2021-02-23 22:49:59
2020年11月20日,由中国科学技术协会主办,中国国际科技交流中心、中国人工智能学会、新加坡通商中国承办的“中新数字经济与人工智能高峰论坛”云端召开。主题报告环节,清华大学智能技术与系统国家重点实验室主任朱小燕教授为我们带来了《对话系统现状与展望》的精彩演讲。
朱小燕 清华大学智能技术与系统国家重点实验室主任、教授
以下是朱小燕教授的演讲实录:
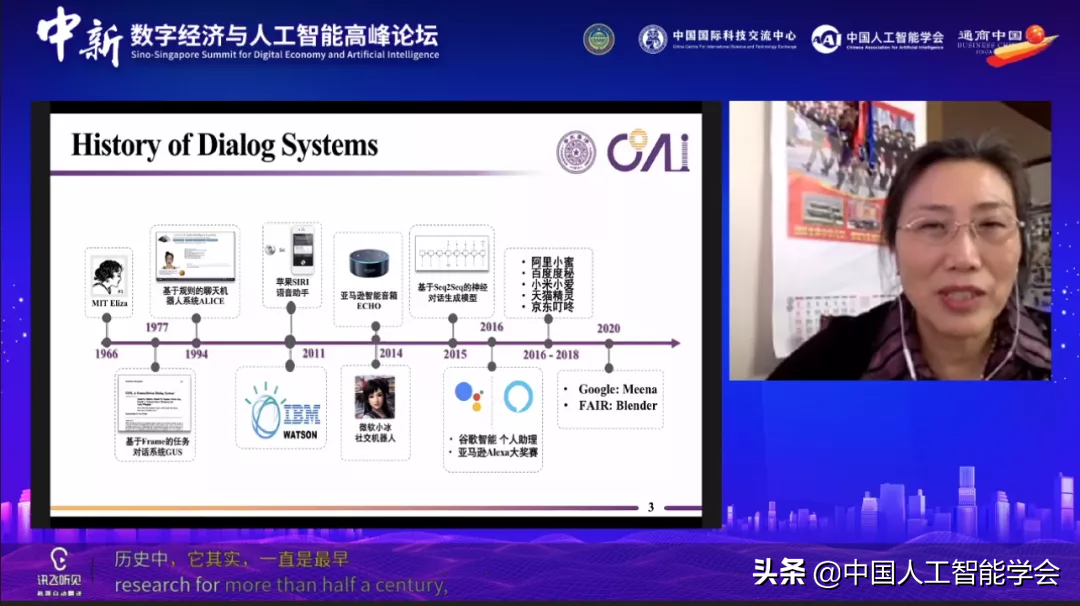
关于对话系统,大家也比较熟悉。图灵测试我们都知道,就是用机器和人对话的方式,给出一个判别机器智能的试金石。因此对话系统的研究在工智能研究历史中,一直是重要的研究分支。这张图显示了研究发展时间线,有几个结点大家可以关注一下,2011年IBM 的WOTSON出世和苹果手机SIRI发布;2014年亚马逊的ECHO发布,微软的社交机器人小冰步入人们视线。近年不停地有新的事物诞生,具体的,IBM WOTSON在美国电视知识抢答节目上的表现优秀,远远打败了人,再次把人们的注意力呼唤到人机对话,机器人智能的方向上来;还有亚马逊推出智能音箱Echo之后,持续在该方面大量投入,2017年开始至今,每年举行一个Alexa Priza Challenges国际竞赛,奖金高达50万美金。这个竞赛火爆也说明了该研究在国际上被关注程度。
对话系统大致可分陪伴闲聊和任务导向两大类。陪伴闲聊型方面做得最好。例如,谷歌2020年的系统(参数量为2.6B),看看他们系统在也人聊什么?机器居然让牛上大学去,去哈佛,学习牛科学。它可以引导人类进入它的节奏。另一个是Facebook最新的2020年系统,人问机器人想去和谁吃饭,不论死的还是活的,机器人居然选择了Steve Jobs;还解释,为什么和他吃饭,对他什么地方印象最深等。整个对话过程中展现了人的个性、知识、情感共情、赋予同情等。他们最好的系统,这两个例子显示了系统能力,并没有真正使用,没有太多使用的场合。在我们实际的生活中有哪些实际应用?首先是Robotics这种小机器人大家可能见过很多,银行、宾馆、餐厅,各种公共场合都会有小机器人走来走去,或者站着不动。另外是客服类,现在非常多,我们大家有意识、无意识应该会经常碰到。有一次我买了一个电气产品,突然接到了一个电话,说你是不是买了一个什么?28号下午去给你安装可以吗?紧接着说一句,“你就回答行还是不行。”我一愣,随口问道:“28号星期几?”它就给我来了一句,“谢谢您的配合。”我才反应过来,原来是个机器人。这样的情况非常多,在微信很多群里其实经常是机器人跟你讲话。还有非任务型的,小冰这种聊天型的机器人,年轻人很感兴趣。还有一个大家可能没太注意,有人用这种方式进行诈骗,希望大家永远不要遇到。
