
分享嘉宾:于恒 博士 阿里达摩院
文章整理:刘翔宇
内容来源:DataFunTalk·年终论坛
出品平台:DataFun
注:欢迎转载,转载请在公众号后台留言。
导读:大规模预训练的提出对整个自然语言处理领域产生了较大的震动,几乎推动了所有子领域 state-of-the-art 的性能,均上升了一个档次,较多榜单已被刷榜。为什么在这些场景中没有机器翻译 ( MT ) / 自然语言生成 ( NLG ) 任务?训练神经网络过程中,通常是通过 t-1 时刻的 ground truth 来预测 t 时刻的输出,会涉及到暴露偏置 ( Exposure Bias ) 问题。在训练时有 ground truth,但在实际推断 Inference 时没有 ground truth。如何平衡训练和 Inference 两者差异性?需要提出更好的训练框架。
本次分享题目为大规模预训练模型在阿里机器翻译中的应用,主要从以下3个方面介绍:
- 预训练模型介绍及机器翻译的挑战
- 提出创新的 Framework,很好的融合机器翻译和预训练的模型:APT Framework
- 专门为机器翻译设计了一种创新的捕捉全局信息的网络结构:GRET
2个工作均被 AAAI2020 接收。
01
背景介绍
1. 简介
大规模预训练的提出对整个自然语言处理领域产生了较大的震动,几乎推动了所有子领域 state-of-the-art 的性能,均上升了一个档次,较多榜单已被刷榜。通过从大规模无标注语料中学习知识,并用复杂网络进行建模,然后对下游任务微调来适应,这种方式已成为近期研究热点。较著名的模型有 ELMo、GPT、BERT、ERNIG 等,有趣的是它们都是美国著名儿童节目《芝麻街》里的卡通人物,ELMo 作者将模型起了一个容易被记住的卡通人物名字献给3岁的儿子,后续模型作者为了致敬前人故沿用了这种命名体系。
