弹性网络(Elastic Net):是一种用于回归分析的统计方法,它是岭回归(Ridge Regression)和lasso回归(Lasso Regression)的结合,旨在克服它们各自的一些限制。弹性网络能够同时考虑L1正则化(lasso)和L2正则化(岭回归),从而在特定情况下对于高维数据集具有更好的性能。
#清空
rm(list=ls())
gc()
#导入包
library(glmnet)
help(package="glmnet")
library(survival)
library(caret)
library(tibble)
library(magrittr)
#原始数据处理
data(cancer)
data<-na.omit(lung) %>% data.frame
dim(lung)
#K折交叉验证
folds<-createMultiFolds(y=lung$status,
k=3,
time=1)
val<-list(train=data,
test1=data[folds$Fold1.Rep1,],
test2=data[folds$Fold2.Rep1,],
test3=data[folds$Fold3.Rep1,])
#构建模型
x1 <- as.matrix(data[,!(colnames(data) %in% c("time","status"))])
x2 <- as.matrix(Surv(data$time,data$status))
result <- data.frame()
#使用循环,使得alpha参数从0到1
for (alpha in seq(0,1,0.1)) {
set.seed(123)
fit = cv.glmnet(x1, x2,family = "cox",alpha=alpha,nfolds = 10)
rs <- lapply(val,function(x){cbind(x[,c("time","status")],RS=as.numeric(predict(fit,type='link',newx=as.matrix(x[,!(colnames(data) %in% c("time","status"))]),s=fit$lambda.min)))})
cc <- data.frame(Cindex=sapply(rs,function(x){as.numeric(summary(coxph(Surv(time,status)~RS,x))$concordance[1])}))%>%
rownames_to_column('ID')
cc$Model <- paste0('Enet','[α=',alpha,']')
result <- rbind(result,cc)
}
#得到每个alpha下C指数的平均值
library(dplyr)
mean_result<-result %>%
group_by(Model) %>%
summarise(Cindex=mean(Cindex))
#绘图
plot(fit)
mean_result %>%
ggplot(aes(Cindex,reorder(Model,Cindex)))+
geom_bar(width=0.7,stat = 'identity',fill='green')+
geom_text(aes(label = round(Cindex, 2)), hjust=1,vjust =0.5,color = 'black') + # 在条形柱顶端添加数值
theme_void()+
scale_x_break(c(0.05,0.53),scales = 20)
mean_result <- pivot_wider(result,names_from = 'ID',values_from = 'Cindex')%>%as.data.frame()
mean_result[,-1] <- apply(mean_result[,-1],2,as.numeric)
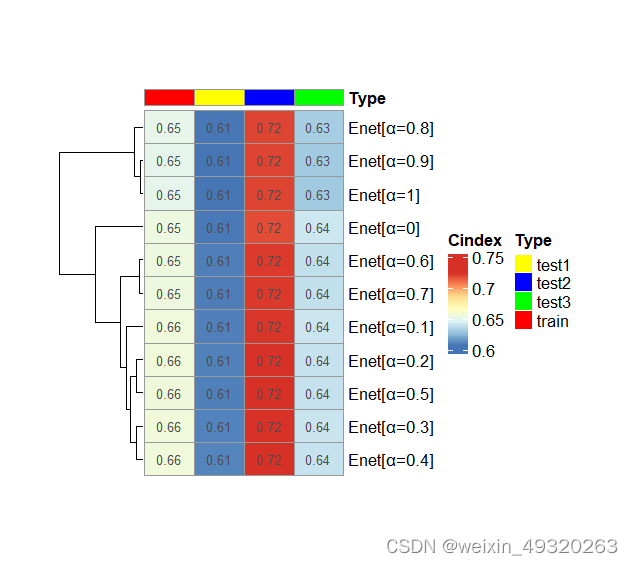
heatdata <- as.matrix(mean_result2[, 2:5])
rownames(heatdata) <- mean_result2$Model
args(pheatmap)
pheatmap(heatdata,name = "Cindex",
cluster_cols = FALSE,#不进行行聚类
cluster_rows = T, #进行行聚类
show_colnames = FALSE,
show_rownames = T, # 显示行名
display_numbers=T,
annotation_col=data.frame(Type=c("train","test1","test2","test3")),
annotation_colors = list(Type=c(train="red",test1="yellow",
test2="blue",test3="green")),
cellwidth = 30, # 调整小方块的宽度
cellheight = 20 # 调整小方块的高度
)