背景
从这次开始,我将用数篇博客来分享前一阵我对CUDA10.0官方文档之编程指南的翻译与学习的笔记。由于内容非常多,我将每一章单独分享出来,可能有地方翻译得词不达意,所以建议大家参考原文:https://docs.nvidia.com/cuda/archive/10.0/cuda-c-programming-guide/index.html
介绍
从图像处理到通用目的的平行计算
在不知满足的追求实时性的市场的驱动下,高分辨度的3D图像、可编程的gpu已经进化成了一个高度并行化、多线程多核处理器、拥有强悍的计算马力和内存带宽的处理器,如下两张图所示
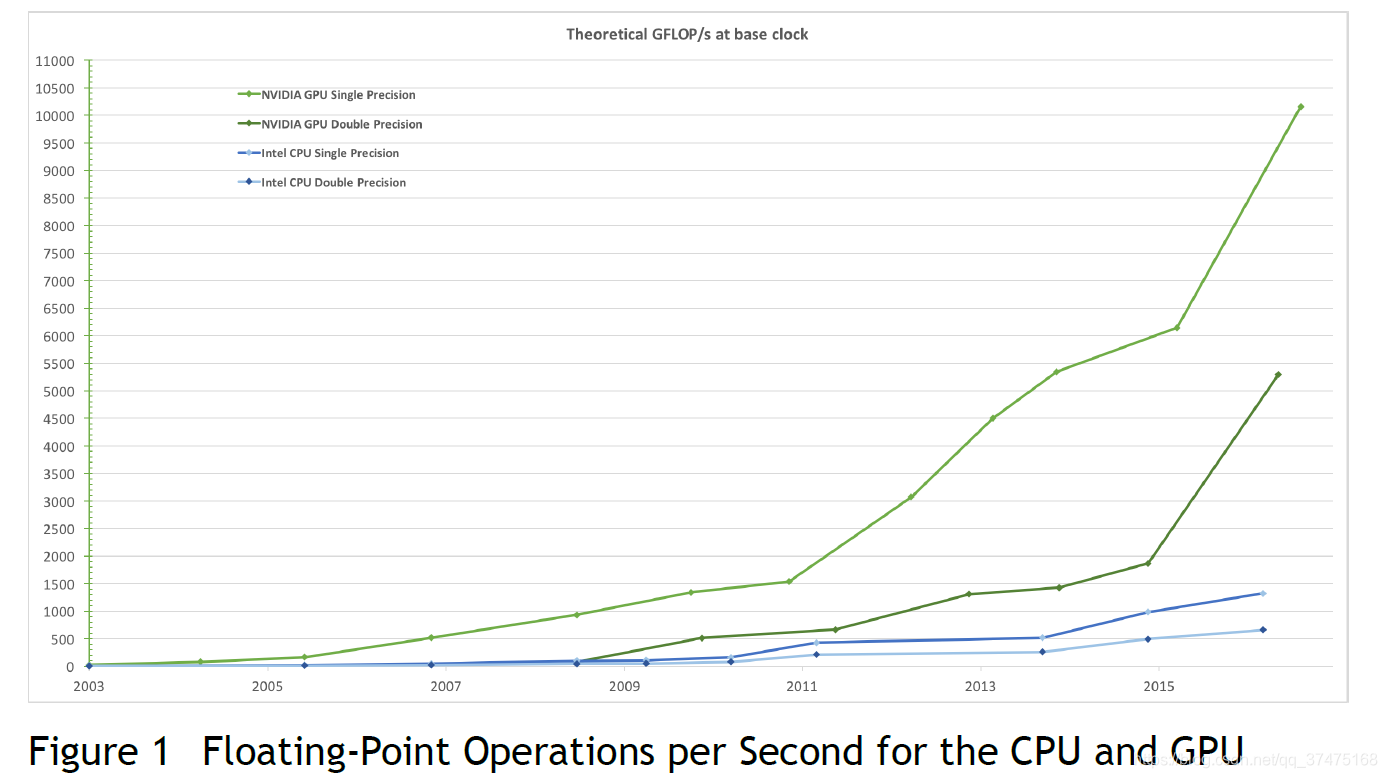
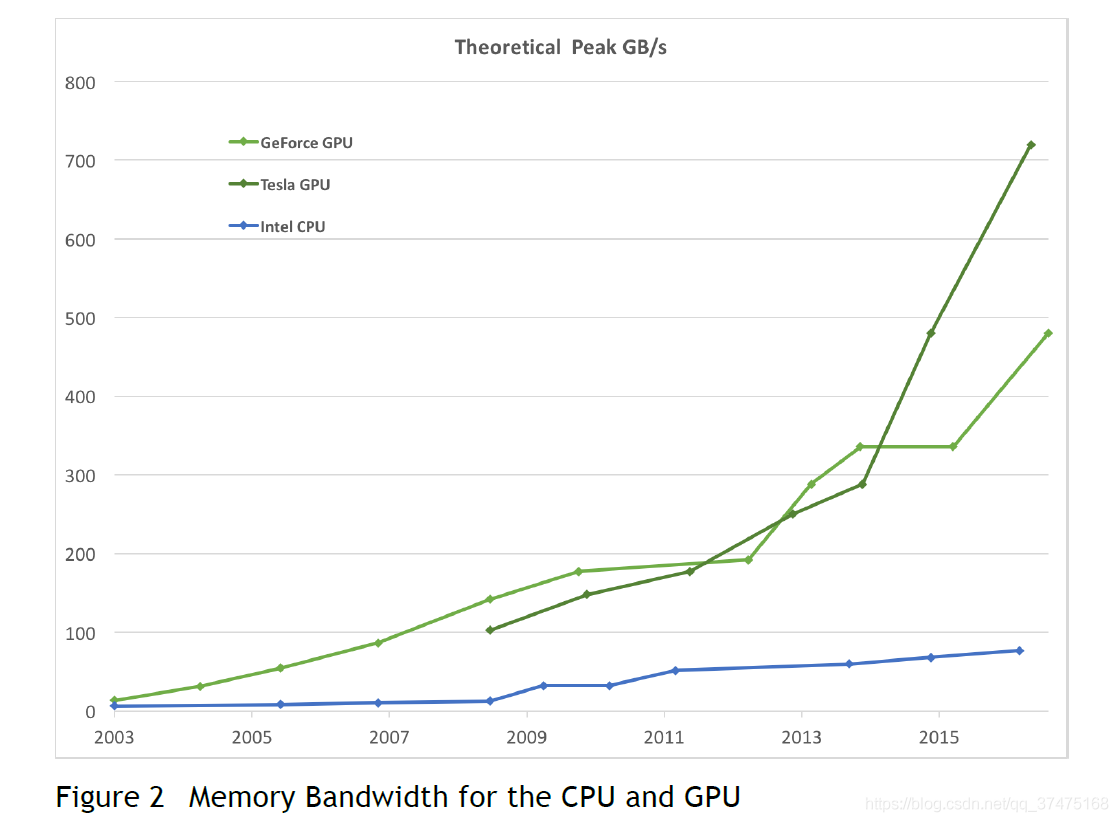
CPU和GPU在处理浮点数能力上的差异的背后原因,是GPU是专门为密集型、高并行化计算——特别是图像渲染而设计的,故而使用了更多用来做数据处理的晶体管——要比进行数据存储或流程控制的多很多,如下图所示
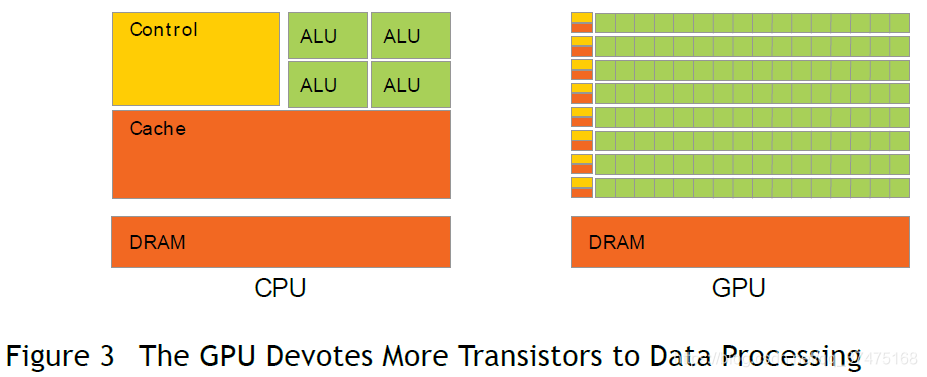
另外,GPU特别适合解决那些被称之为并行数据计算的问题,也就是要并行执行那些处理数据元素的程序,而且有着高强度的数学运算(数学运算要比内存操作多得多)。因为对每个数据元素要执行相同的程序,那么对复杂的流程控制的要求就会降低。另外,因为程序在很多的数据元素上执行,且拥有很高的运算强度,所以内存访问延迟就可以被计算而不是大的数据缓存锁隐藏。