2. 代表性的预训练模型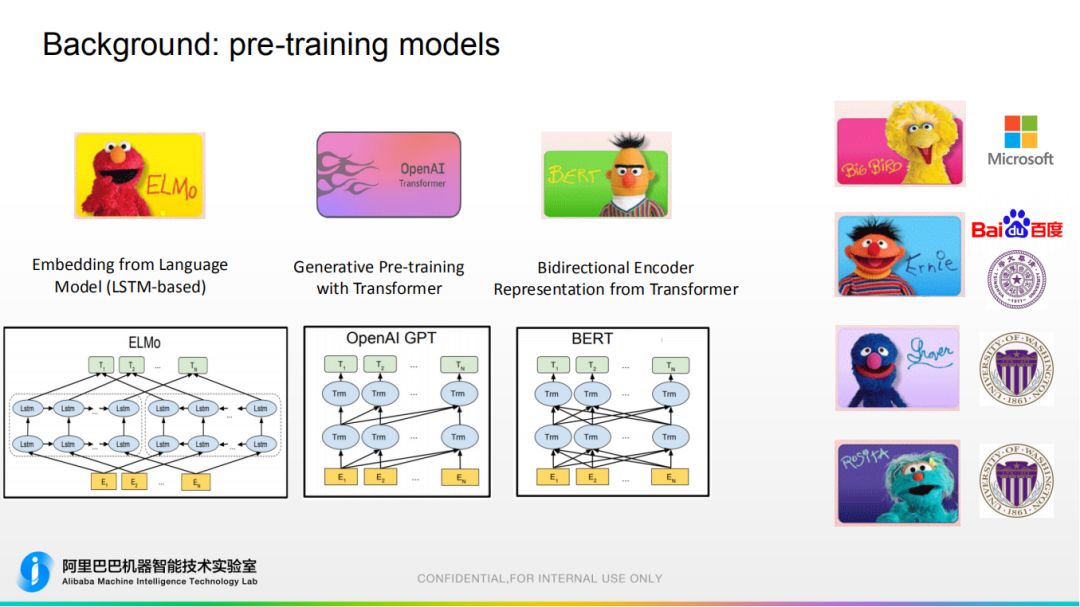 ELMo:最早提出,通过 lstm 网络对语言模型任务建模,即通过前文来预测下一个词或前一个词。因为采用双向 lstm 建模,故每个词有两个 hidden states,把两个隐藏状态拼接之后就得到 language embedding,对于同一个词上下文不同它的 embedding 也不同。
ELMo:最早提出,通过 lstm 网络对语言模型任务建模,即通过前文来预测下一个词或前一个词。因为采用双向 lstm 建模,故每个词有两个 hidden states,把两个隐藏状态拼接之后就得到 language embedding,对于同一个词上下文不同它的 embedding 也不同。
OpenAI GPT:基本原理和 ELMo 相似,区别在于使用 Transformer 建模。
BERT:由谷歌提出,采用双向 Transformer 建模,可以同时看到左边和右边的词,并且提出 mask language model,next sentence prediction 等新方法,来将整个水平提高到新档次,为目前较主流模型。
其他:另外有一些 follow up 的工作,如微软 Big Bird,百度和清华的 ERNIE 等。
3. 模型应用领域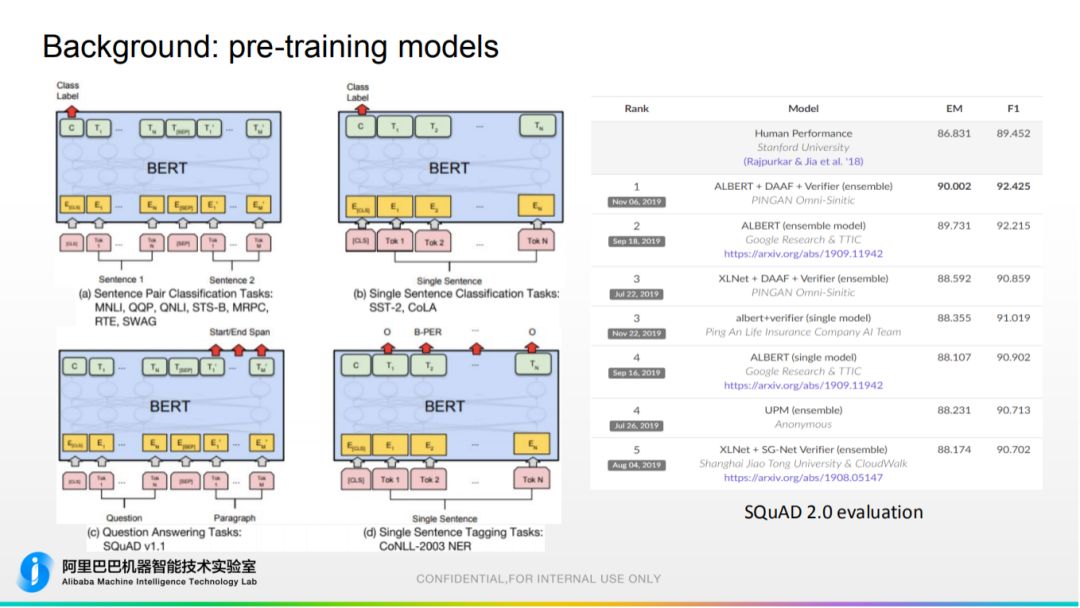 sentence classification:句子类目预测、QA 场景、命名实体识别和链接等。
sentence classification:句子类目预测、QA 场景、命名实体识别和链接等。
最新阅读理解 SQuAD 评测榜单,还是 BERT 变种优势较大,且最高分已显著超越人类。
问题:为什么在这些场景中没有机器翻译 ( MT ) / 自然语言生成 ( NLG ) 任务?
02
在机器翻译上使用预训练模型的挑战 在机器翻译上使用预训练模型面临的挑战有:
在机器翻译上使用预训练模型面临的挑战有:
- 小白:机器翻译模型最早应用 Transformer 的任务,已经非常成熟。而 BERT 也是基于 Transformer,所以在机器翻译中没有太多性能增益。虽然较片面,但我们要思考,预训练模型解决了机器翻译的什么核心问题?
