目录
一、对比MapReduce与Spark的主要区别
- 易用性:Spark编程简洁方便
- 效率:Map中间结果写入磁盘,效率低下,不适合迭代运算。Spark Job中间输出结果可以保存在内存,不再需要读写HDFS
- 任务启动开销:MapReduce采用的是多进程模型,Spark采用了多线程模型
二、Spark技术栈
- Spark Core:核心组件,分布式计算引擎
- Spark SQL:高性能的基于Hadoop的SQL解决方案
- Spark Streaming:可以实现高吞吐量、具备容错机制的准实时流处理系统
- Spark GraphX:分布式图处理框架 Spark
- MLlib:构建在Spark上的分布式机器学习库
三、架构设计
1、运行架构
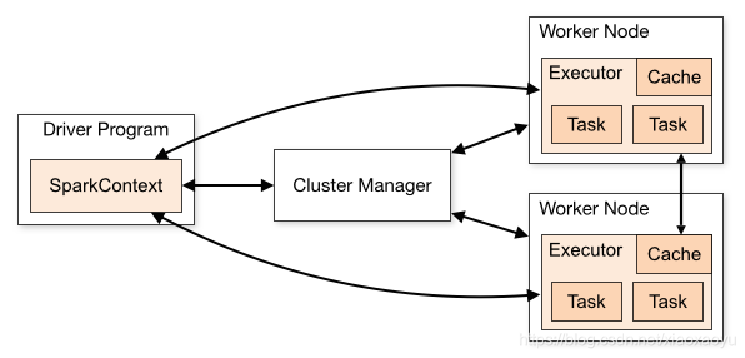
1、在驱动程序中,通过SparkContext主导应用的执行
2、SparkContext可以连接不同类型的Cluster Manager(Standalone、YARN、Mesos),
连接后,获得集群节点上的Executor
3、一个Worker节点默认一个Executor,可通过SPARK_WORKER_INSTANCES调整
4、每个应用获取自己的Executor
5、每个Task处理一个RDD分区
2、Spark架构核心组件及其作用
- Application:建立在Spark上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码。
- Driver program:驱动程序。Application中的main函数并创建SparkContext。
➢ 将用户程序转化为作业(job)
➢ 在 Executor 之间调度任务(task)- 任务调度分为两个模块:DAGScheduler(建立DAG图,划分Stage)和TaskScheduler(通过ClusterManager启动节点上的Executor)
- SchedulerBackend:每个 TaskScheduler 对应一个 SchedulerBackend,作用是分配当前可用的资源,具体就是向当前等待分配计算资源的 Task 分配计算资源(Executor),并在分配的 Executor 上启动 Task,完成计算的调度过程
➢ 跟踪 Executor 的执行情况
➢ 通过 UI 展示查询运行情况
- Cluster Manager :
➢ 在集群(Standalone、Mesos、YARN)上获取资源的外部服务。 - Executor:集群中工作节点worker中的一个JVM进程,运行具体任务,专门用于计算。
➢ 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
➢ 它们通过自身的块管理器(Block Manager)为用户程序中要求缓存的 RDD 提供内存式存储。RDD 是直接缓存在 Executor 进程内的,因此任务可以在运行时充分利用缓存数据加速运算。 - Master:
➢ Master 是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责,类似于 Yarn 环境中的 RM - Worker Node:集群中任何可以运行Application代码的节点。
➢ 由 Master 分配资源对数据进行并行的处理和计算,类似于 Yarn 环境中 NM。
--num-executors: 配置 Executor 的数量
--executor-memory: 配置每个 Executor 的内存大小
