spark源码阅读笔记RDD(一)RDD的基本概念
什么是RDD?
从文献1我们知道,Matei Zaharia博士给RDD下的定义是:
Formally, an RDD is aread-only,partitionedcollection ofrecords。关键词有只读、已分区记录的集合,也就是
说:我们操作的RDD是一个只可读不可写的集合,而且这个集合是已经分好区且会有标记的集合。下面我们通过源码
来说明一下RDD为什么是只读、已分区记录的集合。(源码见附录源码1):总结如下:
1、每个RDD都包含五部分信息:
(1)数据分区的集合:partitions
(2)能根据本地性快速访问到数据的偏好位置:preferredLocations
(3)一个RDD的依赖列表:dependencies
(4)一个RDD的分区数:getNumPartitions
(5)一个RDD的计算迭代器:iterator
2、这五个信息都是用final修饰的,也就是说不可改变、只读的
3、一个job下的各RDD的信息
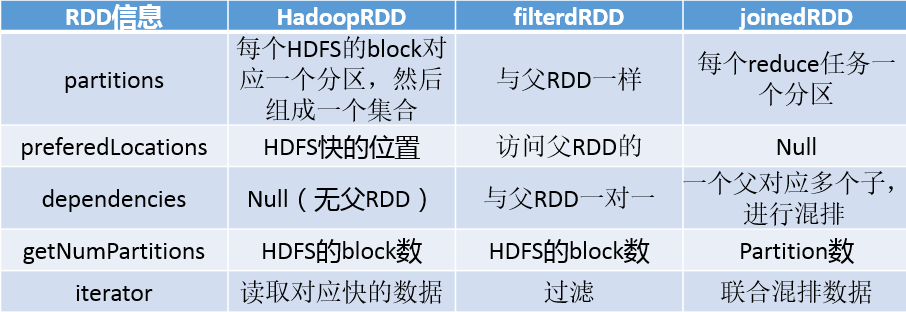
RDD怎么创建?
RDD只能通过(1)稳定的存储器(比如HDFS)(2) 其他的RDD的数据上的确定性操作来创建(也就是转换操
作)正因为RDD的record的特性,RDD之间转换会记录如何转换而来,它的最厉害的一个特性就是当一个RDD失效
了,程序可以凭借记录,唤起这个失效的RDD.
RDD怎么实现?
下面是RDD class源码
abstract class RDD[T: ClassTag]( *RDD是继承于Serializable(对象可以被序列化),Logging(创建SLF4J用于记录) * _sc:一个sparkContext包含环境等变量 * deps: Seq[Dependency[_]],用于记录之间的依赖关系 * */ @transient private var _sc: SparkContext, @transient private var deps: Seq[Dependency[_]] ) extends Serializable with Logging {/*集合体*/}从RDD类知道,包含:
1、集群(或其他模式)的属性
2、记录运行的步骤
3、记录RDD之间的依赖关系
RDD五个主要的属性
* Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file)1)一组分片(partition):partition是数据集的基本的组成单位,每个分片都会被一个计算任务处理。这个分片决定计算的粒度。分片可以自己设置也可以系统默认(根据你的CPU的core的数目来决定,每个core 2-4个分片),但是
自己设置的时候一个partition不要超过一个block的最大容量
小插曲:存储的基本单位是block:一个partition 逻辑映射(by BlockManager)一个block,被一个task负责计算
2)一个计算每个分区(Split)的函数,每个RDD都会实现compute函数来对RDD进行分片
3)一个和其他RDD之间依赖关系的列表(List):RDD每次转换生成新的RDD,这个新的RDD会记录父RDD的信
息。所以RDD直接会形成类似于流水线一样的依赖关系。
4)一个partitioner(RDD的分片函数),spark有两个类型的分片函数,HashPartitioner和非key-value的
paritioner(值默认为None)
5)一个用于存储每个partition优先位置的列表(list),也就是说这个list保存了每个partition所在那个block的位置
实验总结
其中程序中的数据形式如下图:

import org.apache.spark.{SparkConf, SparkContext} /** * Created by legotime on 2016/4/21. */ object WorkSheet { def main(args: Array[String]) { val conf = new SparkConf().setAppName("RDD的基本理解").setMaster("local") val sc = new SparkContext(conf) // Load the data val data1 = sc.textFile("E:\\SparkCore2\\data\\mllib\\ridge-data\\lpsa.data") println("data1的类型"+data1) //MapPartitionsRDD[1] at textFile at WorkSheet.scala:15 println("data1的partittion:" + data1.partitions.size)//1 println("data1的length:" +data1.collect.length)//67 println("data1的count:" +data1.count())//67 println("缓存:"+data1.cache()) //MapPartitionsRDD[1] at textFile at WorkSheet.scala:15 println("data1的name:"+data1.name) //data1的name:null println("data1的id:"+data1.id) //data1的id:1 data1.partitions.foreach { partition => println("index:" + partition.index + " hasCode:" + partition.hashCode()) }//index:0 hasCode:1681 println("data1 father dependency: " + data1.dependencies) //data1 father dependency: List(org.apache.spark.OneToOneDependency@36480b2d) data1.dependencies.foreach { dep => println("dependency type:" + dep.getClass) println("dependency RDD:" + dep.rdd) println("dependency partitions:" + dep.rdd.partitions) println("dependency partitions size:" + dep.rdd.partitions.length) } //dependency type:class org.apache.spark.OneToOneDependency //dependency RDD:E:\SparkCore2\data\mllib\ridge-data\lpsa.data HadoopRDD[0] at textFile at WorkSheet.scala:15 //dependency partitions:[Lorg.apache.spark.Partition;@3c3c4a71 //dependency partitions size:1 // val data1Map = data1.map(_+1) //经过一次转换 data1Map.dependencies.foreach { dep => println("dependency type:" + dep.getClass) println("dependency RDD:" + dep.rdd) println("dependency partitions:" + dep.rdd.partitions) println("dependency partitions size:" + dep.rdd.partitions.length) } //dependency type:class