来源:https://livebook.manning.com/book/c-plus-plus-concurrency-in-action-second-edition/chapter-1/v-7/62
1 Hello, world of concurrency in C++!
1.1.1 Concurrency in computer systems
老式的计算机是单核的,会在不同任务间切换,让人感觉是同时进行的,这就叫做并发(Cocurrent),注意,这些Task的切换很快( task switches are so fast)
在进行SwitchTask时,OS需要存储CPU状态和当前运行任务的指令的指针,然后找到对应switch的任务,然后加载对应的CPU状态和任务。
因此,单核的计算机相较于多核的计算机运行时,内存消耗会多一些,如下图所示,灰色部分区间明显大于上面的黑色线区间:
In order to perform a context switch, the OS has to save the CPU state and instruction pointer for the currently running task, work out which task to switch to, and reload the CPU state for the task being switched to. The CPU will then potentially have to load the memory for the instructions and data for the new task into the cache, which can prevent the CPU from executing any instructions, causing further delay.

对于多核的处理器,并不是多核就没有并发了,一样会有的,因为执行的任务可以有很多个,如下图所示是双核的处理器,同样是做了ConCurrency,一样会有并发产生
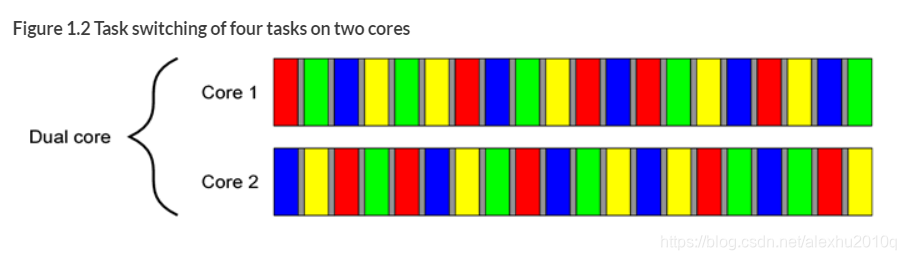
两种并发实现的模式
首先回顾一下进程与线程的区别:
线程相当于轻量级的进程,每一个线程都是独立的,而且可以运行一系列的指令,但与进程不同的是:线程之间享有同样的地址空间,而且在进程内会有一块global的区间可以供线程间共享。也就是说,同一进程内不同线程的数据传递相对容易,虽然进程间也可以共享数据,但是由于一些data在不同的进程内的地址不一样,所以进程间共享内存会比线程间共享内存复杂的多
有两种实现并发的模式:
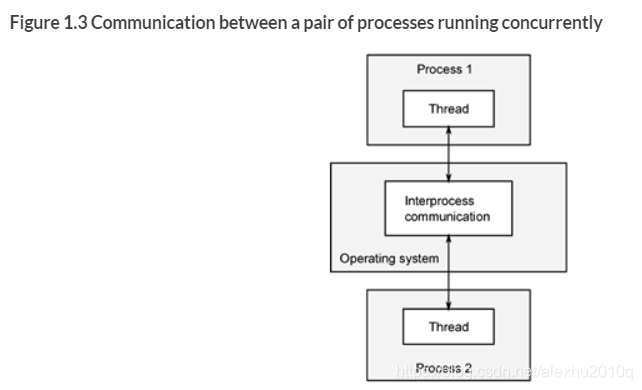
- 多个进程,每个进程是单线程的
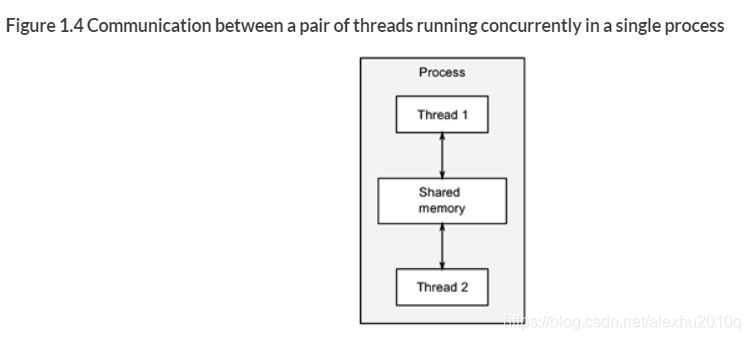
- 一个进程,这个进程是多线程的
对于第一种模式,其优缺点如下:
- 优点: 安全,更容易写出安全的并发的code,而且,可以通过网络,在不同的机器上运行不同的进程
- 缺点:进程间的通信比较慢,因为要通过OS来保证进程的data不会被其他进程更改,额外的还有OS启动和manage进程的消耗
模型如下图所示:
对于第二种模式,优缺点如下:
- 优点:没有了OS的处理,data在线程间的传递和处理很快
- 缺点:不安全,因为同一块区域能由多个线程同时访问
模型如下图所示:
总结
由于第二种并发模型的高效特性,电脑的并发一般都采用的第二种模型,注意,C++标准库没有提供任何关于进程间通讯的API,所以相关操作只能基于Platform-specific API,后面提到的实现的并发也都是指的第二种模型——单进程多线程模型。
1.1.3 Concurrency vs. Parallelism
在关于multithreaded code上,Concurrency和Parallelism有很多意思上的重叠区,在很多场合二者意思是一样的,都是为了同时进行多个任务,不过两个名词想表达的关键点不一样,当谈到并行的时候,人们往往着重的是使用available hardware,是硬件层面上的,使用硬件来提高效率,而谈到并发的时候,whereas people talk about concurrency when their primary concern is separation of concerns, or responsiveness
