
凡是搞计量经济的,都关注这个号了
所有计量经济圈方法论丛的code程序, 宏微观数据库和各种软件都放在社群里.欢迎到计量经济圈社群交流访问.
感谢@小苏 @伤心的奶牛 @Beet @Pengbin @Bee @Rimbaud @Pheastra.H等群友探讨. 可以到计量社群交流计量发展的最前沿。

1.“回归系数不显著”相关问题在计量经济圈社群探讨的延申:
首先要理解显著不显著背后的含义是啥。我们常见的总体数据特征是期望和方差,但由于现实中不易得到总体数据,而更多的时候得到的是总体的一个样本,用样本特征去推断总体特征,这里常见得样本特征即样本均值和样本方差,那么为啥可以用一个样本特征去推断总体特征呢?
这里就要扯到抽样分布了,以样本均值为例,抽样分布讲的是,假设我们可以重复抽样每一次抽样都有一个不大一样的样本均值,这样样本均值就构成了一个分布,再对这个样本均值分布求期望,在理论上就是总体均值了,但现实中我们不可能去重复抽样,抽样分布只是理论上得推导,所以这时候就用到了假设检验。
由于样本是从总体中来的,理论上我们一次抽到的样本均值不应离总体期望太远,我们假设一个总体期望,当样本均值与总体期望相近的时候t值就很小,p值就很大,即当前样本没有证据拒绝假设的总体期望,而当样本均值与假设的总体期望离的很远时t值就很大p就很小,这时统计学家就说在我们提出的这个假设下,我们一次抽样就发生了小概率事件这一般来说是不可信的,在当前样本下没有证据接受原假设,但这样就可能会犯两类错误......(另外还要考虑标准误之类的,p值不显著可以试试样本量大一些,让标准误小点。)
同样道理我们估计的贝塔系数也是基于样本估计出来的,实证的工作就是用它来估计总体系数,那么为啥用一个样本就可以估计总体,还是抽样分布,假设可以重复抽样,每次抽样都有一个贝塔,再对该贝塔系数分布求期望理论上就是总体系数,(就是常说的无偏性,这也是最小二乘的性质)。
但我们不会去重复抽样,所以假设一个总体系数,一般设为0,由于样本从总体中来,所以理论上如果我们的假设是正确的,则样本估计的贝塔不应离0很远,这时t很小p很大,但如果t很大p很小则说明我们估计的系数离0很远,当前样本没有证据接受原假设,或说一次抽样发生了小概率事件这是不大可能的,所以我们拒绝原假设,然而同样可能会犯两类错误。然而在总体数据可得的情况下统计推断就不再适用了,这时因果推断就开始登场了……

