#非等比例风险的生存资料分析
###1 生成模拟数据###
library(flexsurv)
set.seed(123)
# 生成样本数量
n <- 100
# 生成时间数据
time <- sample(1:1000,n,replace=F) # 调整shape和scale参数以控制生存曲线形状
# 生成事件数据(假设按比例风险模型)
status <- rbinom(n, size = 1, prob = plogis(-0.5 + 0.01 * time))
# 生成一些协变量数据
covariate1 <- sample(c(0,1,100),n,replace=T)
covariate2 <- rbinom(n, size = 3, prob = 0.5)
group<-sample(c(0,1),n,replace=T)
# 创建生存数据框
survival_data <-data.frame(time,status,covariate1,covariate2,group)
###2 绘制KM曲线###
library(survminer)
library(survival)
library(ggplot2)
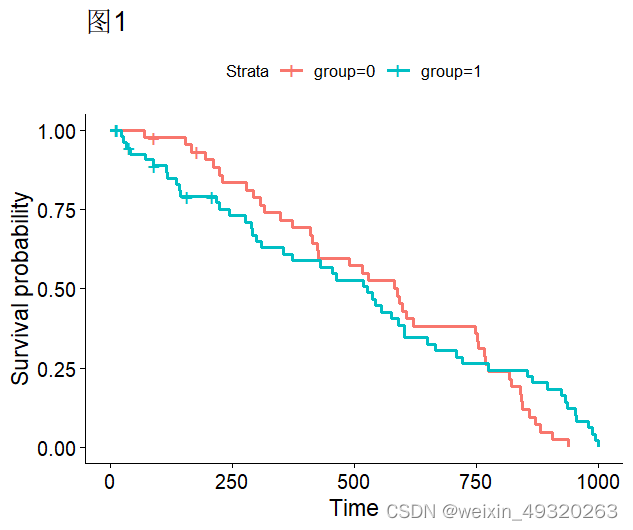
fit<-survfit(Surv(time,status) ~group,data=survival_data)
ggsurvplot(fit,title="图1")
###3 检验等比例风险###
#观察图片
plot(fit,fun='cloglog',col=c("red","green"),xlab="生存时间对数",ylab="二次对数生存率")
#残差法
coxfit<-coxph(Surv(time,status) ~group,data=survival_data)
zph<-cox.zph(coxfit,transform = "km")
ggcoxzph(zph,title="图2")#不满足等比例风险
cox.zph(coxfit,transform = "rank")
cox.zph(coxfit,transform = "identity")
###4 two-stage 组间差异比较###
library(TSHRC)
twostage(time,
status,group,
nboot=1000)#仅可以说明组间存在差异
#LRPV:log-rank检验;MTPV第二阶段检验;TSPV:两阶段检验结果
#install.packages("ComparisonSurv")
library(ComparisonSurv)
help(package="ComparisonSurv")
Overall.test(time,status,group)#包含two-stage在内的9种方法
###5 比较大小###
# 找出交叉点对应的时间
crosspoint(time,status,group)#768/774/775/999
#使用ComparisonSurv中的长期和短期比较
Long.test(time,status,group,t0=775)
Short.test(time,status,group,t0=775)
#RMST法:限制平均生存时间
#使用surv2sampleComp
library(surv2sampleComp)
help(package="surv2sampleComp")
sur1<-surv2sample(time,status,group,tau_start=0,tau=775,procedure="KM")