- 初级:预训练模型只在单语的领域,而在机器翻译双语领域不适用。提出要求:如何从单语扩展到双语?
- 较成熟:从训练目标角度,预训练模型大多以语言模型为优化目标,但机器翻译有自己的优化目标,故两者差距较大。
如何融合不同任务?对预训练提出更高的要求。
- 本质:训练神经网络过程中,通常是通过 t-1 时刻的 ground truth 来预测 t 时刻的输出,会涉及到暴露偏置 ( Exposure Bias ) 问题。在训练时有 ground truth,但在实际推断 Inference 时没有 ground truth。如何平衡训练和 Inference 两者差异性?需要提出更好的训练框架。
03
2个工作
今天主要分享我们在机器翻译上的2个工作,2个工作均被 AAAI2020 接收:
- 提出创新的 Framework,很好的融合机器翻译和预训练的模型;
- 专门为机器翻译设计了一种创新的捕捉全局信息的网络结构。
04
APT Framework
1. 动机 前面提到预训练模型在 NLP 很多领域均取得成功,说明:
前面提到预训练模型在 NLP 很多领域均取得成功,说明:
- 从预训练模型提取的上下文信息对语言理解有益。
- 预训练模型由大规模单语料学习的,而这些语料通常在机器翻译领域被忽略,因为机器翻译主要利用平行双语料来训练,因此它俩在知识结构中是很好的补充,motivation 正确。
但是,在机器翻译领域中对预训练的增益还是有很多质疑,简单的融合效果并不好。
2. APT Framework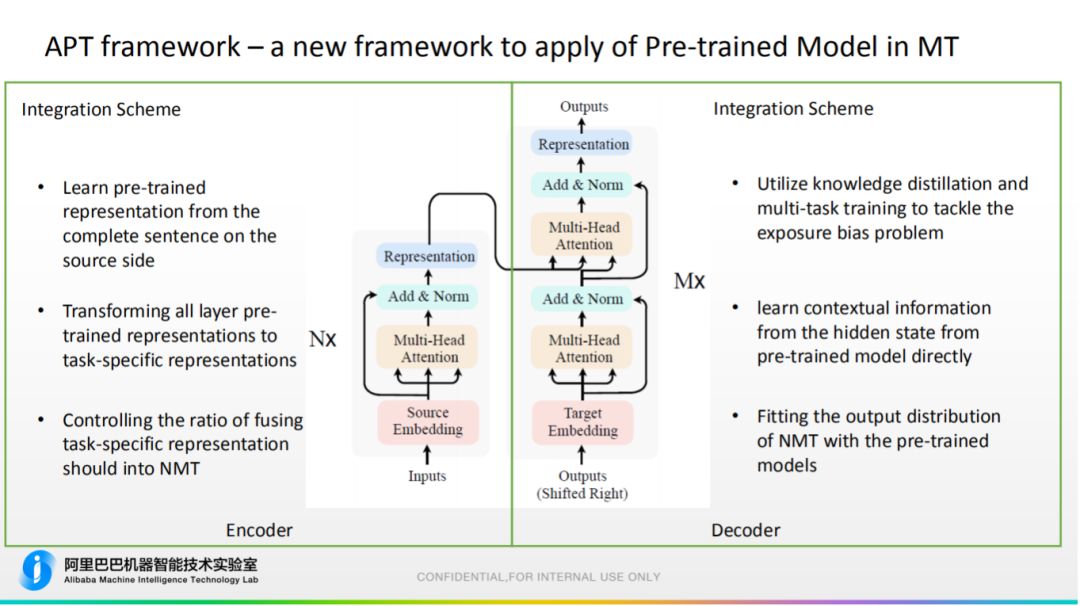 为此,我们提出 APT framework,一种新型的融合方式。主要的思路:
为此,我们提出 APT framework,一种新型的融合方式。主要的思路:
Encoder 端:可以一直完整的得到单句的输入,所以可以直接使用预训练模型来计算 Embedding。要注意的是,预训练的 Embedding 和机器翻译的目标不同,故需要将其转换成相关的 Embedding;机器翻译也产生 Embedding,需要在这两种 Embedding 间控制它们信息融合的比例。
