这文档堪称CUDA官方手册里最有用TOP3了。
ps:全文翻译会累死猿哒,意译意译,各位看官凑合一下啦
前言
文档的作用
这文档能干嘛,是用来帮助开发者从NVIDIA GPU上获取最好的性能的。建议顺序阅读,这文档将会极大地提升你对程序效率的理解。
面向的对象
你要懂C,还要安装了CUDA,从这安装。最好还能看看《CUDA C Programming Guide》这份文档。(这个文档的一大特点就是,篇幅不够的就让你去看那个Programming Guide)
评估,并行,优化,实施
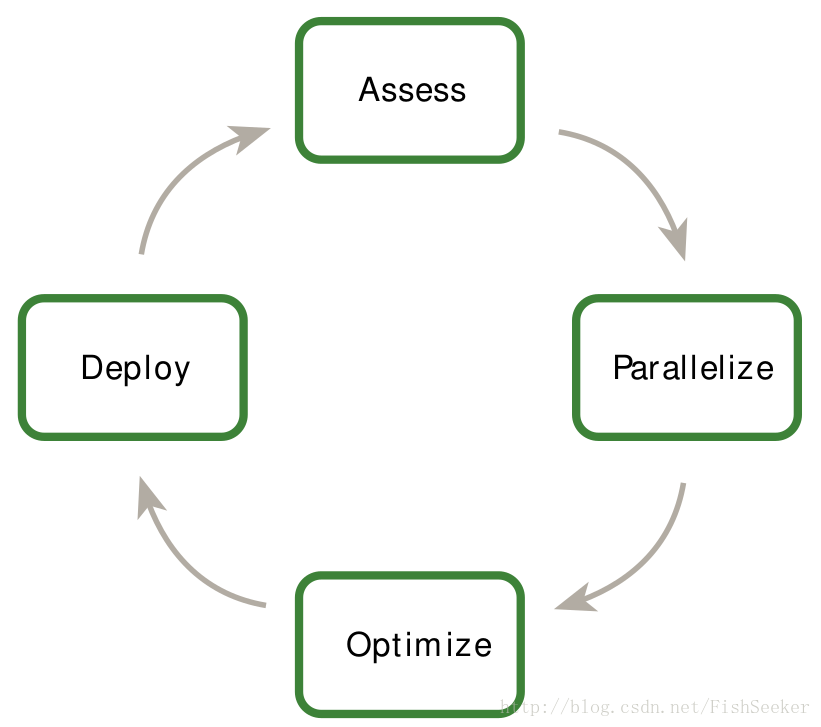
这个图就是整篇文档的中心了(APOD),首先你要评估你的程序,初始的加速将被实现,测试,并且在最小化的优化下运行,这个循环可以一次又一次地运行,通过再次发现优化机会,再次加速然后运行更快的版本。
评估
对于一个现有的项目,第一步就是评估这个应用来定位和大部分执行时间相关的部分。学会这个,开发者就能估计并行程序的瓶颈并可以加速GPU。需要理解Amdahl’s 和 Gustafson’s laws。
并行
确定了痛点之后,开发者需要并行化程序。可以使用现有的并行化库或者在编译器那增加并行标志。但是许多程序需要重构才能并行而CUDA让这件事变得容易。
优化
当并行化完成之后,开发者可以将注意力集中在优化。首先要明确应用的需求,在迭代中优化并实施程序,并不需要在一开始就要提升很大速度。而且,优化可以从不同的级别开始,从重叠计算与数据传输到细粒度的浮点数操作,同时分析工具能够帮你提供下一步优化的方向。
实施
优化之后要将实际结果和期望结果比较,再次APOD循环。在进行更深度的优化之前,先把当前的程序部署起来,这样有很多好处,比如允许使用者对当前的应用进行评估,并且减小了应用的风险因为这是一种循序渐进的演化而不是改革。
建议和最佳实践
这个文档对于优化有个优先级的评价,确保在较低优先级优化进行之前,完成了所有的高级优化。当然这种优先级不是绝对的,文档只是提供普通的情景。
1.评估应用
bulabula瞎扯,说明并行计算的重要性。为了适应现代的处理器,包括GPU,第一步最重要的就是要识别出程序痛点,确定是否它能够被并行化。
2.异构计算
虽然GPU主要用来处理图像,但是它的计算能力也很强。CPU和GPU是不一样的,要想高效地使用CUDA了解它们之间的不同很重要。
2.1 主机和设备之间的差别
线程资源
CPU的线程很少(也就几十个),而GPU的线程有上万个。
线程
CPU上的线程是庞大的实体,上下文切换对于它们来说耗时很多,而GPU则相反,因为GPU有很多寄存器分配给线程。简单来说,CPU是设计来让少数线程的运行达到最小时延,而GPU是让大量线程达到最大吞吐量。
内存
它们都有各自的内存,并和PCIe总线连接。
这就是关于两者不同的初步讨论,其他的不同,将在文档的其他部分相继讨论,知道这些不同有助于你的优化工作:尽量在主机上运行顺序工作在GPU上运行并行的工作
