一、RDD重用和存储级别选择
- 借助缓存的方式,cache、persist、checkpoint
- 缓存是构建 Spark 迭代计算和交互式查询的关键每个 RDD 的 compute 执行时,将判断缓存的存储级别。如果指定过存储级别则读取缓存

二、广播变量
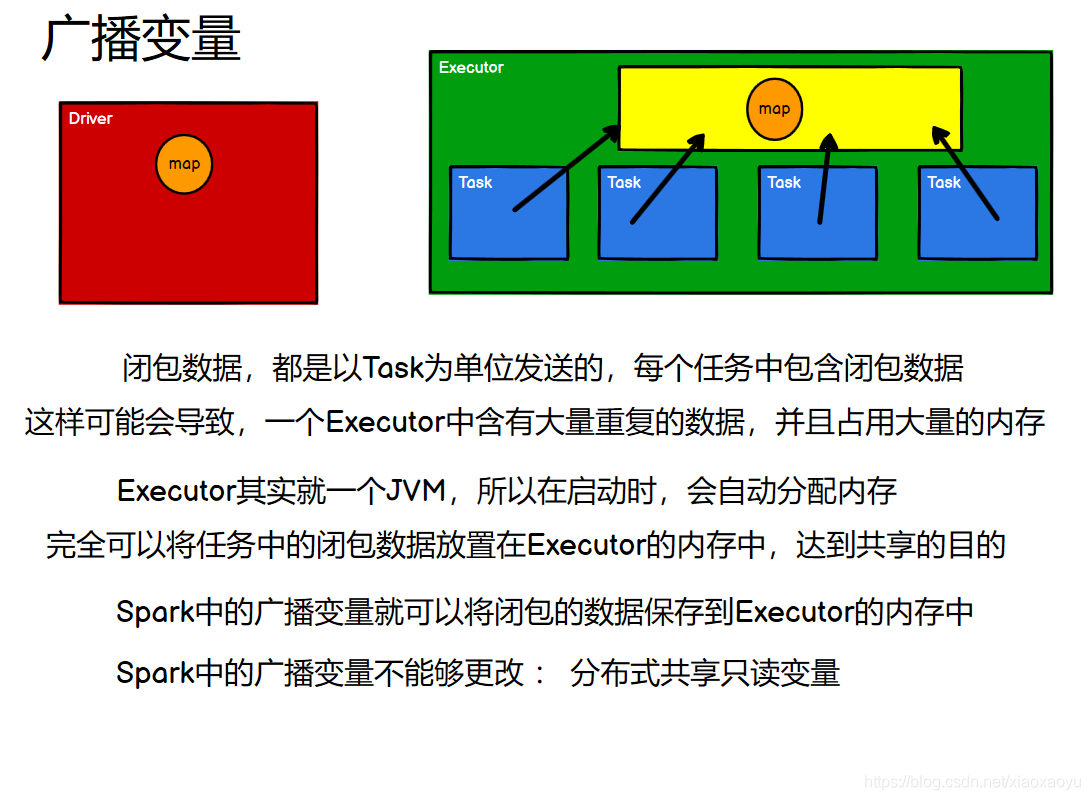
- 类似mapJoin把小表放到内存,广播变量是把小数据广播出去分发给(缓存到)各个节点
- 允许开发者将一个只读变量(Driver 端)缓存到每个节点(Executor)上, 而不是每个任务传递一个副本。注意,不能对 RDD 进行广播。因为不能传播血缘关系DAG
- 可以广播DataFrame和DataSet
object BroadCast {
def main(args: Array[String]): Unit = {
val sc = SparkContext.getOrCreate(new SparkConf().setMaster("local[*]").setAppName(this.getClass.getSimpleName))
val bc = sc.broadcast(Array(5, 2, 3))
//1、Driver端变量在每个Executor每个Task保存一个变量副本
//2、Driver端广播变量在每个Executor只保存一个变量副本
sc.makeRDD(1 to 10, 1).map(x => x * bc.value(0)).collect.foreach(println)
sc.makeRDD(1 to 10, 1).map(x => x * bc.value(1)).collect.foreach(println)
sc.makeRDD(1 to 10, 1).map(x => x * bc.value(2)).collect.foreach(println)
}
}
三、RDD分区设计
Spark 官方推荐,task 数量应该设置为 Spark 作业总CPU core 数量的 2~3 倍
- 分区太少,不利于并发,即不会使用集群中所有可用的 CPU 核心,更容易受数据倾斜影响,groupBy, reduceByKey, sortByKey 等内存压力增大
- 分区过多,Shuffle 开销越大,创建任务开销越大。
并行度设置
val conf = new SparkConf() .set("spark.default.parallelism", "500")
四、优化序列化性能
- Java序列化机制比较重,有很多内置信息, 效率不高,序列化速度慢并且序列化后的数据所占用的空间依然较大。
- Kryo 序列化机制比 Java 序列化机制性能提高 10 倍左右,Spark 之所以没有默认使用 Kryo 作为序列化类库,是因为它不支持所有对象的序列化,同时 Kryo 需要用户在使用前注册所需要序列化的类型,不够方便,但从 Spark 2.0.0 版本开始,简单类型、简单类型数组、字符 串类型的 Shuffling RDDs 已经默认使用Kryo 序列化方式了。
//创建 SparkConf 对象
val conf = new SparkConf().setMaster(…).setAppName(…)
//使用 Kryo 序列化库,如果要使用 Java 序列化库,需要把该行屏蔽掉
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在 Kryo 序列化库中注册自定义的类集合,如果要使用 Java 序列化库,需要把该行屏蔽掉
conf.set("spark.kryo.registrator", "atguigu.com.MyKryoRegistrator");
五、简化结构
- 不要用Java的结构,因为Java里有个对象头(Mark Word 指向类的指针,数组长度(数组对象才有),记录类信息,每个对象强关联类型,因此会很重。用scala原生的结构
六、数据倾斜
- 会触发 shuffle 操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、 join、cogroup、repartition 等。出现数据倾斜时,可能就是代码中使用了这些算子中的某一个所导致的。
- 在 Spark Web UI 上深入看一下当前这个 stage 各个 task 分配的数据量,从而 进一步确定是不是 task 分配的数据不均匀导致了数据倾斜。

七、
- RDD重用:避免创建同一个RDD;尽可能的复用同一个RDD
- RDD尽可能早的 filter 操作:获取到初始 RDD 后,应该考虑尽早地过滤掉不需要的数据,进而减少对内存的占用, 从而提升 Spark 作业的运行效率
- 调节本地化等待时长:默认3秒,3秒没有等到资源就会传到其他节点
val conf = new SparkConf() .set("spark.locality.wait", "6")