Decoder 端:神经机器翻译是自左向右生成翻译的,故目标端没有完整的 ground truth 供预训练模型计算 Embedding,为了解决暴露偏置问题,需要使用知识蒸馏和多任务学习来解决。好处是能直接从预训练模型隐藏学习知识,同时可以让机器翻译的概率分布去拟合预训练的概率分布。
3. 方法
具体来说,提出两种机制:
① 动态融合机制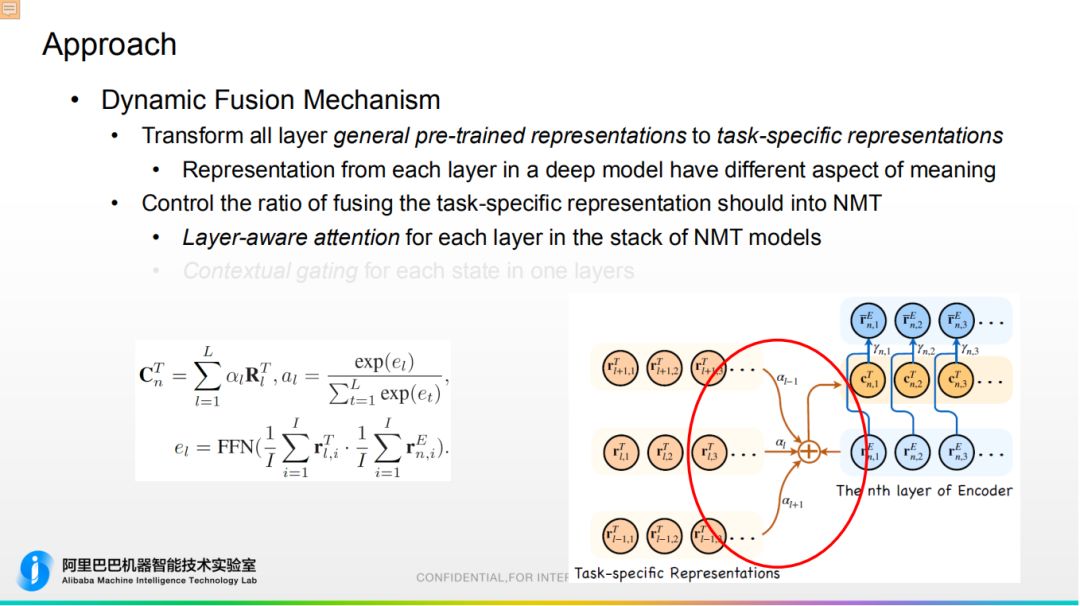 a. 目的是将预训练模型转换成任务强相关表示,如图所示,我们设置一组和任务相关参数,会跟随整个任务进行微调,使预训练 Embedding 更加适应特殊的任务。
a. 目的是将预训练模型转换成任务强相关表示,如图所示,我们设置一组和任务相关参数,会跟随整个任务进行微调,使预训练 Embedding 更加适应特殊的任务。
b. 控制机器翻译 Embedding 和预训练 Embedding 融合的比例:
- 提出层级 Attention 机制。机器翻译 Embedding 和预训练 Embedding 是多层结构,底层基于词级别,高层是语义信息。故通过层级 Attention 对预训练 Embedding 进行整合,整合之后再输入都 Transformer 对应的层当中,通过此方式区别层与层之间的语义关系。
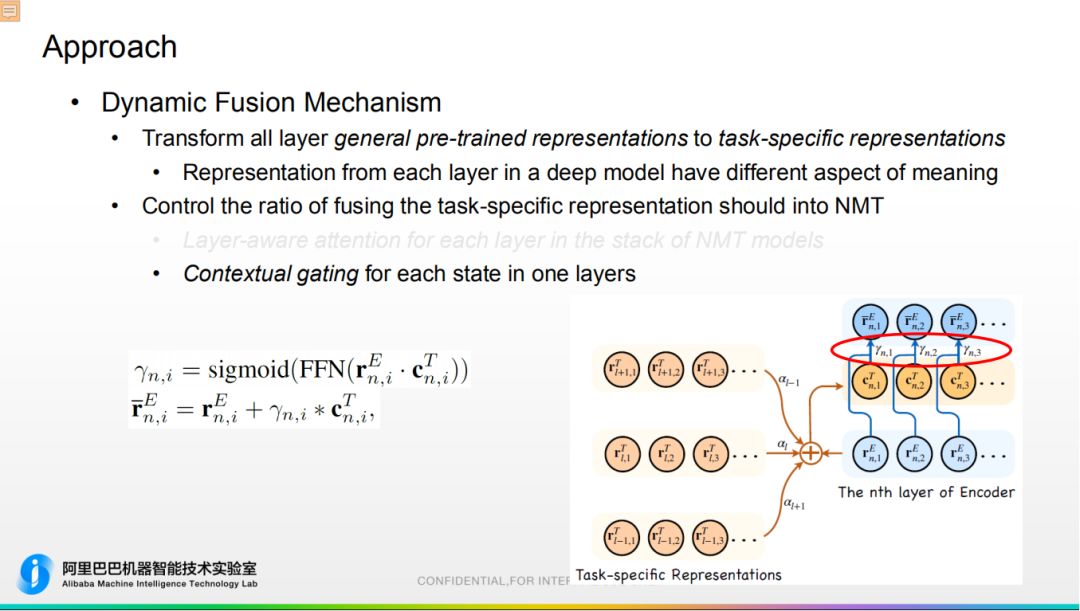
- 基于上下文文献机制。通过门限方式将机器翻译 Embedding 和预训练 Embedding 融合在一起。
② 知识蒸馏机制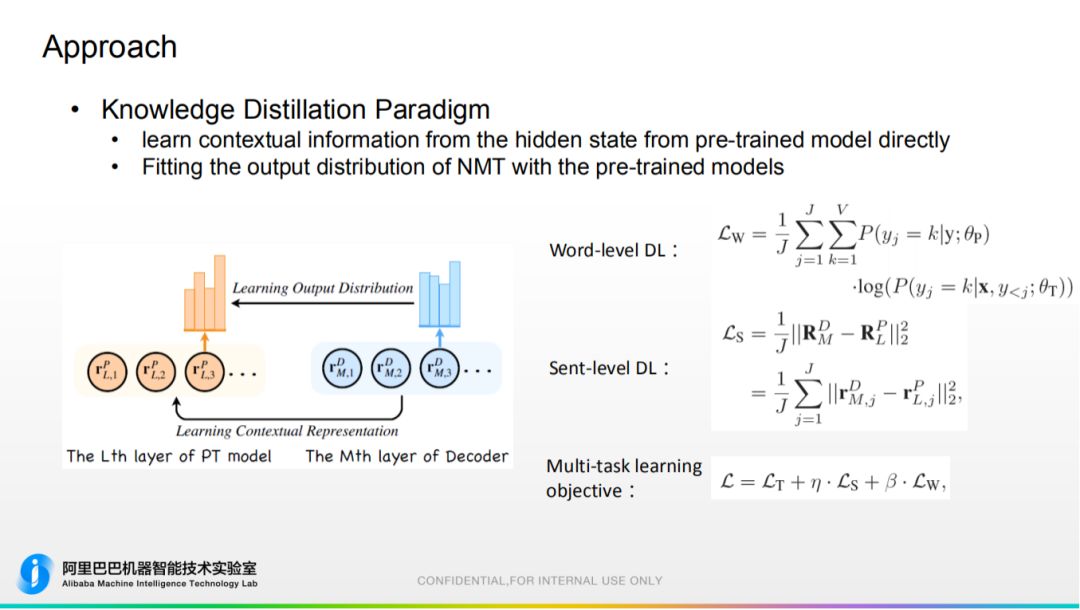 方便从预训练隐层学习信息,让机器翻译的概率分布去拟合预训练的概率分布。包括词级别蒸馏、句子级别蒸馏,最终通过多任务训练框架将以上两个训练目标和机器翻译优化目标放在一起进行多任务学习。