2.2. 哪部分应该在GPU上运行
- 显然是个大规模做相同运算的数据集。这需要很多的线程
- 使用的数据具有很好的一致性的模式的,否则会导致加速比小
- 主机与设备之间的数据传输要做到最小。
- 给很少的线程传递数据是没有必要的。比如传入俩N×N的矩阵,算了和再传回去。这里有N^2的计算量但是要传输3N^2数据,比例是1:3或者说是O(1),但是要是算乘积的话,就是O(N),这样就比较好了。或者那些比较复杂的运算比如三角函数之类的。反正记着传输数据是有开销的对了
- 数据要尽可能的保留在设备上。在两个Kernel之间,数据要尽可能保存在数据上。比如上面那个两个矩阵相加,可能在运算完之后还会被用于以后的操作,所以要留下。如果有这种情况,数据要被放在GPU上运行,就算是它可能在主机上运行更快。一个比较慢的Kernel可能会因此收益,第九章会详细讲解。
3. 程序分析
3.1. 分析
很多程序用很少的代码完成了大部分的工作。使用分析器,开发者能够发现这样的点并且列出一个并行可能的列表。
3.1.1. 创建一个分析
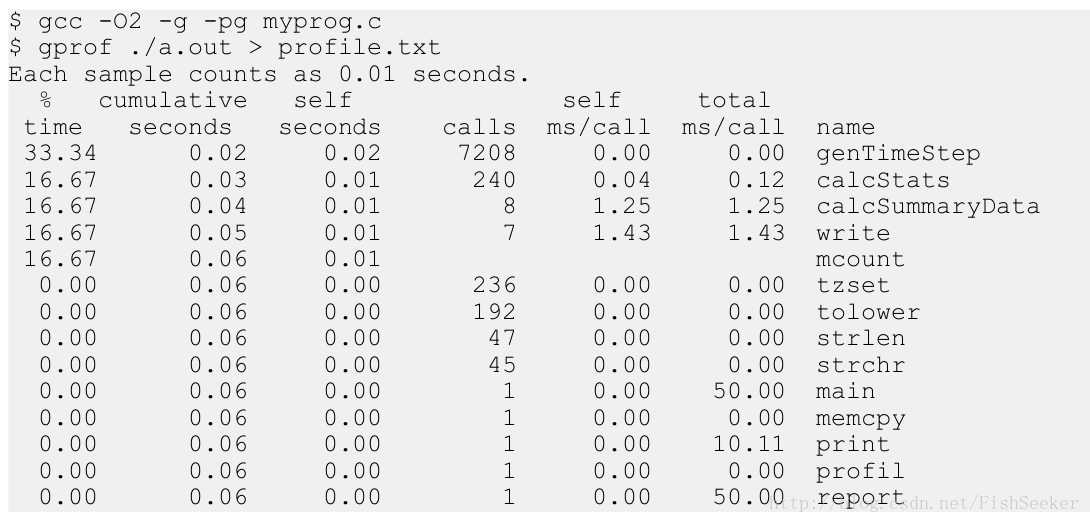
最重点的就是,要找出执行时间最长的函数。而分析程序的最重要的是要确保工作负载和现实相似。可以使用gprof来测试:
3.1.2. 分析痛点
从上面的图我们就能看出来,genTimeStep()这个函数花了几乎总时间的三分之一,这就是我们应该优化的函数。而且可以看出其他的函数也占用了一大部分时间比如:calcStats() 和calcSummaryData()。并行化这些函数也可以加速程序,不过,要慢慢来嘛。
3.1.3. 认识哪部分能并行
想要从CUDA中获得最大的性能提升,首先就要找到并行化现有串行代码的方法。
3.1.3.1. 强标度与Amdahl定律
这里这俩就请看这里吧:并行计算中的Amdahl与Gustafson定律
Amdahl就是看看你的并行部分就算达到最完美了(运行时间是0),那你的程序到底能加速多少。
3.1.3.2. 弱标度与Gustafson定律
Gustafson定律就是假定串行和并行执行的比率保持不变,反映了设置和处理较大问题的额外成本。(其实木有太搞懂)
3.1.3.3. 实现强/弱标度
要知道那种标度适合你的应用程序,对于有些程序来说问题规模是一定的例如两个分子之间的作用力而另外一些问题规模会随着处理器的增加而增加例如流体的蒙特卡罗模拟,大的工作量能够提供大的精度。
4. 并行化程序
确定了痛点之后,开发者需要并行化程序。可以使用现有的并行化库或者在编译器那增加并行标志。但是许多程序需要重构才能并行而CUDA让这件事变得容易。
5. 开始
虽然对于特定的应用实现并行是复杂的,但是有一些关键步骤是需要的。
5.1. 并行库
