
凡是搞计量经济的,都关注这个号了
所有计量经济圈方法论丛的do文件, 微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
感谢@克努多 群友分享
问:我正在做线性回归,其中因变量是树种的地位指数(site index:是指在某一立地上特定基准年龄时优势木的平均高度值),解释变量是诸如海拔、坡度之类的地理因素。起初,这2个解释变量都不显著,但将树龄作为解释变量放到模型中后,海拔和坡度突然变得具有统计显著性。这是怎么回事呢?
A回答:
在流行病学中,我们称其为负混杂因素(negative confounder)。
若想研究维生素A补品摄入量与婴儿腹泻之间的关系。我们知道除了维生素A外,食用纤维是改善粪便稠度的重要原因。其关系可以概括为,增加维生素A可以减少腹泻,而缺乏纤维摄入会增加腹泻,因此,两者互相补充。此时,当我们观察两个亚人群(暴露于维生素A与未暴露于维生素A)时,就无法观察到维生素A摄入量与婴儿腹泻之间的任何关联。若我们“调整”纤维摄入量,维生素A的摄入量和婴儿腹泻之间的联系就会显现出来。
什么意思呢?就是若不控制纤维摄入量,那么在维生素A摄入量与婴儿腹泻之间的回归中,维生素A的系数就不显著;若控制了纤维摄入量,那么维生素A的系数就变得显著了。
一旦了解了负混杂因素的存在,在构建模型时就需要做两件事:
- 在概念上确定潜在的混杂因素->它们必须是a)能引起感兴趣的结果变量的已知因素(即,混杂因素会影响Y),b)与正在研究的感兴趣的因素相关(混杂因素与X相关),c)它们不能位于感兴趣的因素和结果变量之间的因果路径上,即不位于中间路径上。
- 检验潜在的混杂因素与感兴趣的结果变量的相关性,并基于你定义一个混杂因素的显著性水平来决定是否将它们放在模型中(即两者显著性水平高就考虑将其放到回归模型)。对于单变量分析,我通常将其设置为p<0.2,然后将其设置为p<0.05,以便在我的最终模型中保留一个混杂因素。
B回答:
我想在A的出色回答中增加一些实用建议。当我去做多元回归时,不会对协变量的怪异行为感到吃惊。为什么?这是因为我已经制作了一堆单变量和双变量的表和图,可以看到彼此相关的每个候选协变量。
当我研究美国陆军受伤情况时,首先会看看,是在年轻组还是老年组,是在单身组还是已婚组以及是在文化程度较低还是文化程度较高的组别中,受伤发生率比较高。因此,当将所有变量都放在同一个模型中时,他们都竞争着去解释结果变量——受伤率。不过,可以想一想,年轻群体中也有人受教育程度低,以及还没有结过婚。因此,正如A所说,在使用多元回归之前,我已经通过单变量和双变量描述性统计的表格和图表,很好地了解了混杂因素如何在摆弄我的结果变量。
因此,当我遇到这样的难题时,通常会制作解释变量与结果变量所有组合的表和图,以及每个自变量与其他自变量组合的表和图。通过一种使它们可视化的实用方法(散点图,将连续变量分类等等),诊断出为什么仅向模型中添加一个变量就可能“搞砸”模型的原因。
C回答:
为了解释这种情况,研究变量的相关性是必要的。
但是,如果变量不相关,也会发生这种现象:可能的解释之一是年龄有很强的影响力,所以如果不调整年龄,则无法解释较大的变异性,并且看不到微弱的影响,而调整年龄后,与无法解释的变异性相比,此前微弱的影响就不再小了。
D回答:
因为这可能是抑制效应(suppression effect)的情况。在这种情况下,结果变量是年龄的函数,而年龄又是其他变量的函数。
E回答:
查找辛普森悖论:https://en.wikipedia.org/wiki/Simpson%27s_paradox(加入其他控制变量后, 估计系数的符号相反了?)