方便从预训练隐层学习信息,让机器翻译的概率分布去拟合预训练的概率分布。包括词级别蒸馏、句子级别蒸馏,最终通过多任务训练框架将以上两个训练目标和机器翻译优化目标放在一起进行多任务学习。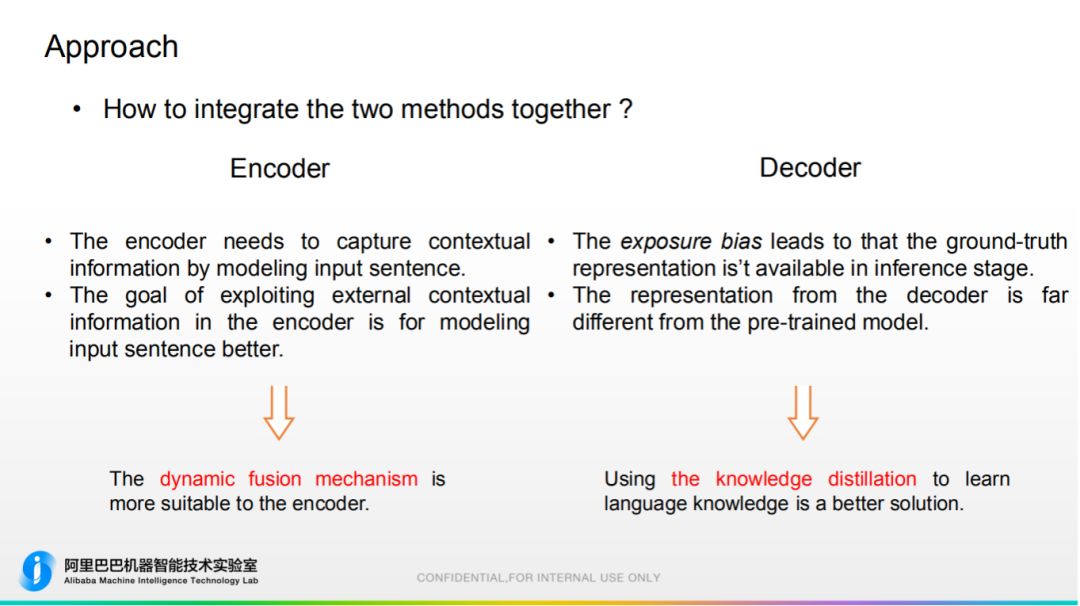 在 Encoder 端使用动态融合,在 Decoder 端使用知识蒸馏。4. 实验效果
在 Encoder 端使用动态融合,在 Decoder 端使用知识蒸馏。4. 实验效果 数据:公开 WMT 数据,中到英,英到德语料上实验。5000万训练语料。重现了 GPT、BERT、MASS 等强相关的工作。
数据:公开 WMT 数据,中到英,英到德语料上实验。5000万训练语料。重现了 GPT、BERT、MASS 等强相关的工作。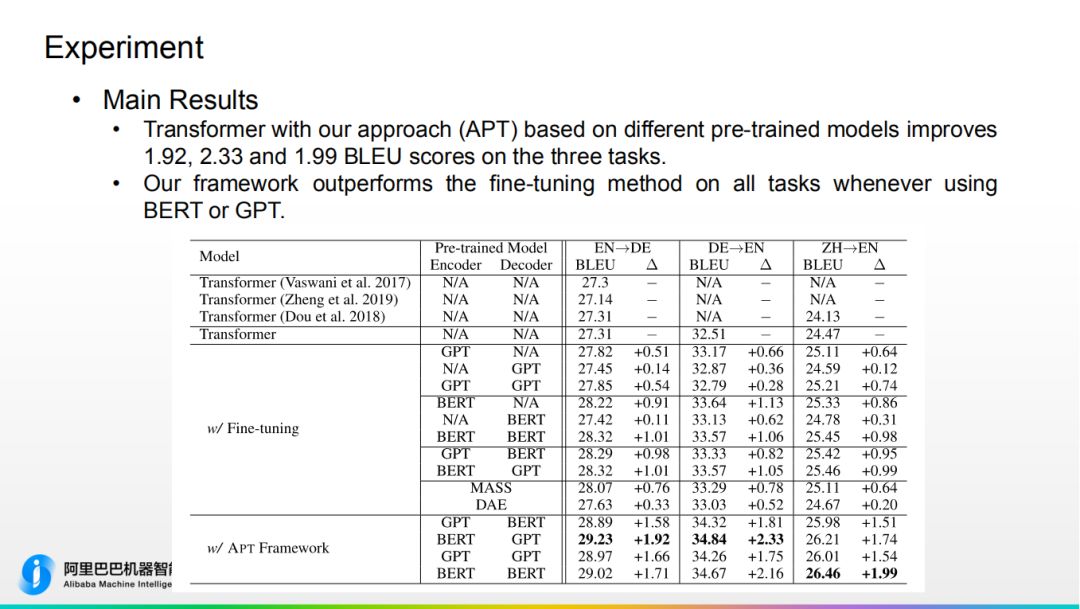 APT Framework 在三个语言任务上分别提升1.92,2.33,1.99,其中源端为 BERT 效果最好。
APT Framework 在三个语言任务上分别提升1.92,2.33,1.99,其中源端为 BERT 效果最好。
5. 对比其他工作 ① 如果直接在 Transformer-big 上加 BERT,翻译质量会下降0.76② 参数量小很多
① 如果直接在 Transformer-big 上加 BERT,翻译质量会下降0.76② 参数量小很多
6. Ablation study 有意思的是,在 Encoder 端可以使用动态融合、知识蒸馏两种方式,如果单用都有提升,但一起用效果没有进一步增加。我们认为动态融合是直接把信息告诉给 Encoder,知识蒸馏教你怎么学,所以这两种有重叠。Decoder 端用动态融合方式几乎没有作用,而使用知识蒸馏方式有提升。同时,我们在阿里巴巴大规模语料上也进行了实验,说明此方法有一席之地。