org.apache.spark.OneToOneDependency //dependency RDD:MapPartitionsRDD[1] at textFile at WorkSheet.scala:15 //dependency partitions:[Lorg.apache.spark.Partition;@3c3c4a71 //dependency partitions size:1 println("data1Map father dependency: " + data1Map.dependencies) //data1Map father dependency: List(org.apache.spark.OneToOneDependency@b887730) data1Map.dependencies.foreach(x => println("data1Map的依赖:"+x) ) //data1Map的依赖:org.apache.spark.OneToOneDependency@b887730 val data2 = sc.textFile("E:\\SparkCore2\\data\\mllib\\ridge-data\\lpsa.data",2) println("data2的类型"+data2) //data2的类型MapPartitionsRDD[4] at textFile at WorkSheet.scala:45 println("data2的partittion:" + data2.partitions.size)//2 println("data2的length:" +data2.collect.length)//67 println("data2的count:" +data2.count())//67 println("缓存:"+data2.cache()) //缓存:MapPartitionsRDD[4] at textFile at WorkSheet.scala:45 println("data2的name:"+data2.name) //data2的name:null data2.setName("huhu!!") println("data2的new name:"+data2.name) //data2的new name:huhu!! println("data2的id:"+data2.id) //data2的id:4 data2.partitions.foreach { partition => println("index:" + partition.index + " hasCode:" + partition.hashCode()) } //index:0 hasCode:1804 //index:1 hasCode:1805 println(data2.first()) //-0.4307829,-1.63735562648104 -2.00621178480549 -1.86242597251066 -1.02470580167082 -0.522940888712441 -0.863171185425945 -1.04215728919298 -0.864466507337306 //println(data2.take(0))//java.lang.String;@5f2bd6d9 println(data2.take(2)) sc.stop() } }分析:
1、所说的partition就是把一个大的数据分成几块,这个partition放入一个函数中,partition中有基本的element
这个element是函数处理的最小单元(这个element也就是一行)
2、从依赖关系:一个RDD的知道父的RDD,不知道爷爷以上的RDD,如果要知道爷爷RDD,那么就通过父RDD来得到
、依次类推,可以回溯到第一个RDD
3、一个RDD默认的名字是null,名字可以自己设置,但是作用不大
4、每个RDD都有一个编号,每向上回溯一次,系统都可以判断父RDD是否存在(cache、persist)
附录:
源码1
/** * Get the list of dependencies of this RDD, taking into account whether the * RDD is checkpointed or not */ final def dependencies: Seq[Dependency[_]] = { checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse { if (dependencies_ == null) { dependencies_ = getDependencies } dependencies_ } } /** * Get the array of partitions of this RDD, taking into account whether the * RDD is checkpointed or not. */ /** * 得到我们调用partitions函数的RDD的一个包含partition信息的数组 * 然后把这个数组放入计算,判断这个RDD是否checkpoint */ final def partitions: Array[Partition] = { checkpointRDD.map(_.partitions).getOrElse { if (partitions_ == null) { partitions_ = getPartitions partitions_.zipWithIndex.foreach { case (partition, index) => require(partition.index == index, s"partitions($index).partition == ${partition.index}, but it should equal $index") } } partitions_ } } /** * Returns the number of partitions of this RDD. */ @Since("1.6.0") final def getNumPartitions: Int = partitions.length /** * Get the preferred locations of a partition, taking into account whether the * RDD is checkpointed. */ final def preferredLocations(split: Partition): Seq[String] = { checkpointRDD.map(_.getPreferredLocations(split)).getOrElse { getPreferredLocations(split) } } /** * Internal method to this RDD; will read from cache if applicable, or otherwise compute it. * This should ''not'' be called by users directly, but is available for implementors of custom * subclasses of RDD. */ final def iterator(split: Partition, context: TaskContext): Iterator[T] = { if (storageLevel != StorageLevel.NONE) { getOrCompute(split, context) } else { computeOrReadCheckpoint(split, context) } }
参考文献
1、http://www.eecs.berkeley.edu/Pubs/TechRpts/2014/EECS-2014-12.pdf