F回答:
关注统计显著性(例如P值<0.05)是错误的。没有告诉我们将年龄添加到模型后回归系数发生了多少变化。他们也有颠倒了的迹象吗?当把年龄放在模型中时,系数的解释意义是什么?如果对年龄进行调整更有意义,那么就不用担心没有年龄的模型。考虑这些问题比痴迷于P值的大小更为重要。
G回答:
使用逐步回归选项(即正向或反向回归)可能会改善关于负混杂因素的结果,并给出最能表达模型的变量的输出结果。
调整后的R方值和beta系数的置信区间也可以使你了解变量的表现和重要性。
H回答:
不管这个问题的根源如何,在这种情况下,在给定新加入变量的情况下,结果变量y和旧变量X之间的偏相关系数将是显著的。然而,结果变量与旧变量X简单的相关系数并不显著。
对于这类问题的根源,一个常见的原因是y中存在非常小和非常大的异常值,与y对应的旧自变量值x在y的异常值处几乎相同,但新加入的自变量值在y的异常值处却截然不同。
下面给一个简单的示例,其中包含一个结果变量(y)和两个自变量(x1,x2)。
第5行和第6行的y值为100和-100。但是,x1的值是7和6(非常接近的值)。如果不考虑这两个个体(即不考虑第5和第6行),似乎y和x1之间存在正相关关系。但若同时考虑到这两条线会导致y和x1之间的关系不显著。
现在,由于x2在y = 100时为20,在y = -100时为-20;在模型中添加x2可以消除这些异常值对y和x1之间关系的影响。
附带的是简单相关系数的输出,给定x2时y和x1之间的部分相关系数,模型中只有x1时的回归系数表以及模型中同时包括x1和x2时的回归系数表。
r y x1 x2
1 10.00 1.00 6.00
2 12.00 3.00 5.00
3 13.00 5.00 8.00
4 15.00 4.00 9.00
5 100.00 7.00 20.00
6 -100.00 6.00 -20.00
7 17.00 8.00 11.00
8 16.00 9.00 13.00
9 18.00 9.00 15.00
10 19.00 12.00 15.00
11 22.00 12.00 17.00
12 11.00 3.00 5.00
13 13.00 4.00 8.00
14 12.00 4.00 7.00
15 14.00 5.00 8.00