数据并行处理把数据元素映射给了数据处理线程,很多处理大数据集的应用可以使用并行数据编程模型来加速计算。在3维渲染中,像素和边的巨大集合可以被映射给并行线程,类似地,诸如对已渲染的图像进行再加工、视频编解码、图像缩放、立体视觉、样式识别这样的数据和媒体处理应用可以把图像块和像素映射到并行处理线程上。事实上,图像渲染和处理领域之外的很多算法可以被数据并行处理加速,包括通用信号处理、物理模拟到经济计算或生物计算。
cuda:一个为通用目的产生的并行计算平台和编程模型
2006年11月份,英伟达引入了cuda,这是一个使用英伟达GPU中的并行计算引擎来用一种比在单个CPU上更有效的方式来解决很多复杂计算问题的通用计算平台和编程模型。cuda提供一个允许开发者用C语言来作为高级编程语言的软件环境,如下图所示,诸如Fortran、DirectCompute、OpenACC等其他语言、应用编程接口或者基于指令的方法也被cuda支持

可量化的编程模型
多核CPU和多核GPU的出现意味着主流处理器芯片是现在的并行平台,而且,它们的并行性服从摩尔定律。我们面临的挑战是要开发能够扩展并行度以利用越来越多的核的应用,例如3D图像应用把它们的并行度扩展到了拥有核数不一的多核GPU上。
cuda并行编程模型的设计就是用来克服这种挑战,同时用程序员熟悉的标准程序语言(例如C)来保持一个低的学习曲线。