Concurrency and parallelism have largely overlapping meanings with respect to multithreaded code. Indeed, to many they mean the same thing. The difference is primarily a matter of nuance, focus, and intent. Both terms are about running multiple tasks simultaneously, using the available hardware, but parallelism is much more performance-oriented. People talk about parallelism when their primary concern is taking advantage of the available hardware to increase the performance of bulk data processing, whereas people talk about concurrency when their primary concern is separation of concerns, or responsiveness. This dichotomy is not cut and dried, and there is still considerable overlap in meaning, but it can help clarify discussions to know of this distinction. Throughout this book, there will be examples of both.
1.2 为什么使用Concurrency
主要有两个原因:
- separation of concerns:把代码的关注点分离,降低代码耦合度
- performance:提高运行效率
1.2.1 Using concurrency for separation of concerns
Separation of concerns翻译过来叫做关注点分离,也是一种设计软件的代码的理念:将组合相关联的代码,分离不想干的代码(grouping related bits of code together and keeping unrelated bits of code apart),可以方便代码维护、测试和阅读。
如果没有并发,那么所有同时发生的代码都会需要额外的代码或框架,去保证他们的运行是正确的,这样就会把不相关的代码联系起来:
without the explicit use of concurrency, you either have to write a task-switching framework or actively make calls to unrelated areas of code during an operation
举个例子,电脑上的视频播放器软件是一个processing-intensive application with a user interface,比如说迅雷影音,它会同时具备以下功能:
- 从磁盘读取data,解压出图像和声音,然后传递到显卡和声卡
- 接受用户的输入,可以进行暂停、快进等操作
如果没有Concurrency,用一个单线程,那么可能有一个bool值,然后隔一段时间就去check这个bool值,如果是true,就暂停,这样的话用户的Input界面就会和DVD的播放模块耦合起来,使用多线程就能降低耦合,一个线程负责Play,一个线程负责DVD的模块,基于这种分时的理念,不管一个电脑有几个CPU核心,都可以实现多线程的操作。
1.2.2 Using concurrency for performance: task parallelism and data parallelism
以前的多核一般都只用于超级电脑、服务器等,现在随着硬件便宜了,也开始利用多核开始进行编程了,具体做法有两种:
- task parallelism:把一个任务分为多个子任务,然后不同的处理器并行去跑,这样不同的处理器处理的是算法的不同的部分
- data parallelism:一份Data,处理器A处理一部分,处理器B处理另一部分,两个处理器是并行的,二者算法是一样的
**Embarrassingly parallel algorithms ** 翻译过来是容易并行的算法,我理解的也就是那些具有线程安全,很适合并行的算法
1.2.3 When not to use concurrency
核心原因是,当使用多线程的消耗不足以提高很多的性能的时候
多线程的缺点:
- 代码难写,bug比较多
- 创建线程需要消耗时间,操作系统还要为线程分配对应的栈
- 尽管是多核的,还是会去切换线程,切换需要额外的消耗,线程很多时,再加线程整体性能反而可能会下降
