作就可以被简化。注意,如果任何__device__函数没有往全局内存中写入数据的话,它就会被cuda编译器认为是可以忽略的死亡代码,因此我们必须至少把我们的取址逻辑的结果写到全局内存中,这样也可以达到调试取址逻辑的目的。
更进一步,如果函数被定义为__host__ __device__而不是只有__device__,这就意味着它在CPU和GPU上都可以被测试,从而我们可以对函数结果的正确性更有信心,因为此时异常值出现的概率会更大,修改之后代码的正确性也就更大。同时,这种声明也减少了我们程序中的重复代码,因为__host__ __device__函数可以被cpu代码和gpu代码调用,这就避免了两个函数只有声明不一样(一个是__device__,一个是__host__)的情况,从而简化代码。
调试
CUDA-GDB是GNU调试器的一部分,详情参见http://developer.nvidia.com/cuda-gdb
数字结果的准确性和精确度
不正确的数值结果主要是因为浮点数计算和存储方式导致的浮点数精度问题引发的,这一节将讲解涉及的主要方面,也可以参考CUDA C PRAGRAMMING GUIDE中Features and Technical Specfications章节
单精度和双精度
计算能力>=1.3的设备提供了双精度浮点值的本地支持,使用双精度计算得到结果通常会和使用单精度计算得到的结果不同,这是由双精度有更高的精确性以及相关的舍入而导致的。因此,我们应该比较在相同精确度下的的值,并且要有一定的容错性。
浮点运算不满足结合律
由于每个浮点运算操作都包含一定量的舍入,因此执行运算操作的顺序就格外重要。如果A,B,C是浮点数,那么(A + B) + C不能保证等于A + (B + C),因此当我们并行化计算时,一旦无意中改变操作的顺序,那么可能就会导致和串行执行截然不同的结果。这是浮点运算的固有属性,并不局限于cuda
单双精度之间的转换
当比较浮点变量在主机和设备上的运算结果时,如果出现需要在主机上从单精度转换到双精度的情况,确保这一点不会对结果产生影响。例如,如果代码float a; ....; a = a * 1.02;在计算能力<=1.2或者计算能力>1.2但没有开启双精度支持的话,乘法操作就会在单精度上执行。但是如果这段代码在主机上执行,字面量1.02就会被解释成双精度,变量a也会从单精度转换成双精度,乘法就随之会在双精度下执行,但由于a本身是单精度,因此乘法的结果又会被转换回单精度,从而可能导致结果有所不同。但是,如果把1.02改成1.02f,那么在所有情况下上面的单双精度转换就不会发生,因此在涉及单精度运算的时候,一定要使用结尾带f的字面量。
另外,单双精度之间的转换还会对性能产生不利的影响,具体请参见指令优化一章
IEEE 754
所有的cuda计算设备都遵循IEEE 754标准来表示二进制浮点数,也有一些小的例外(参见CUDA C PRAGRAMMING GUIDE中Features and Technical Specfications章节),这些例外可能会导致产生的结果和主机上严格遵循IEEE 754标准产生的结果不同
其中一个重要的区别就是乘加混合指令FMA,这个指令把乘法加法操作合并到了一条指令中,其结果经常和分别执行两条指令的结果略有不同
x86中80位的计算
x86处理器在执行浮点运算时可以使用80位的扩展双精度表示方法,其结果通常和在cuda设备上进行的纯64位运算不同。为了尽量减少差异,可以使用FLDCW x86汇编指令或者等效的系统api来将x86的CPU处理器设置成常规单双精度
优化cuda应用
当每一轮的应用并行化完成之后,我们可以转向优化应用的实现来提高性能。由于优化方法很多,正确地理解需求可以帮助我们少走一些弯路。然而,因为APOD是一个整体,项目优化也是一个迭代的过程,其中包括确认能否优化、应用优化、测试优化、验证加速是否达到这一循环。迭代,意味着开发者不必花费大量的时间尝试所有的可能的优化策略来达到好的加速效果,相反,优化策略可以随着我们的学习而被增量地应用。
优化的层面很多,包括把数据传输和计算并行处理一路向下到细粒度地微调浮点操作序列,此时优化工具就很宝贵,因为它们能对开发者下一步的优化给出建议。
结语
下一篇文章翻译第8到15章,内容会更多