1.1设备驱动的作用
驱使硬件设备行动
驱动与底层硬件直接打交道, 按照硬件设备的具体工作方式, 读写设备的寄存器, 完成设备的轮询、 中断处理、 DMA通信, 进行物理内存向虚拟内存的映射等, 最终让通信设备能收发数据, 让显示设备能显示文字和画面, 让存储设备能记录文件和数据。
设备驱动充当了硬件和应用软件之间的纽带, 应用软件时只需要调用系统软件的应用编程接口(API) 就可让硬件去完成要求的工作。
1.4.1 设备的分类及特点
计算机系统的硬件组成CPU、存储器、外设
大部分的CPU内部集成了存储器和外设适配器(UART、I2C控制器、SPI控制器、USB控制器、SDRAM控制器、GPU、视频解码器)
3大基础大类:字符设备、块设备、网络设备
字符设备:以串行顺序依次进行访问的设备
块设备:可以按照任意顺序进行访问,以块为单位
网络设备:面向数据包的接收和发送而设计,使用套接字接口,不倾向于文件系统的接点。

1.6.1 无操作系统时的LED驱动
在嵌入式系统中,LED一般直接由CPU的GPIO(通用可编程I/O)口控制。
GPIO一般由两组寄存器控制(控制寄存器和数据寄存器)。
控制寄存器可设置GPIO的工作方式为输入或输出。
ToVirtual()的作用:当系统启动了硬件MMU,根据物理地址和虚拟地址的映射关系,将寄存器的物理地址转化为虚拟地址。
2.3.2 I2C
I2C(Inter-Integrated Circuit内置集成电路)总线时两线式串行总线
I2C 总线简单有效,占用PCB空间小,芯片引脚数量少,设计成本低。
支持多主控模式,任何能够进行发送和接收的设备都可以成为主设备。
主控能够控制数据的传输和时钟频率,在任意时刻只能有一个主控
两个信号:数据线SDA和时钟SCL
I2C设备上的串行数据线SDA接口电路是双向的, 输出电路用于向总线上发送数据, 输入电路用于接收总线上的数据。 同样地, 串行时钟线SCL也是双向的, 作为控制总线数据传送的主机要通过SCL输出电
路发送时钟信号, 并检测总线上SCL上的电平以决定什么时候发下一个时钟脉冲电平; 作为接收主机命令的从设备需按总线上SCL的信号发送或接收SDA上的信号, 它也可以向SCL线发出低电平信号以延长总线时钟信号周期
2.3.3 SPI
SPI( Serial Peripheral Interface, 串行外设接口) 总线系统是一种同步串行外设接口, 它可以使CPU与各种外围设备以串行方式进行通信以交换信息。 一般主控SoC作为SPI的“主”, 而外设作为SPI的“从”。
SPI接口一般使用4条线: 串行时钟线( SCLK) 、 主机输入/从机输出数据线MISO、 主机输出/从机输入数据线MOSI和低电平有效的从机选择线SS( 在不同的文献里, 也常称为nCS、 CS、 CSB、 CSN、nSS、 STE、 SYNC等)
3.3.2 Linux内核的组成部分
Linux内核主要由进程调度(SCHED) 、 内存管理(MM) 、 虚拟文件系统(VFS) 、网络接口(NET) 和进程间通信(IPC) 5个子系统组成。
1.进程调度
进程调度控制系统中的多个进程对CPU的访问, 使得多个进程能在CPU中“微观串行, 宏观并行”地执行。 进程调度处于系统的中心位置, 内核中其他的子系统都依赖它, 因为每个子系统都需要挂起或恢复进程
在Linux内核中, 使用task_struct结构体来描述进程, 该结构体中包含描述该进程内存资源、 文件系统资源、 文件资源、 tty资源、 信号处理等的指针。 Linux的线程采用轻量级进程模型来实现, 在用户空间通过pthread_create() API创建线程的时候, 本质上内核只是创建了一个新的task_struct, 并将新task_struct的所有资源指针都指向创建它的那个task_struct的资源指针。
绝大多数进程(以及进程中的多个线程) 是由用户空间的应用创建的, 当它们存在底层资源和硬件访问的需求时, 会通过系统调用进入内核空间。 有时候, 在内核编程中, 如果需要几个并发执行的任务, 可以启动内核线程, 这些线程没有用户空间。 启动内核线程的函数为
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
2.内存管理
