一 概述
- k8s是什么
k8s是谷歌公司基于内部容器管理系统borg开源出的一个容器集群管理工具,它是用go语言开发,提供了容器的应用部署,规划,更新,维护等功能。
相信你读这篇文章之前,你已经有了docker基础。并且对k8s已经有个大概的理解,所以关于k8s的背景知识不做过多赘婿,下面我们直接上干货
二 系统架构
- k8s系统架构
学习新知识之前,一定要先对知识的整体框架有个大概的了解,为了更加生动形象的理解k8s框架,我在网上找了一张图(图片出处见水印),我们日后的
学习也会按照架构图上的知识点一点一点的铺散开来
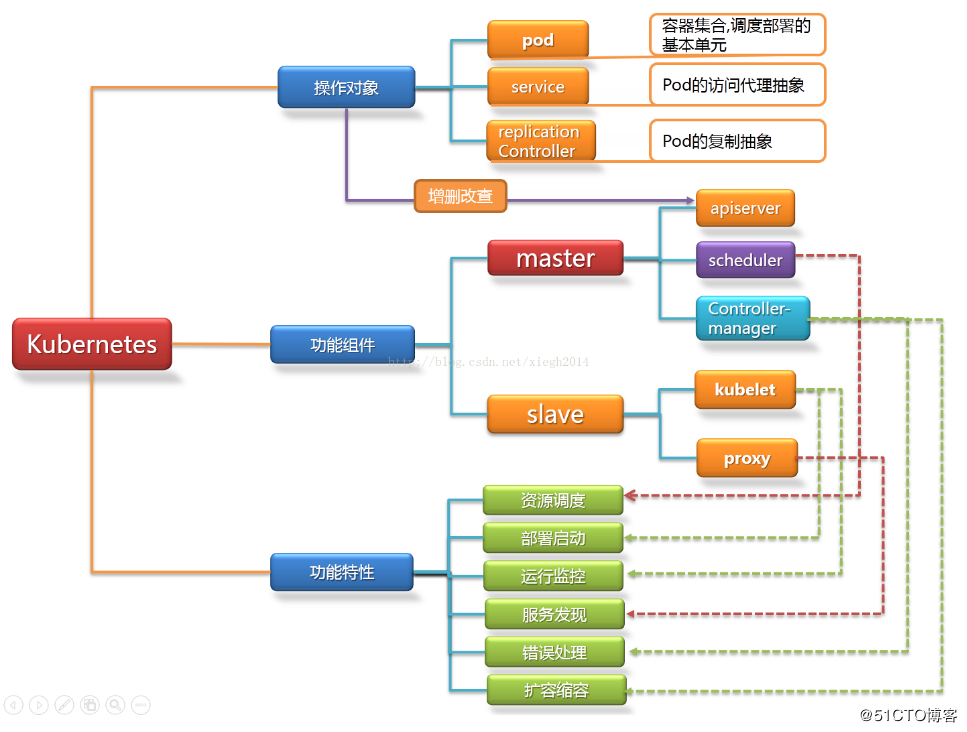
下面我们将架构图逐一拆解
- k8s操作对象
pod,service,replication controller三种就是我们日常经常操作的三类对象,当然,在k8s中,不仅仅只有这几种类型的资源,还有namespace,secret,node,
ingress,configmap等等
下面我们简单的对这三种资源做下介绍
- pod
pod在英文中的意思是豆荚,我们可以把容器想象成一个个的豆子,pod就是包裹住这些豆子的豆荚

Pod是K8s集群中所有业务类型的基础,可以看作运行在K8s集群中的小机器人,不同类型的业务就需要不同类型的小机器人去执行。目前K8s中的业务主要可以分为长期伺服型(long-running)
、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用 型(stateful application);分别对应的小机器人控制器为Deployment、Job、DaemonSet和PetSet,本文后面会一一介绍。
- replication controller
RC是K8s集群中最早的保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动运行新的Pod副本;
多于指定数目,RC就会杀死多余的Pod副本。即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有1个Pod在运行。RC是K8s较
早期的技术概念,只适用于长期伺服型的业务类型,比如控制小机器人提供高可用的Web服务。
- service
service一种抽象的服务,RC、RS和Deployment只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。一个Pod只是一个运行服务的实例,随时可能在一个节点上停止,
在另一个节点以一个新的IP启动一个新的Pod,因此不能以确定的IP和端口号提供服务。要稳定地提供服务需要服务发现和负载均衡能力。服务发现完成的工作,是针对客户端访问的服务,找到对
应的的后端服务实例。在K8s集群中,客户端需要访问的服务就是Service对象。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。在K8s集群中微服务的负载均衡
是由Kube-proxy实现的。Kube-proxy是K8s集群内部的负载均衡器。它是一个分布式代理服务器,在K8s的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供
负载均衡能力的Kube-proxy就越多,高可用节点也随之增多。与之相比,我们平时在服务器端做个反向代理做负载均衡,还要进一步解决反向代理的负载均衡和高可用问题。