16 15.00 7.00 9.00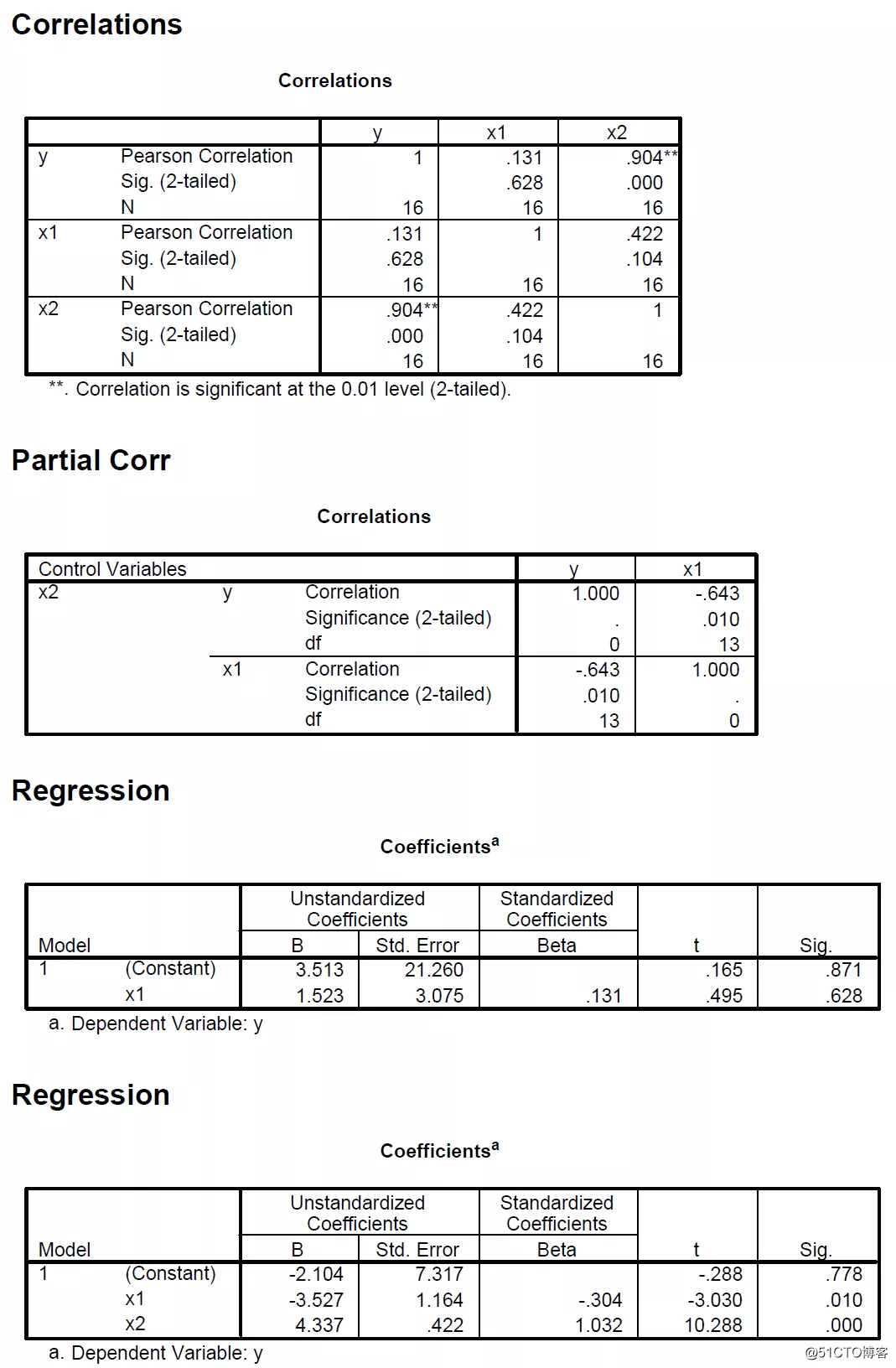
各位学人,也可以在文后进行留言讨论,从而达成学术共识。
Source: https://www.researchgate.net/post/Why_in_regression_analysis_the_inclusion_of_a_new_variable_makes_other_variables_that_previously_were_not_statistically_significant2
关于回归中变量的问题
1.什么时候应该使用回归分析?控制变量意味着什么?2.如何选择正确的因变量(控制变量),让你的计量模型不再肮脏,3.调节变量, 中介变量和控制变量啥区别与联系? 4.控制、调节和中介变量,系说,5.核心解释变量A不显著, 但加入变量B后, 为什么A和B都显著了?6.被解释变量比解释变量的层级更高的模型设定合理么?7.审稿: 协变量何时重要? 哪个重要, 有多重要?8.三张图秒懂, 混淆, 中介, 调节, 对撞, 暴露, 结果和协变量的复杂关系,9.因果推断专题:6.再谈混淆变量,10.什么时候需要标准化回归模型中的变量?11.因果推断专题:1.混淆变量,12.虚拟变量回归模型是什么? 政策评估的前件,13.11种与机器学习相关的多元变量分析方法汇总,14.回归中各变量的数值相差过大有事, 又有什么问题?15.哦, 不, 回归符号反了, 我们该怎么办?16.回归系数与预期相反时, 我们能够采取的方法和思路有哪些?17.显著不显著的后背是什么, 非(半)参估计里解决内生性,18.在什么情况下多增加一个自变量后, 回归的R方会变小呢?19.控制变量选择问题: 如何鉴别好或不好的控制变量?附上14篇相关文章!20.如何测度不可观测变量遗漏的严重程度, 建议各位学者看过来!21.如何选择合适的工具变量, 基于既有文献的总结和解释!22.如何选择合适的工具变量, 基于既有文献的总结和解释!23.如何测度不可观测变量遗漏的严重程度, 建议各位学者看过来!24.社会网络计量经济学是什么?测度社会关系网中的同伴效应!25.社会网络分析最新文献和软件学习手册,26.加入其他控制变量后, 估计系数的符号相反了?
下面这些短链接文章属于合集,可以收藏起来阅读,不然以后都找不到了。