32位处理器的Linux的每个进程享有4GB的内存空间, 0~3GB属于用户空间, 3~4GB属于内核空间,Kernel Features→Memory split可调整内核空间和用户空间的界限
3.虚拟文件系统
Linux虚拟文件系统隐藏了各种硬件的具体细节, 为所有设备提供了统一的接口。 而
且, 它独立于各个具体的文件系统, 是对各种文件系统的一个抽象。 它为上层的应用程序提供了统一的vfs_read() 、 vfs_write() 等接口, 并调用具体底层文件系统或者设备驱动中实现的file_operations结构体的成员函数。
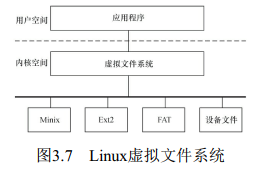
4.网络接口
网络接口可分为网络协议和网络驱动程序, 网络协议部分负责实现每一种可能的网络传输协议, 网络设备驱动程序负责与硬件设备通信, 每一种可能的硬件设备都有相应的设备驱动程序。

3.3.3 Linux内核空间与用户空间
内核空间和用户空间这两个名词用来区分程序执行的两种不同状态, 它们使用不同的地址空间。Linux只能通过系统调用和硬件中断完成从用户空间到内核空间的控制转移
3.4.1 Linux内核的编译
make config
编译内核和模块
make ARCH=arm zImage
make ARCH=arm modules
第4章 Linux内核模块
4.1 Linux内核模块简介
编译进内核:生成的内核变大,新增删除功能,重新编译内核。
模块机制:模块本身不被编译进内核映像,控制内核大小;模块一旦被加载,和内核其他部分一样。
加载:insmod ./hello.ko
卸载:rmmod hello
查看模块:
lsmod 读取分析/proc/modules
或者cat /proc/modules
modprobe 加载模块同时加载模块的依赖模块
modprobe-r hello 卸载模块及其依赖模块
modinfo hello 获取模块信息
4.3 模块加载函数
模块加载函数以“module_init(函数名) ”的形式被指定。
request_model()代码中加载内核模块
所有标识为__init的函数如果直接编译进入内核, 成为内核镜像的一部分, 在连接的时候
都会放在.init.text这个区段内。
#define _ _init _ _attribute_ _ ((_ _section_ _ (".init.text")))
4.4 模块卸载函数
模块卸载函数在模块卸载的时候执行, 而不返回任何值, 且必须以“module_exit(函数名) ”的形式来
指定。 通常来说, 模块卸载函数要完成与模块加载函数相反的功能。
第5章 Linux文件系统与设备文件
5.2.2 Linux文件系统与设备驱动
应用程序和VFS之间的接口是系统调用, 而VFS与文件系统以及设备文件之间的接口是file_operations
结构体成员函数, 这个结构体包含对文件进行打开、 关闭、 读写、 控制的一系列成员函数


1.file结构体
file结构体代表一个打开的文件, 系统中每个打开的文件在内核空间都有一个关联的struct file。 它由内
核在打开文件时创建, 并传递给在文件上进行操作的任何函数。 在文件的所有实例都关闭后, 内核释放这
个数据结构。 在内核和驱动源代码中, struct file的指针通常被命名为file或filp(即file pointer) 。
2.inode结构体
VFS inode包含文件访问权限、 属主、 组、 大小、 生成时间、 访问时间、 最后修改时间等信息。
主设备号是与驱动对应的概念, 同一类设备一般使用相同的主设备号, 不同类的设备一般使用不同的
主设备号
因为同一驱动可支持多个同类设备, 因此用次设备号来描述使用该驱动的设备的序号, 序号一般从0开始。
device_driver和device分别表示驱动和设备, 而这两者都必须依附于一种总线, 因此都包含struct
bus_type指针。 在Linux内核中, 设备和驱动是分开注册的, 注册1个设备的时候, 并不需要驱动已经存
在, 而1个驱动被注册的时候, 也不需要对应的设备已经被注册。 设备和驱动各自涌向内核, 而每个设备
和驱动涌入内核的时候, 都会去寻找自己的另一半, 而正是bus_type的match() 成员函数将两者捆绑在一
起。
总线、 驱动和设备最终都会落实为sysfs中的1个目录, 因为进一步追踪代码会发现, 它们实际
