准备工作
先在Redis官网下载最新的稳定版本6.2。按照官网给出的安装指南到Linux服务器上安装。
zadd调用过程
redis/src/server.c 文件中定义了所有命令运行要调用的方法。zadd命令运行会调用t_zset.c文件的zaddCommand方法。
struct redisCommand redisCommandTable[] = {
{
"zadd",zaddCommand,-4,
"write use-memory fast @sortedset",
0,NULL,1,1,1,0,0,0},
}
redis/src/t_zset.c 的zaddGenericCommand方法会调用一个关键的方法,就是zsetAdd,这个方法会判断元素存储数据结构是ziplist还是skiplist。如果zset集合的元素个数大于redis.config文件设置的zset_max_ziplist_entries大小或者zset集合元素的member的长度大于redis.config设置的zset_max_ziplist_value大小,就会使用skiplist数据结构存储。
void zaddCommand(client *c) {
zaddGenericCommand(c,ZADD_NONE);
}
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
//......省略
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//......省略
} else if (!xx) {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries ||
sdslen(ele) > server.zset_max_ziplist_value)
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
//......省略
} else {
//......省略
}
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//......省略
} else {
//......省略
}
//......省略
}
redis/conf文件可以设置这两个参数的大小。
为了节省空间,当zset集合的元素个数少于128个并且zadd的member的长度小于64字节,使用ziplist数据结构存储元素,否则使用skiplist数据结构存储元素
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
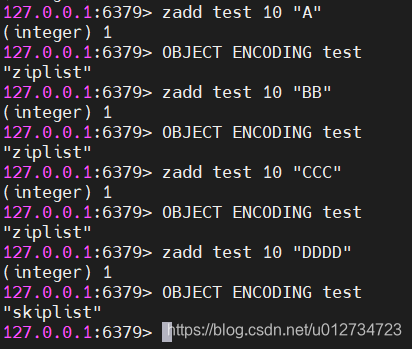
尝试修改zset-max-ziplist-value的值为3,修改完后重启redis-server。向命名为test的zset集合中依次添加元素A、BB、CCC、DDDD,使用OBJECT ENCODING test(集合名称)查看当前使用的数据结构,数据结构在插入第四个节点后修改为skiplist,因为字符串DDDD的长度大于3。
zskiplist
redis/src/server.c 文件中定义了zskiplistNode和zskiplist的结构。
(1)zskiplistNode包括字符串ele、浮点类型的分值score、后退指针backward和层级数组lelel。每一个层级包括前进指针和跨度。在查找某个节点的过程中, 将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。
(2)zskiplist包括头结点、尾结点、包含结点个数和结点(非头结点)最大层级数。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
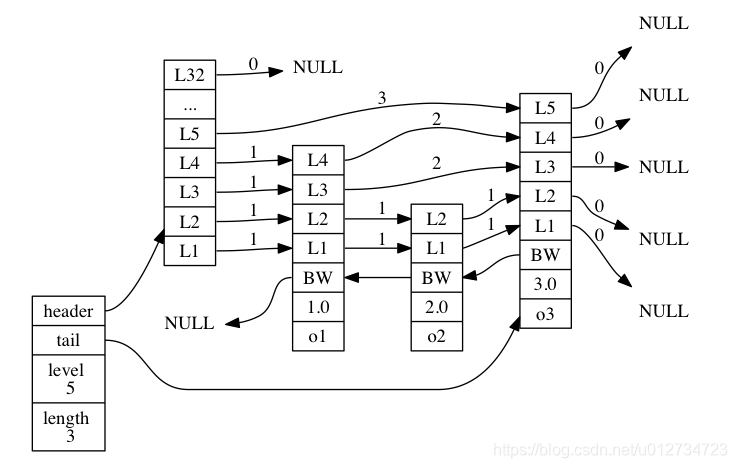
借用《Redis设计与实现》描述跳跃表的一张图。
(1)头结点包含32个层级,但不存储实际元素。
(2)包含o1、o2、o3三个元素。
(3)查找o3可以直接通过第5级索引查找。
用Java实现跳跃表
自己尝试去实现了一个跳跃表,只实现了一个插入和查找的方法,没有考虑重复元素的情况。
import lombok.Builder;
import lombok.Data;
import java.util.Map;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
@Data
@Builder
class SkipListNode {
private String ele;
private double score;
private SkipListNode backward;
private SkipListLevel level[];
}
@Data
@Builder
class SkipList {
private SkipListNode header;
private SkipListNode tail;
private long length;
private int level;
}
@Data
@Builder
class SkipListLevel {
private SkipListNode forward;
private long span;
}
@Data
@Builder
class ZSet {
private Map<String, SkipList> data;
//跳跃表头结点的最大层级是32.