比如说对于4GB,32位的操作系统上,一个线程分配1MB的栈内存(很多系统上都是这样),那么最多分配4096个线程,内存就会被消耗殆尽,(虽然线程池可以缓解这个问题,但它也不是银弹,线程池可以用于那种服务器,服务器为每一个连接的客户端创建一个单独的线程)。
1.3 Concurrency and multithreading in C++
从C++11开始,提供了多线程的接口,从此就可以放心地写多线程,而不用去接触具体的平台的API了,为了理解C++标准库现在的做法,有必要了解一下历史由来:
1.3.1 History of multithreading in C++
C++98里完全没有线程的概念,内存模型也不是正规的( the memory model isn’t formally defined),要写多线程,只能在C++的特定拓展版本的编译器下执行,虽然C++不提供,但是可以通过编译器给语言添加extension,由于C语言对于多线程上的prevalence,C++的好多编译器开始支持不同语言的拓展的多线程功能,此时的C++Runtime Library只要能确保该其内部的C++代码不出错,其他的东西就不管了,所以引入了很多C语言的功能
Compiler vendors are free to add extensions to the language, and the prevalence of C APIs for multithreading—such as those in the POSIX C standard and the Microsoft Windows API—has led many C++ compiler vendors to support multithreading with various platform-specific extensions.
由于不满足C++用C对应的platform-specific API for multithreading
2. Managing Threads
2.1 Basic thread management
基本的线程创建就不说了,相关写法之前写过博客了,这里主要做补充
目前理解的是,创建线程的时候,必须给予一个Callable Object,Callable Object大概有以下六种:
- 函数指针
- lambda函数
- 仿函数
- 类的成员函数
- 类的静态函数
- std::bind的对象
使用仿函数传递参数时额外注意的点
对于仿函数,比如仿函数的定义如下:
class Functor{
public:
bool operator ()()const
{
return false;
}
};
那么接下来有一个需求,就是声明一个函数,这个函数叫做m_thread,接收参数为一个函数指针,指向的函数接受0个参数,返回一个functor对象,返回类型为一个线程,那么函数声明为:
std::thread m_Thread (Functor());// 注意,只有functor可以这么写,函数指针应该不可以这么写
// 比如C++的sort函数,就是传入的Functor作为比较函数
class cmp
{
public:
bool operator()(int a, int b) //从小到大
{
return a < b;
}
};
sort(a, a+n, cmp());// 这里传入了cmp对应的函数指针
然后,你又接了一个新的需求,这个需求需要你创建一个线程,这个线程传入的callable object是仿函数,那么线程的定义为:
std::thread m_Thread (Functor());
可以看到,上面的两个定义出来的对象是一样的,这是由于C++可恶的语法(“C++ most vexing parse”),为了加以区分,仿函数的线程传入方法有些特殊:
std::thread m_Thread (Functor()); // 声明函数
std::thread m_Thread ((Functor())); // 声明线程,传入仿函数
std::thread m_Thread {
Functor()}; // 声明线程,传入仿函数
多线程常见错误
一个线程拥有的引用或者指针,所指向的对象已经被(其他线程)销毁了,或者说已经走出了主线程,被销毁了
被Detached的线程
被Detached的线程,代表着这个线程与当前的主线程再无任何关系,Detached的线程无法再被其他线程引用,即使主线程运行完了,该线程也仍然会执行,所以,在Unix里,把它叫做Daemon Thread,翻译过来就是守护进程的线程,很多这种Detached Thread,其生命期都跟Application一样长,比如说文件监管系统、GC清理系统等(叫Daemon Thread感觉挺帅气的)
automatic variable
读书的时候有个概念不懂,什么叫automatic variable?