上都可以认为是kobject的派生类, kobject可看作是所有总线、 设备和驱动的抽象基类, 1个kobject对应
sysfs中的1个目录。
第6章 字符设备驱动
6.1.1 cdev结构体
1struct cdev {
2 struct kobject kobj; /* 内嵌的kobject对象 */
3 struct module *owner; /* 所属模块*/
4 struct file_operations *ops; /* 文件操作结构体*/
5 struct list_head list;
6 dev_t dev; /* 设备号*/
7 unsigned int count;
8}
cdev_init() 函数用于初始化cdev的成员, 并建立cdev和file_operations之间的连接
void cdev_init(struct cdev *cdev, struct file_operations *fops)
cdev_alloc( ) 函数用于动态申请一个cdev内存
6.1.3 file_operations结构体
file_operations结构体中的成员函数是字符设备驱动程序设计的主体内容, 这些函数实际会在应用程序
进行Linux的open() 、 write() 、 read() 、 close() 等系统调用时最终被内核调用。
mmap( ) 函数将设备内存映射到进程的虚拟地址空间中, 如果设备驱动未实现此函数, 用户进行
mmap( ) 系统调用时将获得-ENODEV返回值。 这个函数对于帧缓冲等设备特别有意义, 帧缓冲被映射到
用户空间后, 应用程序可以直接访问它而无须在内核和应用间进行内存复制。 它与用户空间应用程序中的
void*mmap( void*addr, size_t length, int prot, int flags, int fd, off_t offset) 函数对应
1/* 设备结构体
2struct xxx_dev_t {
3 struct cdev cdev;
4 ...
5} xxx_dev;
6/* 设备驱动模块加载函数
7static int _ _init xxx_init(void)
8{
9 ...
10 cdev_init(&xxx_dev.cdev, &xxx_fops); /* 初始化cdev */
11 xxx_dev.cdev.owner = THIS_MODULE;
12 /* 获取字符设备号*/
13 if (xxx_major) {
14 register_chrdev_region(xxx_dev_no, 1, DEV_NAME);
15 } else {
16 alloc_chrdev_region(&xxx_dev_no, 0, 1, DEV_NAME);
17 }
18
19 ret = cdev_add(&xxx_dev.cdev, xxx_dev_no, 1); /* 注册设备*/
20 ...
21}
22/* 设备驱动模块卸载函数*/
23static void _ _exit xxx_exit(void)
24{
25 unregister_chrdev_region(xxx_dev_no, 1); /* 释放占用的设备号*/
26 cdev_del(&xxx_dev.cdev); /* 注销设备*/
27 ...
28}
1 /* 读设备*/
2 ssize_t xxx_read(struct file *filp, char __user *buf, size_t count,
3 loff_t*f_pos)
4 {
5 ...
6 copy_to_user(buf, ..., ...);
7 ...
8 }
9 /* 写设备*/
10 ssize_t xxx_write(struct file *filp, const char __user *buf, size_t count,
11 loff_t *f_pos)
12 {
13 ...
14 copy_from_user(..., buf, ...);
15 ...
16 }
17 /* ioctl函数 */
18 long xxx_ioctl(struct file *filp, unsigned int cmd,
19 unsigned long arg)
20 {
21 ...