有意思的是,在 Encoder 端可以使用动态融合、知识蒸馏两种方式,如果单用都有提升,但一起用效果没有进一步增加。我们认为动态融合是直接把信息告诉给 Encoder,知识蒸馏教你怎么学,所以这两种有重叠。Decoder 端用动态融合方式几乎没有作用,而使用知识蒸馏方式有提升。同时,我们在阿里巴巴大规模语料上也进行了实验,说明此方法有一席之地。
7. 结论 我们提出了一个 APT 模型,能够将预训练模型和机器翻译模型很好的融合,并且在3个主要任务上取得了不错的提升。
我们提出了一个 APT 模型,能够将预训练模型和机器翻译模型很好的融合,并且在3个主要任务上取得了不错的提升。 简单来说就是,直接用"芝麻街"的预训练效果不好,而加上 APT Framework 效果就很好。
简单来说就是,直接用"芝麻街"的预训练效果不好,而加上 APT Framework 效果就很好。
05
GRET
GRET: Enhancing Transformer with Global representation第二个工作是我们提出创新的捕捉全局表示的方式来服务于 Transformer。
1. 背景和动机 从预训练模型学到的上下文信息对翻译有帮助,反过来说就是,Transformer 在捕捉上下文信息是有缺陷的,所以我们的 motivation 就是提高 Transformer 捕捉全局信息的能力。
从预训练模型学到的上下文信息对翻译有帮助,反过来说就是,Transformer 在捕捉上下文信息是有缺陷的,所以我们的 motivation 就是提高 Transformer 捕捉全局信息的能力。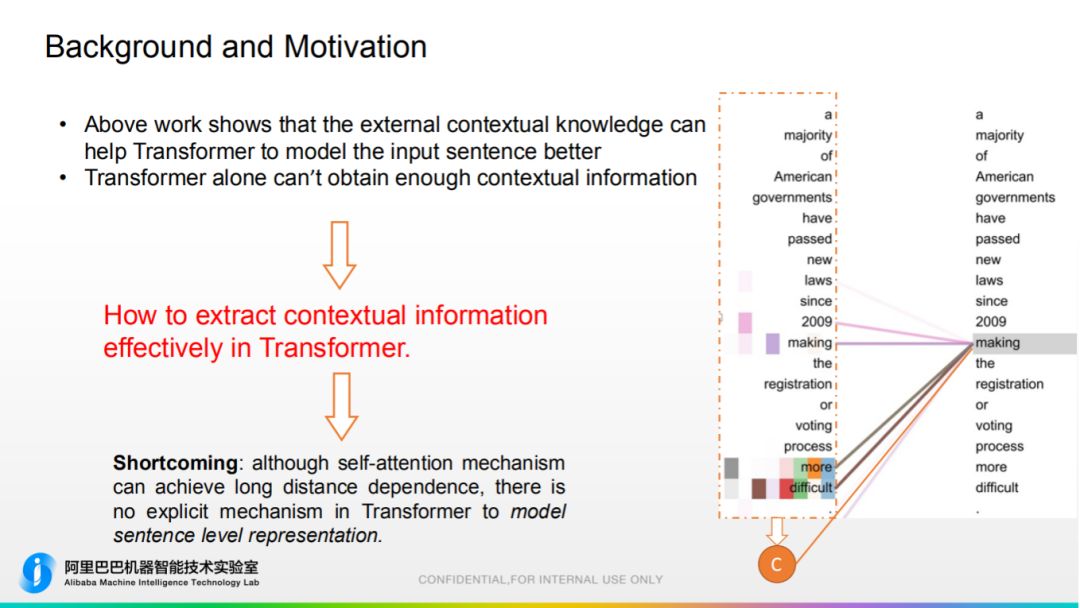 self attention 和词对齐的分布比较像,尽管可以捕捉长距离的依赖,但它还是基于局部 ( local ) 信息的捕捉方式。对句子级别的表示信息比较缺乏,它缺乏一种看到句子全局信息,生成表示 C,然后再作用于后面操作。