CUDA提供了一些并行库比如cuBLAS , cuFFT之类的。如果和需求比较符合,用这些库十分方便。除了做线代的cuBLAS库,做傅里叶变换的cuFFT,特别强调Thrust模板库。这个库包含了很多常用的并行算法,可以结合它完成复杂的算法。可以用它来快速完成一个CUDA应用的原型机。
5.2. 并行编译器
这是通过设置特殊的标记,让编译器把代码并行话的方式。比如在展开操作中使用的#progra unroll这个标记。OpenACC提供了很多这样的指令。猛戳这里去OpenACC的官网
5.3. 用代码实现并行
除了上面那些现成的方法外,当然还是需要程序猿自己手动敲代码了。我们可以把找到的痛点自己重新写成并行的。当我们测试发现,很多函数占用的时间都差不多的时候,这就需要我们重构这个代码,而且你要知道,将代码重构成并行的对于未来的架构是有好处的,因此这个工作是值得的。
6. 获取正确答案
在并行程序里并不好找到错误,因为它线程太多了,而且浮点数计算等都有可能造成意想不到的错误。这一章就介绍那些可能导致错误的点并且告诉你如何解决。
6.1. 验证
6.1.1. 对比参考
首先就要比较新结果与参考结果,确定结果与适用于任何算法的标准相匹配。有些计算想要每位都相同的结果,但是并不总是可能,特别的计算浮点数的时候。值得注意的是,那些被用于验证数值结果的方法很容易就延伸到验证结果性能上去。我们既要确定结果正确,又得让效率上升。
6.1.2. 单元测试
为了好测试,我们可以把Kernel函数写成很多个device函数的组合而不是一个大的global函数。(这里要注意的是,如果你对全局内存什么也不做,你的编译器会认为你的部分代码是dead code给你去掉,因此,一定在测试的时候做点什么)另外,如果使用host device来定义而不是只用device来定义,那这个函数就能够在CPU上测试,这可以给我们增加测试的自信。
6.2. 调试
可以使用CUDA-GDB,这个我也写过,详情见这里:使用cuda-gdb调试cu程序
或者用NVIDIA Parallel Nsight来调试:http://developer.nvidia.com/nvidia-parallel-nsight
以及一些第三方调试器:http://developer.nvidia.com/debugging-solutions
6.3. 数值精度
大多数浮点数精度的错误都源于浮点数计算和存储的方式。提供一个网站:floating-point precision
6.3.1. 单精度VS双精度
计算能力1.3以上的设备都提供双精度浮点数计算。相比于单精度可以获得更大的精度。要在使用的时候注意。
6.3.2. 浮点数计算不是可结合的
这个就是说在浮点数中(A+B)+C和A+(B+C)的值不一定相同,所以要注意可能你换了换操作数的位置,就让结果不在正确,这个问题不仅存在于CUDA中,任何并行浮点数计算的系统都有可能出现这样的问题。
6.3.3. 把双精度转换成单精度
比如
float a;
...