在C里面,对于一个变量,它不仅仅只有其Class的type数据,还有它的Storage Class数据,storage存储的东西主要有以下几点:
- 变量的存储位置
- 变量的生命期
- 变量的作用域
一共有以下几种Storage Class:
- Register Storage Class
- Static Storage Class
- External Storage Class
- Automatic Storage Class
对于一个变量,如果它被定义为Automatic Storage Class,那么它有如下特点:
- 该变量是存储在Memory里面
- 如果不给该变量赋初值,那么该变量 is an unpredictable value called ‘garbage value’
- 作用域:The scope of the variable is local to the block in which it is defined.
- 生命期:The variable is alive as long as the control remains in the block in which it is defined.
上面的内容看起来挺复杂的,其实主要是因为C++11对auto关键字的引入,在C语言里,auto是一个变量的specifier,说白了,auto变量就相当于局部变量,如下面的代码所示:
// C++11之前
auto int a,b;
int a,b;//这两句话是一个意思
2.2 Passing arguments to a thread function
创建线程时需要指定对应任务对应的函数,具体传参的方式也很简单,就是在thread的构造函数的参数里添加多的参数,注意,这里传递的参数,会首先Copy到新创建线程对应的自己的内存区域里,然后再把它当一个临时变量,作为右值传入到线程对应的函数中去,就算这个callable object对应的参数接受的参数为引用也会这样,下面看一个例子:
void f(int i, std::string const& s);
std::thread t(f, 1, "Hello World");
按照上面的逻辑分析一下,t会把1和"Hello World",拷贝到线程t自己的内存里,注意由于传入的"Hello World"是const char*类型,这里会先直接拷贝参数,然后在新线程t的context里,创建一个String的临时对象,作为右值传入f函数
多线程常见错误示例
再来看下面的例子,看看这个例子会出现什么问题:
void f(int i, std::string const& s);
// 这段代码有问题吗
void oops(int i)
{
char buffer[1024];
sprintf(buffer, "%i", i);
std::thread t(f, 3, buffer);
t.detach();
}
上面代码是有问题的,因为buffer在这里会出现向string的隐式转换,但oops会提前走完,所以buffer指向的区域被释放掉了,会造成undefined behaviour
正确的写法,是在创建线程t的时候,使用显示转换:
std::thread t(f, 3, string(buffer));// 正确
std::thread t(f, 3, buffer);// 错误
也就是说,隐式转换会慢于显示转换,这是因为,新线程只会单纯的复制参数,调用参数的conversion发生在执行线程期间,所以显示转换下,这里会先生成一个string,再传进去,然后oops执行完毕,而在隐式转换下,这里会先传入一个char* pointer,然后oops执行完毕,pointer变为dangled pointer
再来看下面一段代码:
class Data {
};
void f(int i, Data& s);
int main()
{
Data s;
std::thread t(f, 1, s);
}
请问这段代码会发生什么,为什么会这样?