--executor-cores: 配置每个 Executor 的虚拟 CPU core 数量
- Task:被送到某个Executor上的工作单元。
➢Spark 中的任务分为两种:ShuffleMapTask 与 ResultTask。
➢RDD在计算的时候,每个分区都会启一个task,所以rdd的分区数目决定了总的的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。 - Job :包含多个Task组成的并行计算,往往由Spark Action算子触发生成,一个Application中往往会产生多个Job。
➢每触发一次action动作算子就会产生一个Job,Job内部会根据是否有shuffle过程分割为多个Stage - Stage:每个Job会被拆分成多组Task,作为一个TaskSet,其名称为Stage
⚫ Application:初始化一个 SparkContext 即生成一个Application;
⚫ Job:一个Action 算子就会生成一个Job;
⚫ Stage:Stage 等于宽依赖(ShuffleDependency)的个数加 1;
⚫ Task:一个 Stage 阶段中,最后一个RDD 的分区个数就是Task 的个数。
3、提交流程
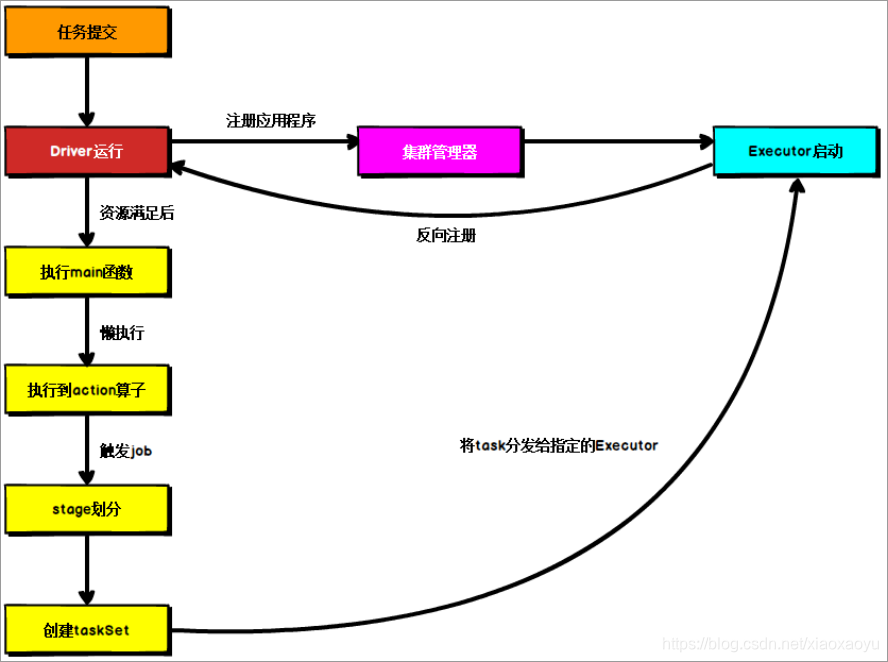
- 当执行一个Application时,Driver会通过SparkContext向集群管理器申请资源,启动Executor
- Executor启动后向Driver反向注册,全部注册完之后执行main函数
- 之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个 stage 生成对应的 TaskSet(,这一步由DAGScheduler执行)。
- 之后(由TaskScheduler)将 task 分发到各个 Executor 上执行。
- (由SchedulerBackend给Task分配Executor计算资源并启动Task)(分配,分发,启动)
- 运行结束后,执行结果会返回给Driver,或者写到HDFS或者其它数据库中。
四、核心API
- SparkContext,连接Driver与Spark Cluster(Workers),是Spark的主入口,每个JVM仅能有一个活跃的SparkContext,创建方式SparkContext.getOrCreate
//CreateSparkContext
object CreateSparkContext {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName("HelloSpark")
val sc = SparkContext.getOrCreate(conf)
val rdd = sc.parallelize(1 to 10)
rdd.foreach(println(_))
}
}
- SparkSession是Spark 2.0+应用程序的主入口:包含了SparkContext、SQLContext、HiveContext以及StreamingContext。使用方法为SparkSession.getOrCreate
//CreateSparkSession
object CreateSparkSession{
def main(args: Array[String]): Unit = {
SparkSession.builder().master("local[2]").
appName("appName").getOrCreate().sparkContext.