尽管以上示例说明了研究与应用推广都有了很大的进步,但还有很多不足的地方。接下来的工作有这样一些挑战。从研究角度来讲,现在这些工作都很少能融于知识,这里“知识”是广义的,不仅是常识知识、领域知识,还包括上下文知识、环境知识等,而且语义分析也是比较弱的,它没有真正的理解;另外,它在情感、情绪、共情等方面,离我们想象中的拟人机器人还是差的很远。另一方面从应用角度,现在的系统无法可靠、负责任地完成与人的交互,甚至出现引起伦理方面质疑的现象。因此需要有一个比较公平、公正、完整的评价体系,不仅可以指导研究发展的方向,也可以约束市场规范。除此之外,当前的研究成果在规模扩展、应用推广等方面代价很大的,严重影响理论算法的可迁移性和产品开发推广。因此,需要强有力的支撑平台,才能使看起来非常好的研究报告快捷落地,产生社会影响和经济效益。
针对这些挑战,有以下几方面的工作。
第一,算法研究方面。现在大家都非常努力的想要把知识和情感等融入到对话系统中,不管是以pipeline,还是用端到端的系统构建方式,尽量让这个系统用户体验更好一些,用户能更多地参与进来。陪伴系统也希望除了聊天之外,还能够有一些共情服务,比如对人的安抚、对人情绪的调整。在这方面有很多人做了大量工作,一个方向是把知识图谱一起参加训练、参加推理。我们这个方面有一篇论文获得了IJCAI-ECAI 2018的杰出论文,也说明了这个研究方向得到领域关注和认可;另一个方向是对话中加入情感,喜怒哀乐,我们率先开始这方面的研究,2018年发表论文,引起了学术界的广泛关注,得到包括MIT Technology Review在内的多家报道。
第二,系统评价和规范,我们一篇关于系统评估的论文,在今年SIGDIAL2020获得了最佳论文,这也说明了评估工作在这样学术会议上得到很大的重视和支持。为了做好评估工作,我们做了大量的数据集构建工作。同样,这个工作在NLPCC2020上得到了best studet paper,说明业界对数据建设的重视程度。
第三,大规模预训练平台。通用预训练模型大家都知道,最新最强大的代表为GPT3,为什么要针对(任务型)对话任务专门去做?主要原因是因为对话系统太特殊了,其与领域知识,以及具体任务实施场景的相关性远远大于其他NLP任务,同时对话数据库通常又是非常少的。所以通用模型有很多不方便的地方。大家可能听说了,前两天刚刚发布了一个中文的预训练模型CPM(中文GPT模型),我们也有幸参与了研发工作,构建了大规模数据库。我们现在正在上面开发一个中文的对话预训练模型。
以上就是今后的研究方向展望。最后是我对人工智能的梦想。希望它延长我们身躯,增强我们力量,给我们带来新的收获。
(本报告根据速记整理)