本文记录一下对model pruning方法的学习,我只是挑了一些代表性的论文阅读一下,了解pruning的思路。
首先推荐一篇博客,闲话模型压缩之网络剪枝(Network Pruning)篇,其中的分类和思路讲得都非常清楚。本文中看的论文大多是该篇博客中讲的,本文相对于该博客,起一个细化和补充的作用,记录一下自己的理解。
先说一下Pruning的方法的分类,可以查阅其他博客,都将其分类成“结构化”和“非结构化”的两类。我认为“结构化”的意思就是不打破filter的表示,比如剪掉某一个channel,直观的来讲就是整个网络模型看起来就是超参数变化了。而“非结构化”则是打破了filter的表示,稀疏地不规则。
非结构化剪枝之后的结果打破了现有框架的表示,需要硬件的支持才能起到预期效果,所以当前研究大多是结构化的。
非结构化的
这里只介绍两篇非结构化的,属于比较早期的论文。
Learning both Weights and Connections for Efficient Neural Networks
代码:https://github.com/Guoning-Chen/SimplePruning-PyTorch
推荐结合代码和文章一起看,想法很容易理解。就是统计一下整个网络中权重的大小,然后把绝对值小权重的剪掉(具体就是置0,代码中用的是mask的方法)。
DEEP COMPRESSION: COMPRESSING DEEP NEURAL NETWORKS WITH PRUNING, TRAINED QUANTIZATION AND HUFFMAN CODING
是上一篇文章的改进,提出了剪枝+量化+哈夫曼编码的三步走策略。
先说剪枝,就是上文的剪枝方法,把绝对值小的去掉。既然要储存稀疏矩阵,那肯定要储存index。如果index数字很大的话,那储存一个index用的空间也不小。所以本文提出了储存relative index,如下图:
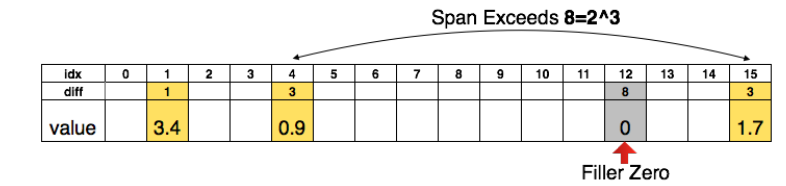
比如说储存原来的index,那么index最大是15,所以每个index需要4个bits,那么储存所有的index需要12bits。如果储存relative index,也就是上图的diff,限制diff最大为8,两个index之间超过8用0补充。那么储存每个index需要3bits,一共4个diff,所以也需要12个bits。那么如果最大index不是15,而是几万,这就凸显了用diff的好处。
再说量化,有了稀疏权重,那么权重是用32bits的浮点数表示,是不是也可以减少表示位数。如下图:
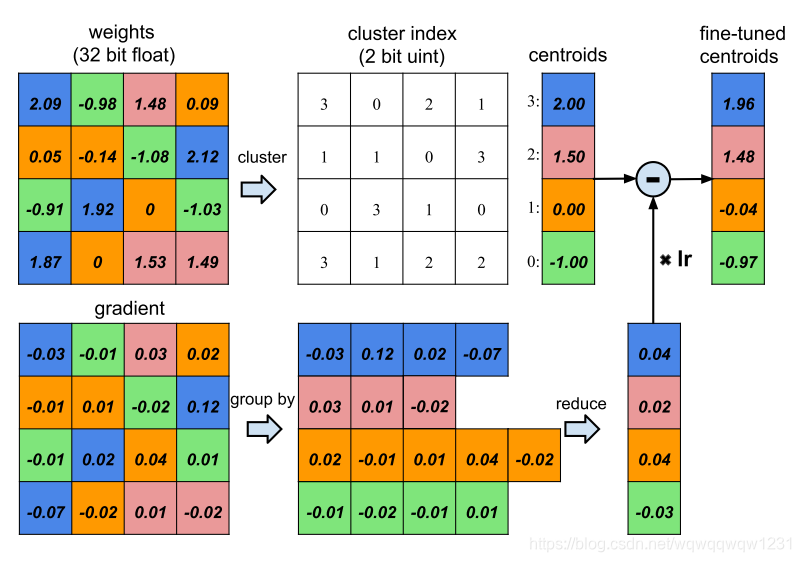
一共16个权重,原本占据16*32bits。现在用kmeans聚类,聚成4个类,表示类别的cluster index需要2bits,然后每个类用一个共享权重表示,所以占据空间是16*2+4*32bits。
最后再用Huffman编码进一步压缩权重。
结构化的
Learning Efficient Convolutional Networks through Network Slimming
对通道上做剪裁。本文一开始提出,在训练网络的同时,对每个feature map的channel加一个可训练的权重 γ \gamma γ,把权重乘到channel上面作为输出的feature map。在剪枝的时候,剪去 γ \gamma γ小的,也就是不重要的。
但这其实有个问题,对于没有BN的网络, γ \gamma γ变小和weight增大是相互抵消的,所以 γ \gamma γ小也不代表啥。而且大多网络都有BN,所以作者提出直接使用BN中的 γ \gamma γ。因为即便再多加一个 γ \gamma γ,也会和BN中的 γ \gamma γ相互抵消:

BN是先做归一化,然后再用 γ \gamma γ缩放,其实 γ \gamma γ缩放的是方差, γ \gamma γ越小,说明这个channel方差越小,也就是都差不多,信息量就是少,确实可以减掉。
Channel Pruning for Accelerating Very Deep Neural Networks
上述几篇文章的剪裁思路都是依赖一个先验假设:某种情况下的权重是不重要的。
本文则不依赖这种假设,而使用使得剪枝过后的特征图能够尽可能与剪枝前的一样这个想法。这种想法,就有点做PCA的感觉了。
给定输入特征图X: N × c × k w × k h N\times c \times k_w \times k_h N×c×kw×kh,N是batch数量
使用卷积核W: n × c × k w × k h n\times c \times k_w \times k_h n×c×kw×kh
可以得到输出特征图Y: N × n × k w × k h N\times n \times k_w \times k_h N×n×kw×kh。
那么,如果想要剪枝,就是把c变为c’,再加上之前的想法,就得到了优化目标:

L0的优化是一个NP-hard问题,转成L1的优化:

具体过程就是,固定W,逐渐调大 λ \lambda λ,使得 β \beta β满足约束,然后在优化W。
Data-Driven Sparse Structure Selection for Deep Neural Networks
区别于上文给出每一层要剪枝多少,本文提出了一种自动剪枝的方式。可以分别针对神经元,网络层,网络组,或者block。
核心思想就是在某种结构的输出乘以一个可训练的因子然后得到最后的输出。当该因子数值为0时,该网络结构就可以被去掉。如下图,因子分别被乘在各种结构后:
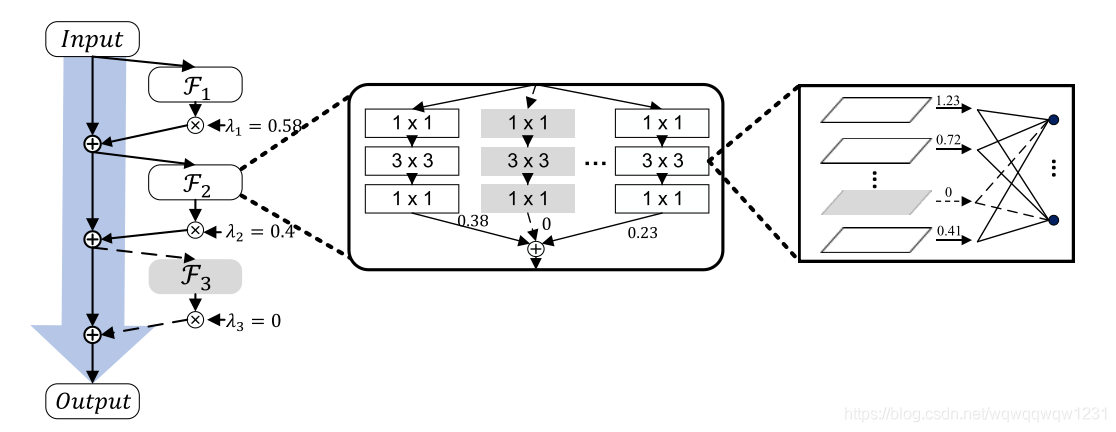
对于神经元的,就和《Learning Efficient Convolutional Networks through Network Slimming》这篇文章中的方法很像,只不过是不融合到BN中。
对于block的,比如ResNet,原本表示如下:

加上因子之后变为:

分组卷积也是类似:

反思
RETHINKING THE VALUE OF NETWORK PRUNING
这篇文章重新看待了Model Pruning这个问题。文章最主要的发现就是:从一个训练好的大模型中,经过剪枝和fine-tune之后的效果,还不如随机初始化这个剪枝后的模型,然后训练。
这个发现说明,剪枝之后保留原始的权重没有意义。说明剪枝更大的意义在于寻找一个高效的网络结构,而不是尽可能的保留大模型的表示能力。
而且文章中发现,对于VGG这种比较老的网络,其权重的稀疏分布是非常不均匀的,通过自动化的剪枝,可以找到比每层都剪去同样比例channel数的更高效的模型。那这其实就出现个想法,既然要先训练一个大模型进行自动化剪枝,那为什么不直接进行网络结构搜索。这样剪枝和NAS就其实就走到一块去了。