22 switch (cmd) {
23 case XXX_CMD1:
24 ...
25 break;
26 case XXX_CMD2:
27 ...
28 break;
29 default:
30 /* 不能支持的命令 */
31 return - ENOTTY;
32 }
33 return 0;
34 }
内核空间和用户空间内存复制copy_from_user()、copy_to_user()
unsigned long copy_from_user(void *to, const void _ _user *from, unsigned long count);
unsigned long copy_to_user(void _ _user *to, const void *from, unsigned long count);
如果要复制的内存是简单类型, 如char、 int、 long等, 则可以使用简单的put_user() 和
get_user()
int val; /* 内核空间整型变量
...
get_user(val, (int *) arg); /* 用户→内核, arg是用户空间的地址 */
...
put_user(val, (int *) arg); /* 内核→用户, arg是用户空间的地址 */

#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#define GLOBALMEM_SIZE 0x1000
#define MEM_CLEAR 0x1
#define GLOBALMEM_MAJOR 230
static int globalmem_major = GLOBALMEM_MAJOR;
module_param(globalmem_major, int, S_IRUGO);
struct globalmem_dev {
struct cdev cdev;
unsigned char mem[GLOBALMEM_SIZE];
};
struct globalmem_dev *globalmem_devp;
static int globalmem_open(struct inode *inode, struct file *filp)
{
filp->private_data = globalmem_devp;
return 0;
}
static int globalmem_release(struct inode *inode, struct file *filp)
{
return 0;
}
static long globalmem_ioctl(struct file *filp, unsigned int cmd,
unsigned long arg)
{
struct globalmem_dev *dev = filp->private_data;
switch (cmd) {
case MEM_CLEAR:
memset(dev->mem, 0, GLOBALMEM_SIZE);
printk(KERN_INFO "globalmem is set to zero\n");
break;
default:
return -EINVAL;
}
return 0;
}
static ssize_t globalmem_read(struct file *filp, char __user * buf, size_t size,
loff_t * ppos)
{
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
struct globalmem_dev *dev = filp->private_data;
if (p >= GLOBALMEM_SIZE)
return 0;
if (count > GLOBALMEM_SIZE - p)
count = GLOBALMEM_SIZE - p;
if (copy_to_user(buf, dev->mem + p, count)) {
ret = -EFAULT;
} else {
*ppos += count;
ret = count;
printk(KERN_INFO "read %u bytes(s) from %lu\n", count, p);
}
return ret;
}
static ssize_t globalmem_write(struct file *filp, const char __user * buf,
size_t size, loff_t * ppos)
{
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
struct globalmem_dev *dev = filp->private_data;
if (p >= GLOBALMEM_SIZE)
return 0;
if (count > GLOBALMEM_SIZE - p)
count = GLOBALMEM_SIZE - p;
if (copy_from_user(dev->mem + p, buf, count))
ret = -EFAULT;
else {
*ppos += count;
ret = count;
printk(KERN_INFO "written %u bytes(s) from %lu\n", count, p);
}
return ret;
}
static loff_t globalmem_llseek(struct file *filp, loff_t offset, int orig)
{
loff_t ret = 0;
switch (orig) {
case 0:
if (offset < 0) {
ret = -EINVAL;
break;
}
if ((unsigned int)offset > GLOBALMEM_SIZE) {
ret = -EINVAL;
break;
}
filp->f_pos = (unsigned int)offset;
ret = filp->f_pos;
