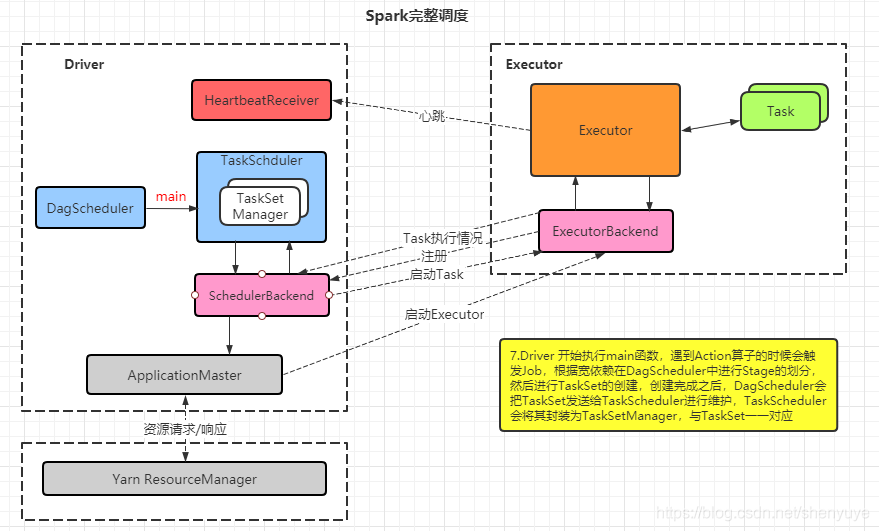
1.当Driver启动的时候,初始化时会相应的创建DagScheduler、TaskScheduler
2.TaskScheduler初始化的时候,会创建SchedulerBacked(主要负责集群之间的通讯)
3.SchedulerBacked和ApplicationMaster进行通讯,SchedulerBacked会告诉ApplicationManager会启动多少个Executor
4.然后ApplicationManager会向ResourceManager申请资源
5.然后启动相应的Executor
6.Executor调用ExecutorBackend向Driver里面的ScheduleBackend注册,当所有的Executor都注册完之后
7.Driver 开始执行 main 函数,遇到 Action 算子的时候会触发 Job ,根据宽依赖在DagScheduler中进行Stage的划分,然后进行TaskSet的创建,创建完成之后,DagScheduler会把TaskSet发送给TaskScheduler进行维护,TaskSchedule会将其封装为TaskSetManager,与TaskSet一一对应
8.TaskScheduler以一定的调度策略,决定哪个Task被执行,然后决定要到哪一个Executor上执行
9.然后SchedulerBackend与ExecutorBackend建立通讯,告诉哪一个Executor执行
10.然后Executor开始执行
11.在执行过程中,Executor会不断的发送心跳给Driver的HeartbeatReceiver,从而使实时监测Executor是否是工作状态的(active),
12.同时,Executor在执行Task过程中,会把每一个Task的运行情况通过ExecutorBackend发送给ScheduleBackend
13.ScheduleBackend会进一步把这些运行情况发送给TaskScheduler,从而使TaskScheduler掌握当前运行在每一个Executor上的Task的运行状态,一旦某个Task执行失败,TaskScheduler就会重新调度,重新选择Executor执行Task
简单来说
,Action算子 触发 Job ,DAGScheduler对象 根据 宽依赖 划分 Stage ,根据 Stage 里所处理的数据,决定有多少个 Task ,然后创建对应的 TaskSet ,然后交给 TaskScheduler 进行调度,交给 SchedulerBackend(用于Driver和其他组件交互) ,发送个对应的 Executor 执行。 Executor 执行多少个 Task 由 TaskSchedule 决定。
各个相关组件详解
Driver:
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业中执行时主要负责:
1.将用户程序转化为任务(job)
2.在Executor之间调度任务(task)
3.跟踪Executor的执行情况
4.通过UI展示查询运行情况
Executor:
Executor节点是一个JVM进程,负责在Spark作业中运行具体任务,任务彼此相互独立。Spark启动时,Executor节点同时被启动,并且始终伴随整个Spark应用的生命周期,如果发生故障,Spark应用也可以继续执行,会将出错节点上的任务调度到其他Executor节点上继续执行。
Executor核心功能:
1.负责运行组成Spark应用的任务,并将结果返回给驱动器进程;
2.通过自身块管理器为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据的加速运算。
Master:是一个进程,主要负责资源的调度和分配,并进行集群的监控等职责
Worker:是一个进程,一个 Worker 运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储 RDD 的某个或某些 partition;另一个是启动其他进程和线程(Executor) ,对 RDD 上的 partition 进行并行的处理和计算。
YARN Cluster模式
1.任务提交后会和 ResourceManager 通讯申请启动 ApplicationMaster ,随后 ResourceManager 分配 container ,在合适的 NodeManager 上启动 ApplicationManager ,此时 ApplicationManager 就是Driver ;
2.Driver 启动后向 ResourceManager 申请 Executor 内存,ResourceManager 接到ApplicationManager 的资源申请后会分配 container ,然后在合适的NodeManager上启动 Executor 进程,Executor 进程启动后会向 Driver 反向注册;
3.Executor 全部注册完成后 Driver 开始执行 main 函数,之后执行 Action 算子时,触发一个job,并根据宽窄依赖划分 stage ,每个stage生成对应的taskSet,之后分发到各个 Executor 上执行。
补充
Spark的任务调度主要集中在两个方面:资源申请和任务分发。
Job是以 Action 方法为界,遇到一个 Action 方法则触发一个Job;
Stage是 Job 的子集,以 RDD 款依赖(即Shuffle)为界,遇到一个 Shuffle 做一次划分;
Task 是 Stage 的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task,一个 task 对应一个RDD分区 ,如果数据来自HDFS,一个分区的数据就是一个 split 的数据。
+++++++++++++++++++++++++++++++++++++++++
+ 如有问题可+Q:1602701980 共同探讨 +
+++++++++++++++++++++++++++++++++++++++++