parallelize(1 to 10).foreach(println(_))
}
}
五、RDD是什么,有哪些特点
弹性分布式数据集(Resilient Distributed Datasets),Spark中最基本的数据处理模型,抽象类,代表一个弹性的、不可变、可分区、里边的元素可并行计算的集合
- 弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动切换
- 计算的弹性:计算出错重试机制
- 分片的弹性:可根据需要重新分片
- 分布式
- RDD是只读的、分区记录的集合,每个分区分布在集群的不同节点上
- 数据集
- 封装计算逻辑,并不保存数据
- 数据抽象
- 抽象类,需要子类具体实现
- 不可变
- 封装的计算逻辑是不可以改变的
- 可分区
- 并行计算
六、RDD的特性
- 一系列的分区(分片)信息,每个任务处理一个分区
- 每个分区上都有compute函数,计算该分区中的数据
- RDD之间有一系列的依赖
- 分区器决定数据(key-value)分配至哪个分区
- 优先位置列表,将计算任务分派到其所在处理数据块的存储位置
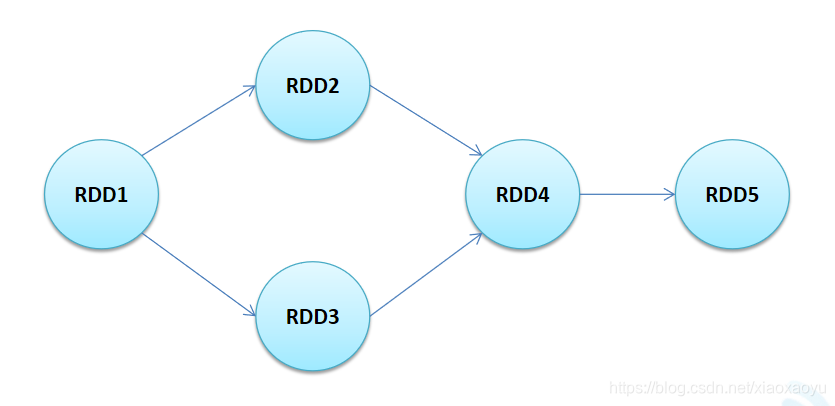
DAG(有向无环图)反映了RDD之间的依赖关系
七、RDD常用的创建方式
RDD编程流程:创建 - 转化 - 持久化 - 执行
- 使用集合创建RDD
- 从外部存储(文件)创建RDD
- SparkContext.wholeTextFiles():可以针对一个目录中的大量小文件返回<filename,fileContent>作为PairRDD
- 其他创建RDD的方法:
➢SparkContext.sequenceFile[K,V]()——Hadoop SequenceFile的读写支持
➢SparkContext.hadoopRDD()、newAPIHadoopRDD()——从Hadoop接口API创建
➢SparkContext.objectFile()——RDD.saveAsObjectFile()的逆操作
//使用集合创建RDD
object createRDD{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass().getSimpleName().filter(!_.equals('$')))
val sc = SparkContext.getOrCreate(conf)
sc.makeRDD(List("a","b","c","d","e")).map(x=>(x,1)).foreach(println)
println(sc.parallelize(List(1, 2, 3, 4, 5)).count())
println(sc.parallelize(List(1, 2, 3, 4, 5)).partitions.size)
println(sc.parallelize(List(1, 2, 3, 4, 5),5).count())
println(sc.parallelize(List(1, 2, 3, 4, 5),5).partitions.size)
}
}
//获取文件
object loadFile{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass().getSimpleName().filter(!_.equals('$')))
val sc = SparkContext.getOrCreate(conf)
val hdfsFile = sc.textFile("hdfs://192.168.221.140:9000/kb10/customers")