break;
case 1:
if ((filp->f_pos + offset) > GLOBALMEM_SIZE) {
ret = -EINVAL;
break;
}
if ((filp->f_pos + offset) < 0) {
ret = -EINVAL;
break;
}
filp->f_pos += offset;
ret = filp->f_pos;
break;
default:
ret = -EINVAL;
break;
}
return ret;
}
static const struct file_operations globalmem_fops = {
.owner = THIS_MODULE,
.llseek = globalmem_llseek,
.read = globalmem_read,
.write = globalmem_write,
.unlocked_ioctl = globalmem_ioctl,
.open = globalmem_open,
.release = globalmem_release,
};
static void globalmem_setup_cdev(struct globalmem_dev *dev, int index)
{
int err, devno = MKDEV(globalmem_major, index);
cdev_init(&dev->cdev, &globalmem_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalmem%d", err, index);
}
static int __init globalmem_init(void)
{
int ret;
dev_t devno = MKDEV(globalmem_major, 0);
if (globalmem_major)
ret = register_chrdev_region(devno, 1, "globalmem");
else {
ret = alloc_chrdev_region(&devno, 0, 1, "globalmem");
globalmem_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalmem_devp = kzalloc(sizeof(struct globalmem_dev), GFP_KERNEL);
if (!globalmem_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
globalmem_setup_cdev(globalmem_devp, 0);
return 0;
fail_malloc:
unregister_chrdev_region(devno, 1);
return ret;
}
module_init(globalmem_init);
static void __exit globalmem_exit(void)
{
cdev_del(&globalmem_devp->cdev);
kfree(globalmem_devp);
unregister_chrdev_region(MKDEV(globalmem_major, 0), 1);
}
module_exit(globalmem_exit);
MODULE_AUTHOR("Barry Song <[email protected]>");
MODULE_LICENSE("GPL v2");mknod /dev/globalmem c 230 0
创建“/dev/globalmem”设备节点, 并通过“echo'hello world'>/dev/globalmem”命令和“cat/dev/globalmem”命令分
别验证设备的写和读, 结果证明“hello world”字符串被正确地写入了globalmem字符设备:
第7章 Linux设备驱动中的并发控制
7.1 并发与竞态
并发(Concurrency) 指的是多个执行单元同时、 并行被执行, 而并发的执行单元对共享资源(硬件资
源和软件上的全局变量、 静态变量等) 的访问则很容易导致竞态(Race Conditions) 。
7.2 编译乱序和执行乱序
#define barrier() __asm__ __volatile__("": : :"memory")
7.3 中断屏蔽
在单CPU范围内避免竞态的一种简单而有效的方法是在进入临界区之前屏蔽系统的中断, 但是在驱动
编程中不值得推荐, 驱动通常需要考虑跨平台特点而不假定自己在单核上运行。 CPU一般都具备屏蔽中断
和打开中断的功能, 这项功能可以保证正在执行的内核执行路径不被中断处理程序所抢占, 防止某些竞态
条件的发生。
local_irq_disable() /* 屏蔽中断 */
. . .
critical section /* 临界区*/
. . .
local_irq_enable() /* 开中断*/
7.4 原子操作
原子操作可以保证对一个整型数据的修改是排他性的。 Linux内核提供了一系列函数来实现内核中的
原子操作, 这些函数又分为两类, 分别针对位和整型变量进行原子操作。 位和整型变量的原子操作都依赖
于底层CPU的原子操作, 因此所有这些函数都与CPU架构密切相关。 对于ARM处理器而言, 底层使用
LDREX和STREX指令, 比如atomic_inc() 底层的实现会调用到atomic_add()
7.5 自旋锁
/* 定义一个自旋锁*/
spinlock_t lock;
spin_lock_init(&lock);
spin_lock (&lock) ; /* 获取自旋锁, 保护临界区 */
. . ./* 临界区*/
spin_unlock (&lock) ; /* 解锁*/
1) 自旋锁实际上是忙等锁, 当锁不可用时, CPU一直循环执行“测试并设置”该锁直到可用而取得该
锁, CPU在等待自旋锁时不做任何有用的工作, 仅仅是等待。 因此, 只有在占用锁的时间极短的情况下,