self attention 和词对齐的分布比较像,尽管可以捕捉长距离的依赖,但它还是基于局部 ( local ) 信息的捕捉方式。对句子级别的表示信息比较缺乏,它缺乏一种看到句子全局信息,生成表示 C,然后再作用于后面操作。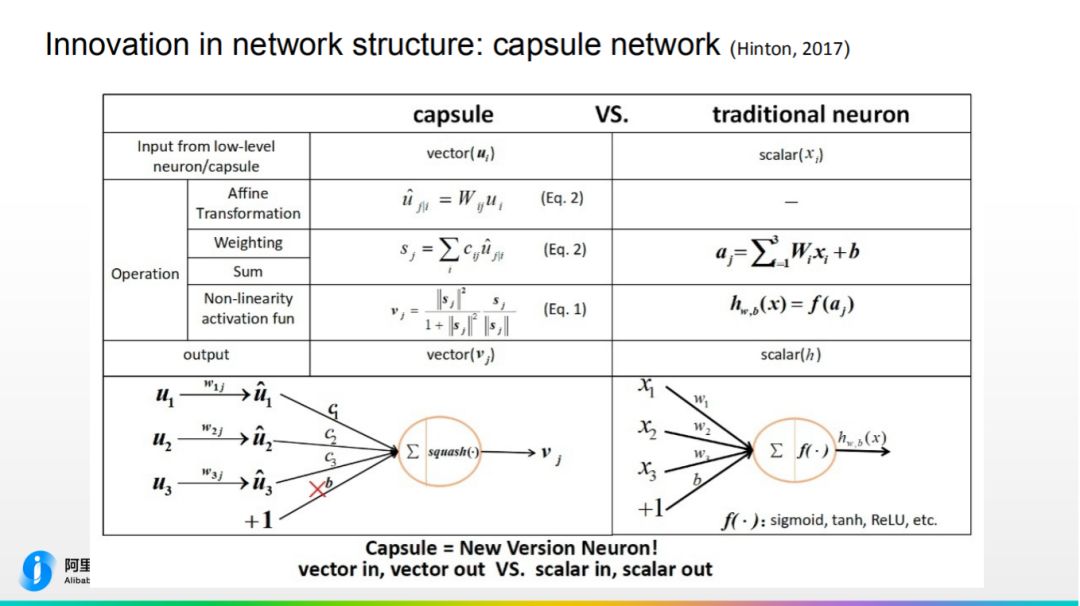 我们紧跟学术界步伐,想到了胶囊网络。相比于传统神经元只接受标量输入,胶囊网络接受向量输入,故其特征表示更丰富。它擅长将信息揉碎再整合,首先使用非线性操作 squash,再通过 dynamic routing 实现无监督特征整合。比较符合我们动机,把句子信息揉碎重新组合学到新的知识。
我们紧跟学术界步伐,想到了胶囊网络。相比于传统神经元只接受标量输入,胶囊网络接受向量输入,故其特征表示更丰富。它擅长将信息揉碎再整合,首先使用非线性操作 squash,再通过 dynamic routing 实现无监督特征整合。比较符合我们动机,把句子信息揉碎重新组合学到新的知识。
2. 方法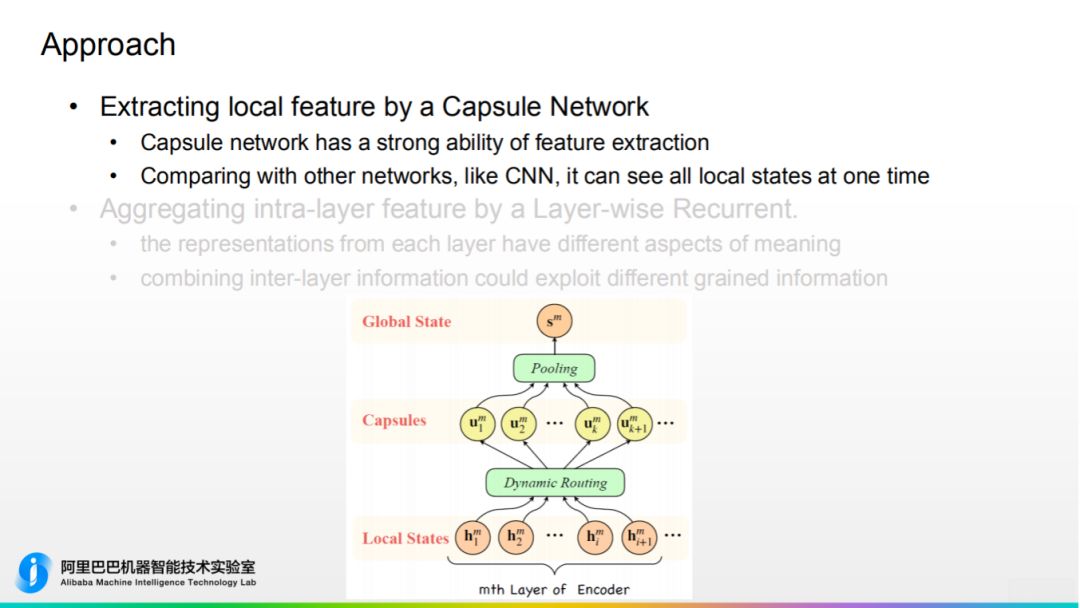 ① 首先用胶囊网络去提取局部特征并重新组合,如图所示。这里使用基于的 attention 的 pooling,而不是使用传统的直接把胶囊的信息 concat 到一起,主要是为了降低网络的维度,减少计算量。和传统 CNN 相比,它可以同一时刻看到所有信息。
① 首先用胶囊网络去提取局部特征并重新组合,如图所示。这里使用基于的 attention 的 pooling,而不是使用传统的直接把胶囊的信息 concat 到一起,主要是为了降低网络的维度,减少计算量。和传统 CNN 相比,它可以同一时刻看到所有信息。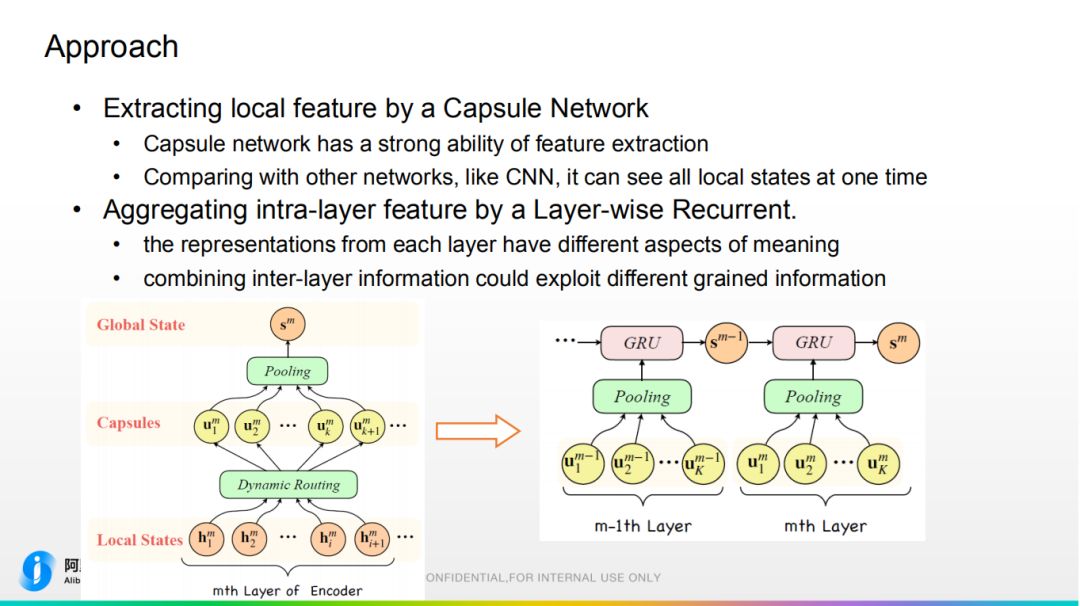 ② Transformer 网络是一个多层的结构,通常只会把 Encoder 最高层的信息输出的 Decoder,会丢失下层信息。故我们沿用上一工作 layer-wise 的想法,设计了层级别的循环的结构,使下层信息一步一步传给最上层,最终输出的 Decoder,这样实现了全局信息的捕捉。