val localFile = sc.textFile("D:\\JavaProjects\\ClassStudy\\Scala\\scalatest\\files\\04student\\score.txt")
println(hdfsFile.count())
println(localFile.count())
//还可以通过文件夹/*.txt通配符方式获取符合条件的所有文件。但不常用
}
}
//SparkContext.wholeTextFiles():可以针对一个目录中
//的大量小文件返回<filename,fileContent>作为PairRDD
object pairRDD{
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass().getSimpleName().filter(!_.equals('$')))
val sc = SparkContext.getOrCreate(conf)
sc.wholeTextFiles("D:\\JavaProjects\\ClassStudy\\Scala\\scalatest\\files\\04student\\")
.foreach(println(_))//输出<filename,fileContent>格式
}
}
八、RDD常用的算子:转换、动作
九、端口号

- Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
- Spark Master 内部通信服务端口号:7077
- Standalone 模式下,Spark Master Web 端口号:8080(资源)
- Spark 历史服务器端口号:18080
- Hadoop YARN 任务运行情况查看端口号:8088
九、基于RDD的应用程序开发
目的:在IDEA中编写程序,然后打可执行包传到虚拟机下,通过可执行包运行结果
方式1:
- Linux下的shell命令:
spark-submit \
--class cn.xym.spark.Ages \
--master local[2] /root/hadooptmp/sparkdemo-1.0-SNAPSHOT.jar
- 命令解释:
cn.xym.spark.Ages——包cn.xym.spark下的Object文件Ages
package cn.xym.spark
import org.apache.spark.{
SparkConf, SparkContext}
object Ages {
def main(args: Array[String]): Unit = {
val sc = new SparkContext(new SparkConf().setMaster("local[*]").setAppName("avg-age"))
//文件存储路径要么是虚拟机下,要么是HDFS上
val user = sc.textFile("hdfs://192.168.221.140:9000/kb10/user-age.txt")
val ageRDD = user.map(x => {
val y = x.split(" ")
y(1).toInt
})
println(ageRDD.reduce(_ + _).toDouble / ageRDD.count())
}
}
-
命令解释:
/root/hadooptmp/sparkdemo-1.0-SNAPSHOT.jar——虚拟机下的jar包存放路径 -
最终输出如下
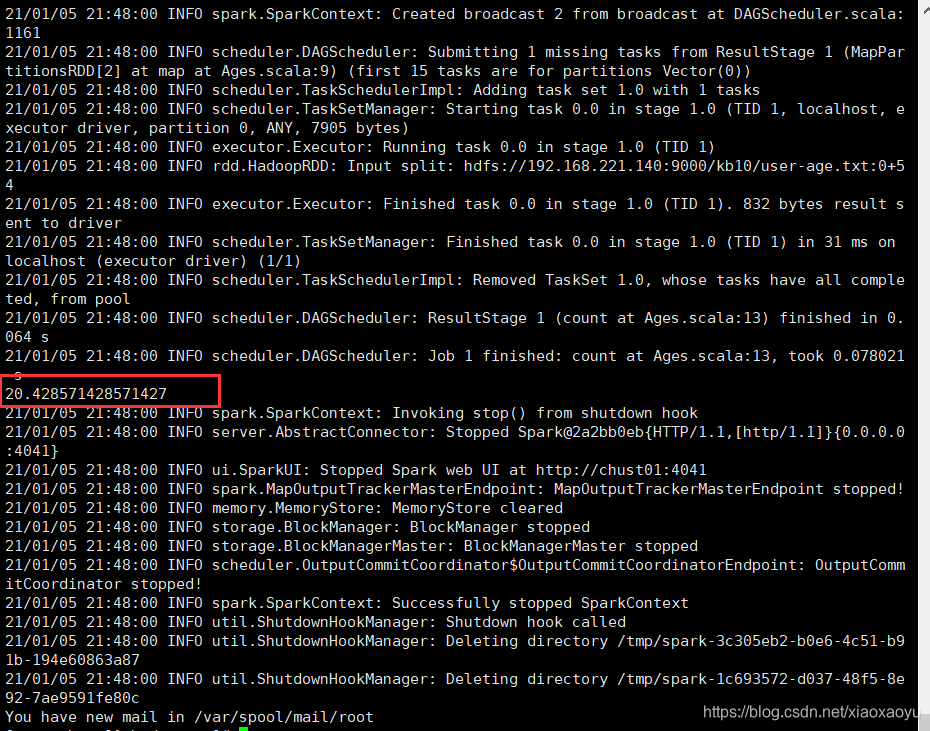