max(time);min(time)
sur2<-surv2sample(time,status,group,tau_start=775,tau=938,procedure="KM")#tau为两组中最长观测值的最小值
#使用survRM2
library(survRM2)
help(package="survRM2")
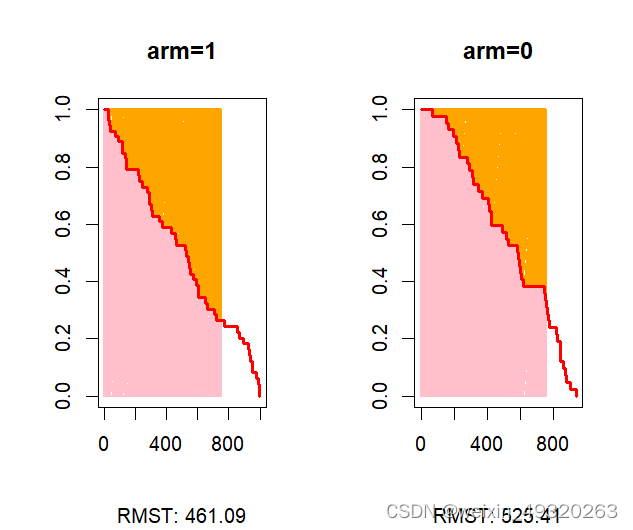
sur3<-rmst2(survival_data$time,
survival_data$status, arm=survival_data$group,
tau = 755, alpha = 0.05)
plot(sur3)
#landmark方法
dat1<-survival_data[survival_data$time<775,]
pzg<-coxph(Surv(time,status) ~group,data=dat1) %>% summary
pz<-pzg[["coefficients"]][1,5]
hr<-pzg[["coefficients"]][1,1]
dat2<-survival_data[survival_data$time>=775,]
pzg2<-coxph(Surv(time,status) ~group,data=dat2) %>% summary
pz2<-pzg2[["coefficients"]][1,5]
hr2<-pzg2[["coefficients"]][1,1]
duan_1<-survfit(Surv(time,status)~group,dat1)
duan_2<-survfit(Surv(time,status)~group,dat2)
#绘图
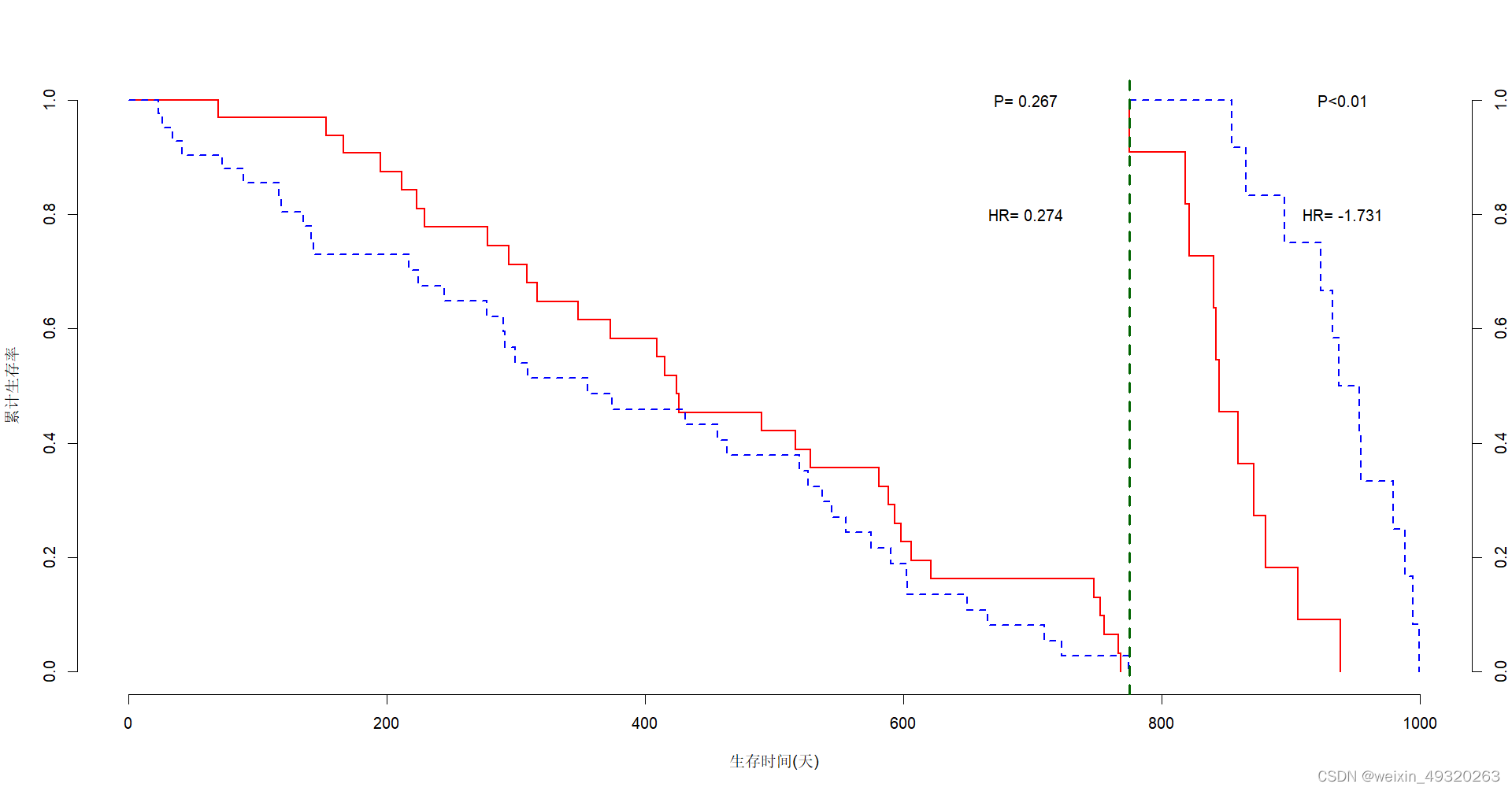
plot(duan_1, lty = c('solid', 'dashed'), col = c('red', 'blue'), xlim = c(0, 1000), xlab = "生存时间(天)", ylab = '累计生存率', axes = FALSE, lwd = 2)
text(695, 1.0, paste('P=',round(pz,3)))
text(695, 0.8, paste('HR=',round(hr,3)))
axis(1)
axis(2)
axis(4)
duan2a <- survfit(Surv(dat2$time, dat2$status == "1") ~ dat2$group, subset = (dat2$group == 1))
duan2b <- survfit(Surv(dat2$time, dat2$status == "1") ~ dat2$group, subset = (dat2$group == 0))
lines(c(775, duan2b$time), c(1, duan2b$surv), type = "s", lty = 'solid', lwd = 2, col = 'red')
lines(c(775, duan2a$time), c(1, duan2a$surv), type = "s", lty = 'dashed', lwd = 2, col = 'blue')
text(940, 1.0, paste('P<0.01'))
text(940, 0.8, paste('HR=',round(hr2,3)))
abline(v =775, lty = 2, col = "darkgreen", lwd = 3)