② Transformer 网络是一个多层的结构,通常只会把 Encoder 最高层的信息输出的 Decoder,会丢失下层信息。故我们沿用上一工作 layer-wise 的想法,设计了层级别的循环的结构,使下层信息一步一步传给最上层,最终输出的 Decoder,这样实现了全局信息的捕捉。
3. 实验部分 在各大数据集上做。此方法理论上适用于任何文本生成任务。
在各大数据集上做。此方法理论上适用于任何文本生成任务。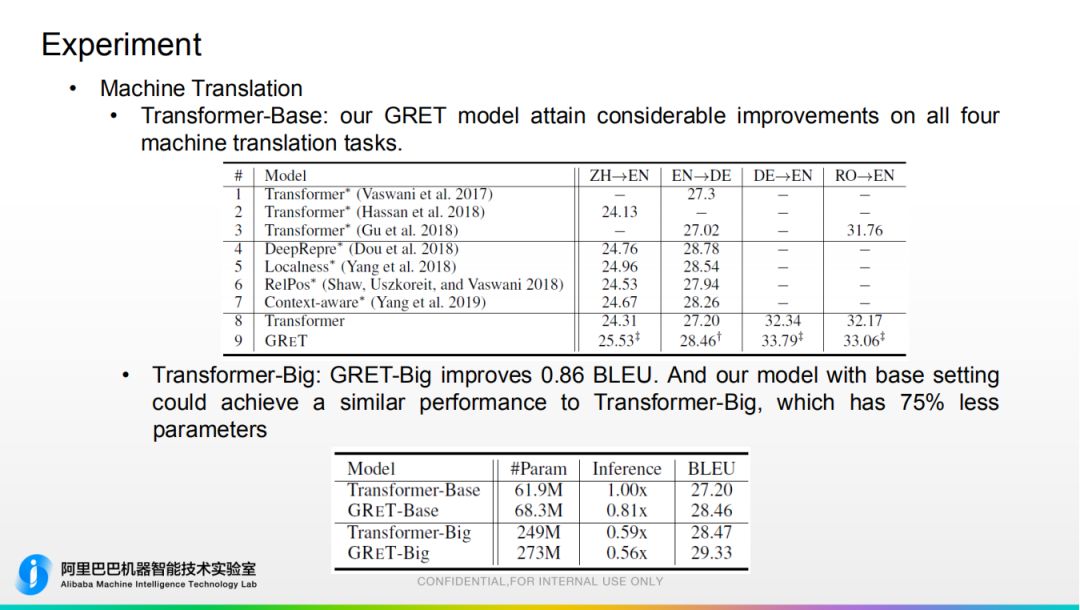 值得注意的是:和 Transformer-Big 进行对比,性能差不多的前提下,此模型参数量少75%。
值得注意的是:和 Transformer-Big 进行对比,性能差不多的前提下,此模型参数量少75%。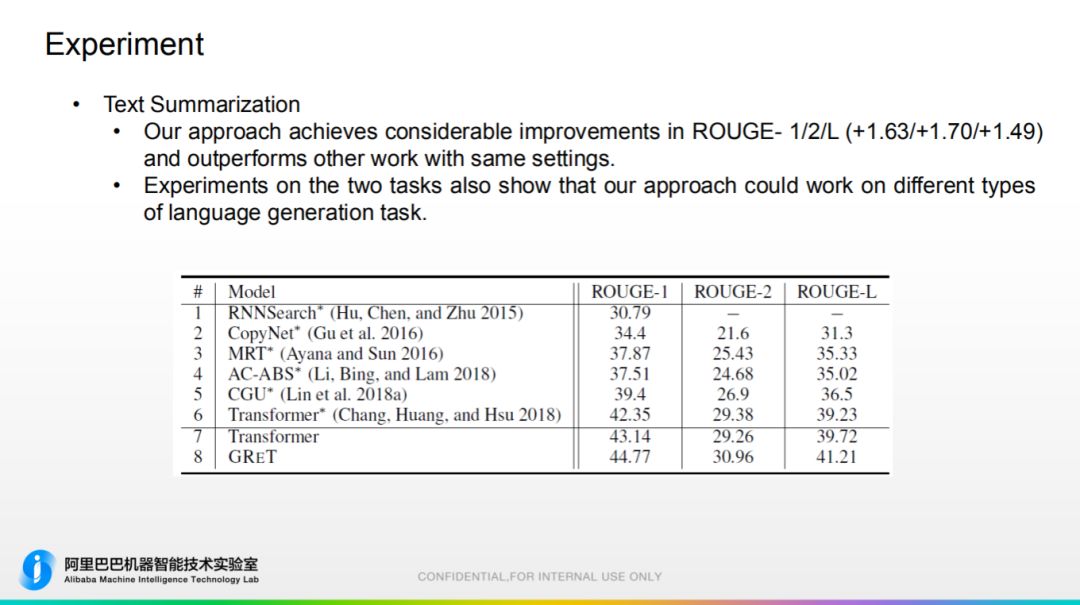 4. 结论
4. 结论 提出新型捕捉全局信息网络,能更好捕捉全局化的句子级别的信息,帮助 Transformer 提升性能。
提出新型捕捉全局信息网络,能更好捕捉全局化的句子级别的信息,帮助 Transformer 提升性能。
06
未来工作 未来的工作主要包括:
未来的工作主要包括:
- 多模态信息。
- pre-train 模型扩展到多语言 setting:提升稀缺语言质量,实现一种通用的 Encoder 去编码所有语言。
- 从具有更富信息的翻译场景做一些任务:文档翻译和多轮对话场景翻译。
07
参考资料

今天的分享就到这里,谢谢大家。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk NLP 交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:NLP,逃课儿会自动拉你进群。
 分享嘉宾▬
分享嘉宾▬
于恒 博士阿里达摩院 | 高级算法专家——END——
关于我们:
DataFunTalk专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号DataFunTalk累计生产原创文章400+,百万+阅读,5万+精准粉丝。