a = a*1.02;这段代码在GPU上计算,就会是单精度的,但是跑到主机上运算就会将1.02转换成双精度然后所有的结果都变成了双精度的了,这样结果就会有差异。而我们把1.02变成1.02f就能固定为单精度浮点数了。
6.3.4. IEEE 754 标准
所有CUDA设备都遵循IEEE 754 标准,除了某些特殊情况,这些不同要看Features and Technical Specifications of the CUDA C Programming Guide
6.3.5. x86 80-bit 计算
x86机器还能进行80位的浮点数计算,这个和64位的计算有所不同。要获得比较相近的结果,尽量别让x86搞这个飞机。是用FLDCW这个指令操作。
7. 优化CUDA应用
当并行化完成之后,开发者可以将注意力集中在优化。首先要明确应用的需求,在迭代中优化并实施程序,并不需要在一开始就要提升很大速度。而且,优化可以从不同的级别开始,从重叠计算与数据传输到细粒度的浮点数操作,同时分析工具能够帮你提供下一步优化的方向。
8. 性能检测
想要优化代码,知道怎么精确测量而且知道带宽在优化中所扮演的角色十分重要。这章主要就将这俩内容。
8.1. 测时
8.1.1. 使用 CPU 计时器
详细介绍CPU计时并不在本文的讨论范围之内,但是一定要知道存在这种方法。一定要主义,要让CPU和GPU事件同步发生,可以调用cudaDeviceSynchronize()这个函数,能够阻塞CPU线程直到GPU完成工作。虽然也有能够将CPU和流同步的代码,但是不适用于计时,因为流通常是交错执行的。一定要注意,这种计时的方式会让GPU的流水线操作停滞,所以要尽量减少使用。
8.1.2. 使用CUDA GPU计时器
使用CUDA提供的API就能计时:

cudaEventRecord()将start和stop放入默认流中。设备将记录一个时间戳当流到达这个事件的时候。cudaEventElapsedTime()就是返回start和stop的时间差。
8.2. 带宽
8.2.1. 计算理论带宽
只需要知道GPU的时钟频率和位宽。比如:1.85GHz和384位,双倍数据速率。是这样计算的:
(1.85*10^9*(384/8)*2)/10^9 = 177.6 GB/s
这是啥子原理嘞:首先把GHz转换成Hz,然后384/8是换成字节,×2是双倍数据速率,/10^9是转换成GB。
8.2.2. 计算实际带宽
公式:((Br+Bw)/10^9)/time
就是实际的传输数据除以时间。比如有2048*2048矩阵传输就要这么计算:(2048×2048×4×2)/10^9/time
4是一个数四个字节,2是读写。
8.2.3. 使用Visual Profiler检测吞吐量
在计算能力2.0或者更高的设备上,Visual Profiler能够提供不同内存的吞吐量信息。包括:
- Requested Global Load Throughput
- Requested Global Store Throughput
- Global Load Throughput
- Global Store Throughput
- DRAM Read Throughput
- DRAM Write Throughput
其中requested是Kernel对于数据的请求。
最后,实际的吞吐量和请求的吞吐量都有用。前者可以让你看到你的代码能达到硬件的多少效率,而后者通过与前者的比较可以看到聚合操作中有多少内存被浪费。对于全局内存,这个数据由Global Memory Load Efficiency和Global Memory Store Efficiency 显示。