public static final int SIZE = 3;
//添加元素,先判断name这个集合是否存在,如果不存在就初始化
public SkipListNode add(String name, String ele, double score) {
SkipList skipList = data.get(name);
if(null == skipList) {
//初始化
skipList = initSkipList();
data.put(name, skipList);
}
//随机生成一个层级
Random random = new Random();
int level = random.nextInt(SIZE);
//从头结点的层级开始遍历
SkipListNode skipListNode = SkipListNode.builder().ele(ele).score(score).level(initSkipListLevel(level + 1)).build();
for (int i = level; i >= 0; i--) {
//计算排位
double rank = 0;
SkipListLevel prevLevel = skipList.getHeader().getLevel()[i];
if(null == prevLevel.getForward()) {
prevLevel.setForward(skipListNode);
prevLevel.setSpan((long) score);
continue;
}
SkipListNode prevNode = prevLevel.getForward();
while(null != prevLevel.getForward() && score >= (rank + prevLevel.getSpan())) {
rank += prevLevel.getSpan();
prevNode = prevLevel.getForward();
prevLevel = prevLevel.getForward().getLevel()[i];
}
//插入结点
if(null != prevLevel.getForward()) {
skipListNode.getLevel()[i].setForward(prevLevel.getForward());
skipListNode.getLevel()[i].setSpan((long) (prevLevel.getForward().getScore() - skipListNode.getScore()));
}
prevNode.getLevel()[i].setForward(skipListNode);
prevNode.getLevel()[i].setSpan((long) (skipListNode.getScore() - prevNode.getScore()));
}
return skipListNode;
}
public SkipListNode find(String name, double score) {
SkipList skipList = data.get(name);
if(null == skipList) {
return null;
}
int fromIndex = SIZE - 1;
SkipListNode prevNode = skipList.getHeader();
while(null != prevNode) {
SkipListLevel skipListLevel = prevNode.getLevel()[fromIndex];
SkipListNode forwardNode = skipListLevel.getForward();
if(null == forwardNode || forwardNode.getScore() > score) {
fromIndex--;
} else if(forwardNode.getScore() == score) {
System.out.println("在第" + (fromIndex + 1) + "级索引找到:(" + forwardNode.getEle() + "," + forwardNode.getScore() + ")==>");
return forwardNode;
} else {
System.out.println("在第" + (fromIndex + 1) + "级索引找到:(" + forwardNode.getEle() + "," + forwardNode.getScore() + ")==>");
prevNode = forwardNode;
}
}
return null;
}
private SkipList initSkipList() {
//设置头结点
SkipListNode header = SkipListNode.builder().level(initSkipListLevel(SIZE)).build();
SkipList skipList = SkipList.builder().header(header).build();
return skipList;
}
private SkipListLevel[] initSkipListLevel(int level) {
SkipListLevel levels[] = new SkipListLevel[level];
for (int i = 0; i < level; i++) {
levels[i] = SkipListLevel.builder().build();
}
return levels;
}
}
public class SkipListTest {
public static void main(String[] args) {
ZSet zSet = ZSet.builder().data(new ConcurrentHashMap<>()).build();
zSet.add("test", "A", 10);
zSet.add("test", "B", 20);
zSet.add("test", "C", 30);
zSet.add("test", "D", 40);
zSet.add("test", "E", 50);
SkipList skipList = zSet.getData().get("test");
SkipListNode header = skipList.getHeader();
SkipListLevel[] levels = header.getLevel();
for (int i = levels.length - 1; i >= 0 ; i--) {
SkipListLevel level = levels[i];
SkipListNode node = level.getForward();
while(null != node) {
System.out.print("(" + node.getEle() + "," + node.getScore() + ") ");
node = node.getLevel()[i].getForward();
}
System.out.println();
}
zSet.find("test", 50);
}
}
运行结果:

为了避免生成太多层级索引,我将生成的最大层级限制改为了3。运行一次,用随机数生成结点的最大层级索引。这里结点A有三个层级,结点B有3级索引,结点C有1级索引,结点D有1级索引,结点E有2级索引。查找结点E,会经过3级索引(A,10)、(B,20)、2级索引(E,50)。比只有1级索引需要经过(A,10)、(B,20)、(C,30)、(D,40)、(E,50)快。
参考
Redis 跳跃表的实现
后台开发第七十八讲|redis,有序集合(orderedset),跳表,面试,源码学习一节课搞定1. 跳表的演变 2. 跳表的实现 3. redis中zset实现