2.关于这篇文章在计量经济圈社群延申的探讨:内生变量的交互项如何寻工具变量, 交互项共线咋办


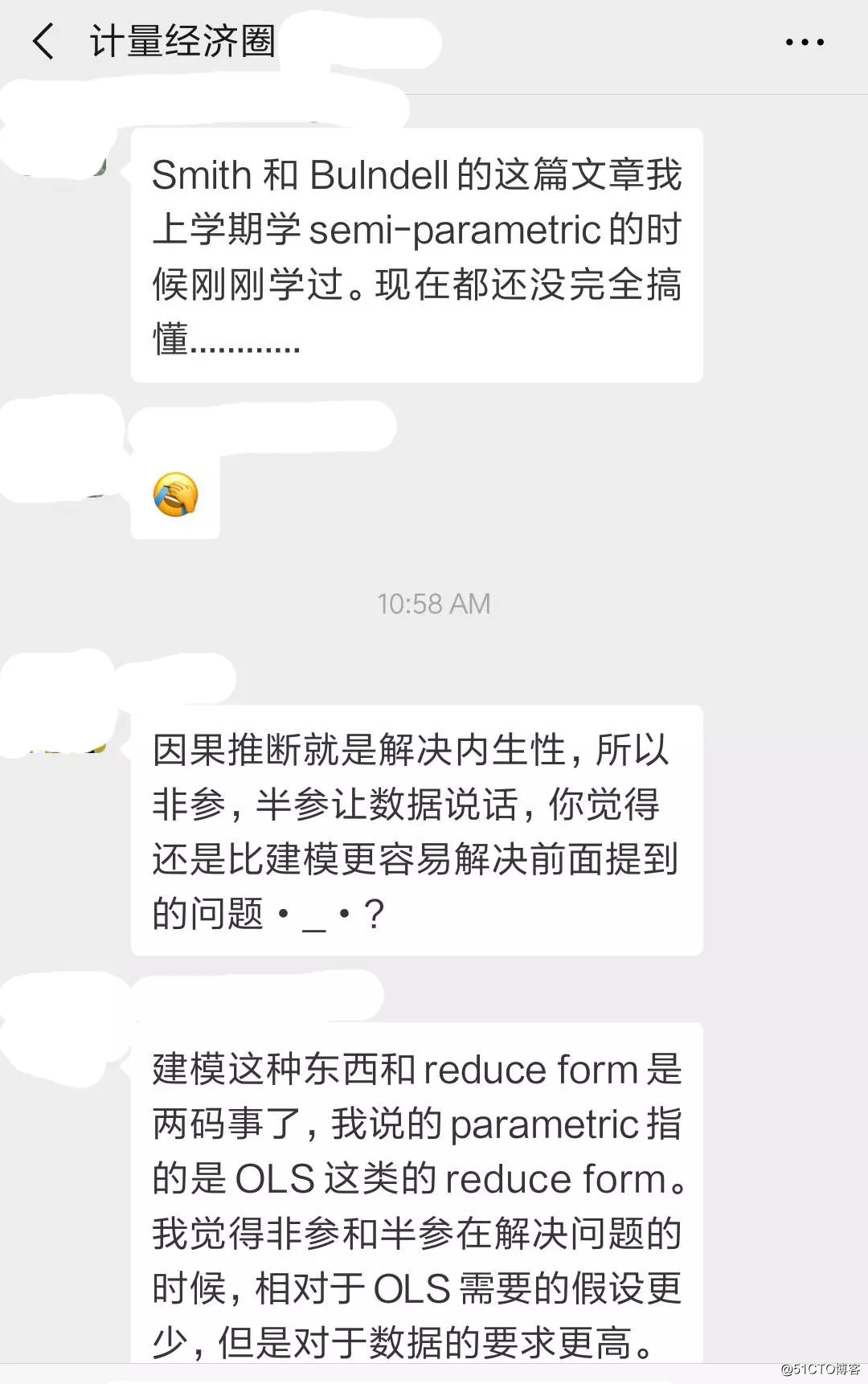
structural form和reduce form整个的研究逻辑都不太一样了,微观的structural 就没那么强调IV这类causal inference的,structural的人很多都默认自己的模型就是不存在endogeneity的,他们研究的卖点也主要是在于模型,而不是causality的严谨性判断。这种特点在搞empirical IO的那帮人身上比较显著。而咱们搞OLS的,卖点往往是causal inference。
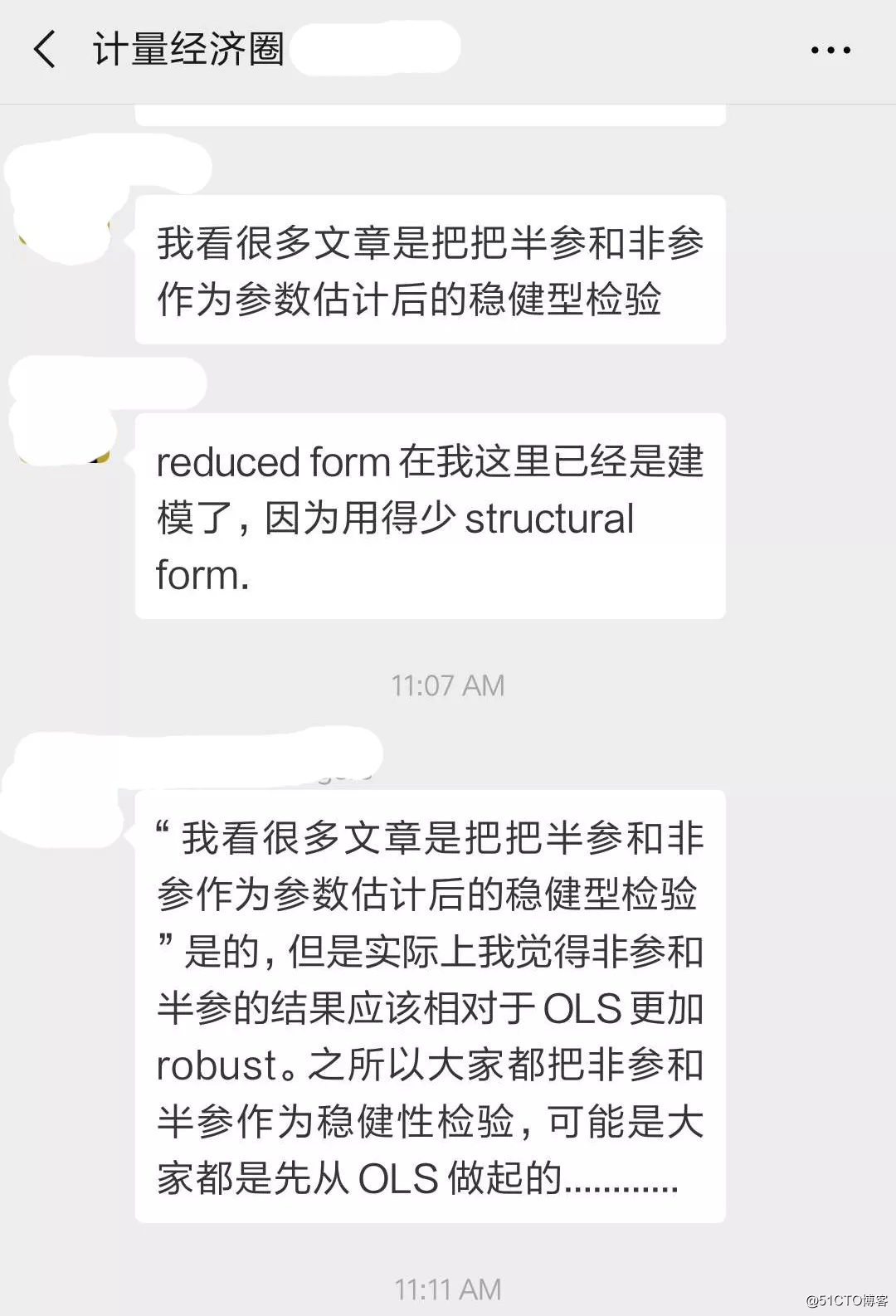
另外,“我看很多文章是把把半参和非参作为参数估计后的稳健型检验” 可能还有另外一个原因。现在由于知识更加专业化,能够同时精通计量和其他领域的学者也越来越少了。例如搞labor的,可能一辈子专注于找IV,DID这些,实际上对于semi-parametric的了解并不多,所以当他们作为你的审稿人的时候,他们基本只会关注你的OLS部分,你搞Labor实证研究要过他们的审,用OLS就够了。另一部分审稿人,他们可能对于IV不精通,但是专注于搞计量,对于计量模型的各种假设、设定非常清楚也非常较真儿,你如果遇到他们审稿,却只用OLS,和可能被他们插得很惨。所以就会出现你说的这种现象,投labor杂志,审稿人大概率是专注搞labor的,但是保不准来一个搞计量的,所以就是OLS为主,semi-parametric作为robustness check。
Pengbin: 参数和半参数主要是解决模型函数形式误设的问题 但是也不是解决内生性。
对,我指的是非参和半参加上IV这类~
是的,根据审稿人来做出的应变,也是一种学习路径。内生性是个无底洞,现在趋势是外生冲击去解决或者实验控制,已经看到越来越大比例top文章是这个。

3.关于RDD的falsification test在计量经济圈社群探讨的延申:

他这个跟DID是一样的类似的,就是非受到政策(干预)影响的那些组别的效应是不显著的。
比如本来政策发生时间是2008年,然后你把时间放在2007年进行原来的回归,当然需要是不显著的,这就是falsification test。
又比如政策是发生在某些行业的公司,那你用其他那些未收到影响的行业的公司去做回归就不能显著,这也是falsification test。
RDD这里是是一种running variable,要么时间,要么距离,反正两个组别就是在某个方面分开成了两段,但是这两段在很多方面都是极其相似的,因此做了一个local averagel treatment effect那种局部因果推断。
RDD断点回归, 实证完整程序百科全书
断点回归设计RDD分类与操作案例
PSM, RDD, Heckman, Panel模型的操作
可以到计量社群交流计量发展的最前沿。