2. 功能组件
在k8s集群中,共有俩部分,分为master节点与node节点,master节点还有node节点都对应一台实体服务器或者虚拟机
上面的功能组建遗漏了俩个最重要的部分,所以我们给他补上
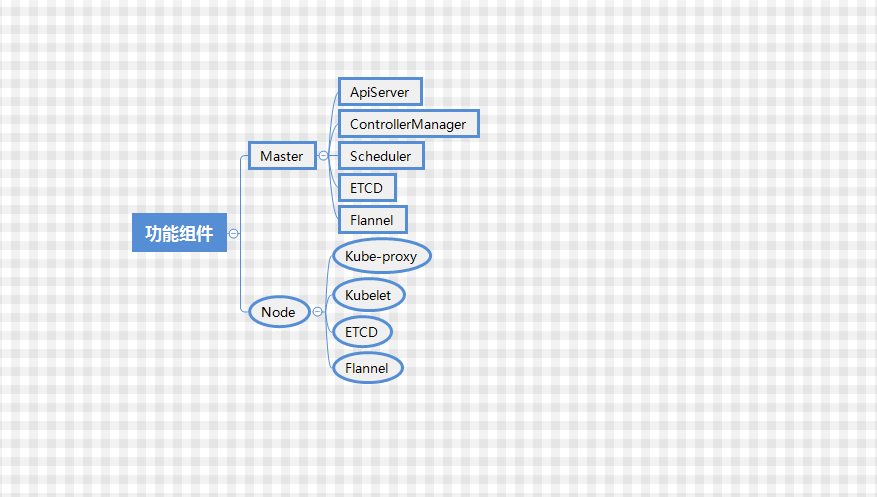
针对以上组件,我们做一下简要说明
apiserve:提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager:维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler:负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
flannel: 负责让不同机器上面pod跨节点进行网络通信
etcd: 提供强一致型的数据库与服务发现,在k8s集群中,网络配置还有资源对象的信息都存储在ETCD中
三 工作流程
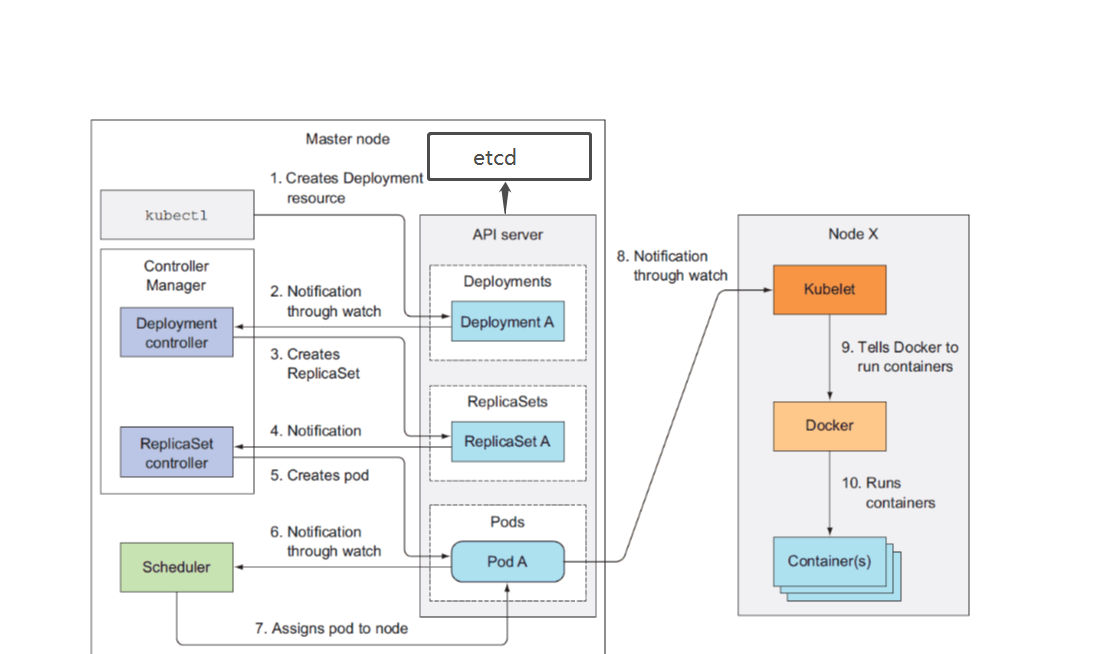
上面的流程图意在通过yaml文件创建一个deployment资源,先画个图说一下pod,replicaset,deployment三者关系,不然下面的流程解释初学者看不懂

因为deployment包含replicaset包含pod,所以创建deployment的时候会连续创建三种资源
1、准备好一个包含应用程序的Deployment的yml文件,然后通过kubectl客户端工具发送给ApiServer,ApiServer接收到客户端的请求并将资源内容存储到数据库(etcd)中。
2、deloyment Controlle监控apiserver状态发生了改变,知道了apiserver需要创建一个deployment资源
3、deployment controller 根据apiserver的状态信息,想要去创建一个ReplicaSet,此时apiserver检测到了deployment controller的期望状态的变化,再次记录到数据库etcd中
4、replicaset 监控到了apiserver状态发生了改变,知道了apiserver需要创建一个replicaset
5、replicaset controller根据apiserver的状态信息,想要去创建一个pod,此时apiserver检测到了replicaset controller的期望状态的变化,再次记录到数据库etcd中,此时
最低级别的pod的创建准备工作也完成,此时实际上pod,replicaset,deployment三种资源都没有实际被创建,刚才所说的创建类似于一种演习
6、Scheduler再次检查数据库变化,发现尚未被分配到具体执行节点(node)的Pod
7、根据一组相关规则将pod分配到可以运行它们的节点上,并更新数据库,记录pod分配情况。
8、Kubelete监控数据库变化,此时kubelet知道自己该创建pod了,但是它本身并没有创建容器的功能,所以它通知了有创建容器功能的docker引擎,并把创建的约束信息
(如镜像名称,镜像源等)传递给docker引擎
9、docker引擎根据收到的信息开始拉取镜像,创建容器,此时,deployment才算真正创建成功
四 小结
以上就是k8s的简单介绍,后续我们将更深入的讲解每一个组件与功能
文中如有错误之处,请大家向我及时指出,谢谢