在cuda核心中有三个关键抽象:线程组的层次、共享内存和同步栅栏,这也是面向程序员的最少的语言扩展内容。这些抽象提供了嵌套在在粗粒度的数据并行和任务并行中的细粒度数据并行和线程并行,从而引导程序员把问题分成可以通过线程或块并行解决的粗粒度子问题,并且把每个子问题进一步分成可以被块内所有线程一起并行解决的细粒度问题。
这种解构通过允许线程在解决每个子问题时合作来保留语言的表达性,同时允许自动量化。确实,每个线程块可以在GPU内任何可调度的处理器上以任何顺序并发或串行执行(如下图所示),并且只有运行时系统需要知道物理处理器数量
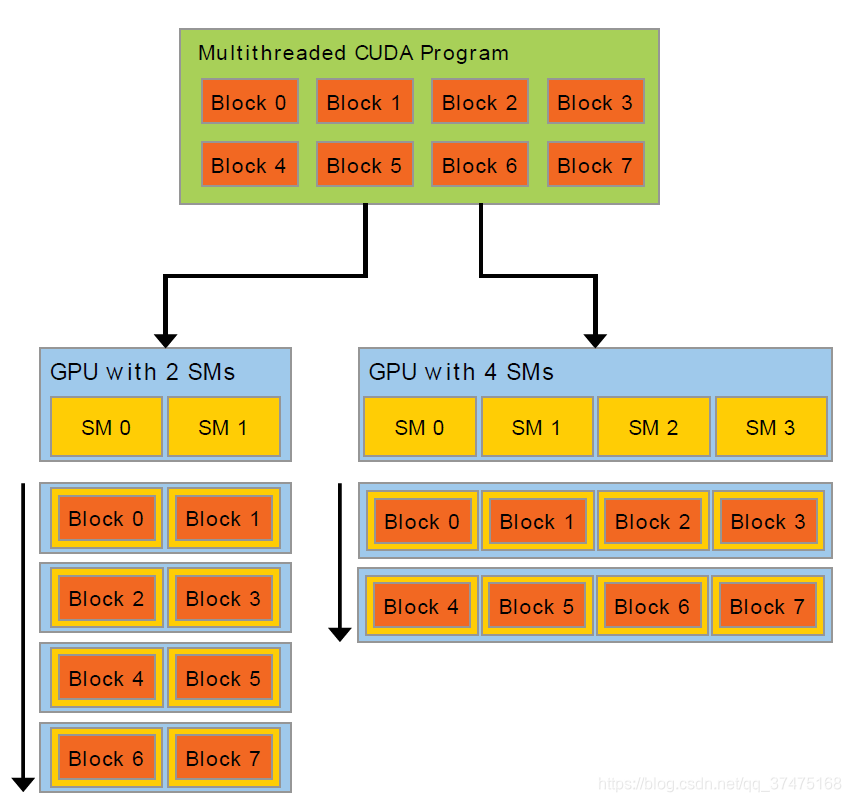
这种可量化的编程模型允许GPU架构通过缩放处理器的数量和内存分区来跨越宽泛的市场范围:从高性能爱好者的GeForce到专业的Quadro和Tesla计算产品到各种便宜的主流GeforceGPU。
结语
以上就是CUDA10.0官方文档的第一章内容,从中我的思考如下:
1、GPU中大部分晶体管都是用来ALU,所以它不擅长复杂的逻辑控制,而是擅长运算,这正与CPU互补。所以我们开发时应该各尽其能,让CPU处理逻辑判断,然后让GPU处理运算;
2、CUDA的接口都是C或C++写的,所以我们必须提前掌握C或C++,不过相信科班出身的应该对这俩都不陌生;
3、CUDA可以对很多计算密集型的应用进行加速,这些应用可以参见《CUDA高性能计算》一书中的例子,里面涉及用CUDA实现的手电筒应用、热力可视化、振荡器等应用,大体逻辑都是UI渲染部分交给OpenGL,而运算部分交给CUDA。
下一章将会介绍CUDA的编程模型,包括线程视图的层次、内存层次、核函数以及异构编程