答案:这段代码会编译报错,原理跟多线程的启动和参数调用的机制,也就是上面所说的内容有关
开启多线程时,会先直接复制参数,然后再在该线程里的contex里,去调用具体的函数,传入的参数都是作为右值传入的。
那么很显然,由于f函数只接受左值的Data,所以会报错,但如果这么写,那就可以编译了:
class Data {
};
void f(int i, const Data& s);//加了const,使得f函数既接受左值Data,也接受右值Data
但这里去改了f签名,实际上不是正确的方式,这里应该用std::ref,写法如下:
std::thread t(f, 1, std::ref(s));
当传入参数为uncopiable时
比如thread的函数参数要使用unique_ptr,那么该参数只可被move不可被copy,所以这个时候的写法就稍微特殊一些,代码如下:
void f(unique_ptr<Data>);
unique_ptr<Data>ptr;
std::thread t(f, 1, std::move(ptr));//ptr是创建的unique_ptr的实例
传入参数总结
- 若为值类型,则直接传值
- 若为引用类型,则改为
std::ref() - 若为不可以复制、只可被move的类型,则用
std::move()
2.3 Transfering Ownership of a thread
C++标准库里的ifstream、thread和unique_ptr都是可被Move不可被Copy的,判断下面代码有无问题:
void func1() {
}
void func2() {
}
int main()
{
std::thread t1(func1);
std::thread t2(std::move(t1));
t1 = std::thread(func2);
std::thread t3;
t3 = std::move(t1);
t1 = std::move(t3);
}
答案:只有最后一行会运行时报错,因为t1已经拥有了一个thread了,所以在对应被释放的thread的析构函数里,会调用std::terminate()终止程序,因为线程必须用thread.join()或者thread.detach()来结束
Returning std::thread from a function
由于std::thread是可以被move的,所以也可以用一个函数,返回std::thread,代码如下所示:
void f1();
std::thread function1()
{
return std::thread (f);
}
std::thread function2()
{
void f2(int);
return std::thread (f2, 32);
}
同样,std::thread既然可以作函数的返回值,那么它也可以作为函数的参数:
void f(std::thread);
void func();
int main()
{
std::thread t(func);
f(std::move(t));
}
scoped thread
跟其他类型,使用指针需要记得new和delete,所以有了RAII的智能指针,使用mutex需要记得lock和unlock,所以有了RAII的lock_guard,使用线程需要create和join或者detach,所以这里有了joining_thread(C++17提出),不过好像标准库并没有完全接受这个,C++20叫做std::jthread,自己写一个也很简单,就是在构造函数里,把thread用std::move移进来,再在析构函数里,如果是joinable,就去join
2.4 Choosing the number of threads at runtime
std::thread::hardware_concurrency()
This function returns an indication of the number of threads that can truly run concurrently for a given execution of a program.
On a multicore system it might be the number of CPU cores, for example. This is only a hint, and the function might return 0 if this information isn’t available, but it can be a useful guide for spliting a task among threads.
可以看出来,这个参数可以返回当前可以运行的最大线程数量作为一个参考值,不过它有可能返回失败,返回0的时候代表返回失败。关于具体的使用方法,可以举个例子,比如说我有100个.obj文件要去load,然后我有一个能容纳100个元素的vector,每个元素放置一个.obj的data,可以看出来,这些工作都是彼此不关联的,可以同时进行的,那么我可以根据当前的系统参数,设置出最大的线程数量,最多就开这么多个线程,同时去load数据
设定最大线程数量的写法如下:
// 一共100个文件,最多需要100个线程
unsigned int const max_threads = 100;
unsigned int const hardware_threads = std::thread::hardware_concurrency();
// 取系统提供的最大线程数和max_threads的最小值,如果返回的0,那么就设置2个线程
unsigned int const num_threads = std::min((hardware_threads ? hardware_threads : 2):, max_threads);
8核的计算机,最多只能创建8个线程吗
这个不知道,remain
2.5 Identifying threads
每一个thread都会有一个独特的id,其类型为std::thread::id,可以使用std::this_thread::get_id()获取对应thread的id,还可以打印出来看看:
std::cout << std::this_thread::get_id();
第二章内容总结
这一章主要涵盖了以下内容:
- 启动thread
- 等thread结束(join)
- 不等thread结束(detach)
- 启动thread时的函数传参
- thread的控制权转让
- 如何使用thread去divide work
- 使用id区分特定的thread