方式2:修改jar包的MANIFEST.MF内容,在底边加一行:Main-Class:主类路径。然后shell命令可以改为
spark-submit /root/hadooptmp/sparkdemo-1.0-SNAPSHOT.jar
十、shuffle机制
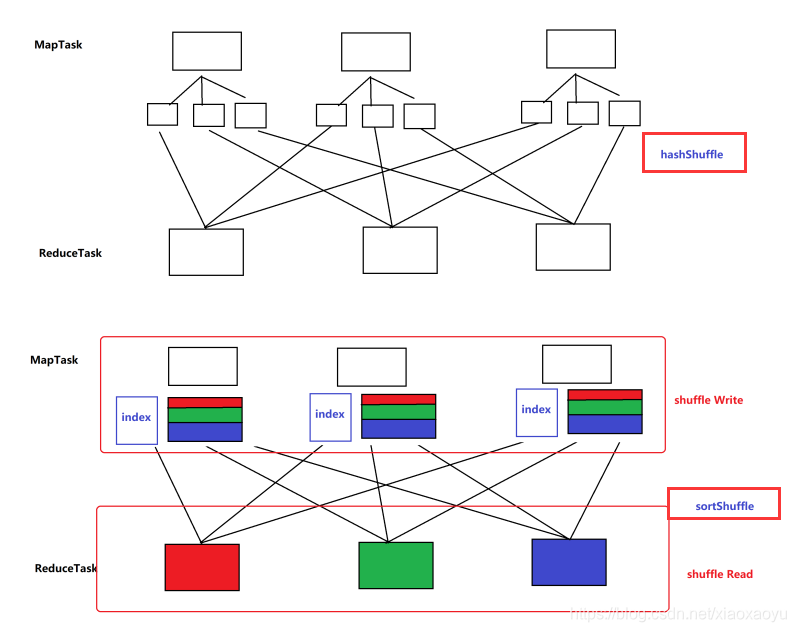
目前版本使用的是SortShuffleManager:每个 Task 在 Shuffle Write 操作时,将所有的临时文件合并 (merge) 成一个磁盘文件。在下一个 Stage 的 Shuffle Read Task 拉取自己数据的时候,只要根据索引拉取每个磁盘文件中的部分数据即可。
1、ShuffleWriter
有三种实现以及对应的 Handle:
- BypassMergeSortShuffleWriter:BypassMergeSortShuffleHandle
➢如果分区小于spark.shuffle.sort.bypassMergeThreshold(默认 200),且map 端没有聚合操作,使用 BypassMergeSortShuffleHandle,否则进入下一个条件。 - UnsafeShuffleWriter:SerializedShuffleHandle
➢如果map 端没有聚合操作,且 Serializer 支持重定位(即使用 KryoSerializer),且分区数目小于 16777216(最大分区号)时使用 SerializedShuffleHandle。否则进入下一条件。 - SortShuffleWriter:BaseShuffleHandle
➢以上条件都不满足时使用 BaseShuffleHandle。对应的 ShuffleWrite 是 SortShuffleWriter,支持 map 端聚合操作,同时支持排序。这种是最通用的 Writer。Sort ShuffleWriter 使相同的 ShuffleMapTask 公用一个输出文件,然后创建一个索引文件对这个文件进行索引。在一个文件里做分区偏移
2、Shuffle Read 操作发生在 ShuffledRDD的compute 方法中,意味着 Shuffle Read 可以发生 ShuffleMapTask 和 ResultTask 两种任务中。
- 每个 Stage 的上边界,要么需要从外部存储读取数据;要么需要读取上一个 Stage 的输出
- 每个 Stage 的下边界,要么需要写入本地文件系统(Shuffle),以供下一个 Stage 读取;要么是最后一个 Stage,需要输出结果。
- 除了需要从外部存储读取数据和 RDD 已经持久化(Cache、Checkpoint),一 般 Task 都是从 ShuffledRDD 的 Shuffle Read 开始的。
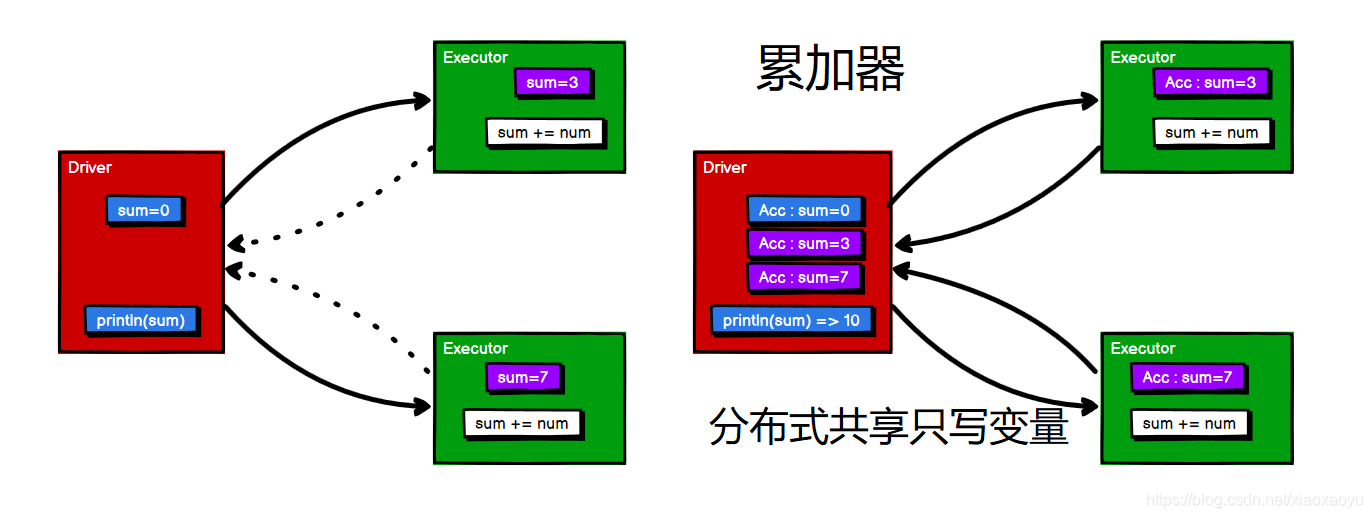
十一、累加器(可自定义)
在driver端使用的数据和RDD进行计算时,需要使用累加器,否则无法添加
object Accu1 {
def main(args: Array[String]): Unit = {
val sc = SparkContext.getOrCreate(new SparkConf()
.setMaster("local[*]").setAppName(this.getClass.getSimpleName))
val rdd = sc.makeRDD(List(1, 2, 3, 4))
val sum = sc.longAccumulator("sum")
rdd.foreach(x => {
sum.add(x)
})
println("sum=" + sum.value)
}
}