使用自旋锁才是合理的。 当临界区很大, 或有共享设备的时候, 需要较长时间占用锁, 使用自旋锁会降低
系统的性能。
2) 自旋锁可能导致系统死锁。 引发这个问题最常见的情况是递归使用一个自旋锁, 即如果一个已经
拥有某个自旋锁的CPU想第二次获得这个自旋锁, 则该CPU将死锁。
3) 在自旋锁锁定期间不能调用可能引起进程调度的函数。 如果进程获得自旋锁之后再阻塞, 如调用
copy_from_user( ) 、 copy_to_user( ) 、 kmalloc( ) 和msleep( ) 等函数, 则可能导致内核的崩溃。
4) 在单核情况下编程的时候, 也应该认为自己的CPU是多核的, 驱动特别强调跨平台的概念。
7.6 信号量
7.7 互斥体
struct mutex my_mutex; /* 定义mutex */
mutex_init(&my_mutex); /* 初始化mutex */
mutex_lock(&my_mutex); /* 获取mutex */
... /* 临界资源*/
mutex_unlock(&my_mutex); /* 释放mutex */
自旋锁和互斥体选用的3项原则。
1) 当锁不能被获取到时, 使用互斥体的开销是进程上下文切换时间, 使用自旋锁的开销是等待获取
自旋锁(由临界区执行时间决定) 。 若临界区比较小, 宜使用自旋锁, 若临界区很大, 应使用互斥体。
2) 互斥体所保护的临界区可包含可能引起阻塞的代码, 而自旋锁则绝对要避免用来保护包含这样代
码的临界区。 因为阻塞意味着要进行进程的切换, 如果进程被切换出去后, 另一个进程企图获取本自旋
锁, 死锁就会发生。
3) 互斥体存在于进程上下文, 因此, 如果被保护的共享资源需要在中断或软中断情况下使用, 则在
互斥体和自旋锁之间只能选择自旋锁。 当然, 如果一定要使用互斥体, 则只能通过mutex_trylock() 方式
进行, 不能获取就立即返回以避免阻塞
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/cdev.h>
#include <linux/slab.h>
#include <linux/uaccess.h>
#define GLOBALMEM_SIZE 0x1000
#define MEM_CLEAR 0x1
#define GLOBALMEM_MAJOR 230
static int globalmem_major = GLOBALMEM_MAJOR;
module_param(globalmem_major, int, S_IRUGO);
struct globalmem_dev {
struct cdev cdev;
unsigned char mem[GLOBALMEM_SIZE];
struct mutex mutex;
};
struct globalmem_dev *globalmem_devp;
static int globalmem_open(struct inode *inode, struct file *filp)
{
filp->private_data = globalmem_devp;
return 0;
}
int globalmem_release(struct inode *inode, struct file *filp)
{
return 0;
}
static long globalmem_ioctl(struct file *filp, unsigned int cmd,
unsigned long arg)
{
struct globalmem_dev *dev = filp->private_data;
switch (cmd) {
case MEM_CLEAR:
mutex_lock(&dev->mutex);
memset(dev->mem, 0, GLOBALMEM_SIZE);
mutex_unlock(&dev->mutex);
printk(KERN_INFO "globalmem is set to zero\n");
break;
default:
return -EINVAL;
}
return 0;
}
static ssize_t globalmem_read(struct file *filp, char __user * buf, size_t size,
loff_t * ppos)
{
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
struct globalmem_dev *dev = filp->private_data;
if (p >= GLOBALMEM_SIZE)
return 0;
if (count > GLOBALMEM_SIZE - p)
count = GLOBALMEM_SIZE - p;
mutex_lock(&dev->mutex);
if (copy_to_user(buf, dev->mem + p, count)) {
ret = -EFAULT;
} else {
*ppos += count;
ret = count;
printk(KERN_INFO "read %u bytes(s) from %lu\n", count, p);
}
mutex_unlock(&dev->mutex);
return ret;
}
static ssize_t globalmem_write(struct file *filp, const char __user * buf,
size_t size, loff_t * ppos)
{
unsigned long p = *ppos;
unsigned int count = size;
int ret = 0;
struct globalmem_dev *dev = filp->private_data;
if (p >= GLOBALMEM_SIZE)
return 0;
if (count > GLOBALMEM_SIZE - p)
count = GLOBALMEM_SIZE - p;
mutex_lock(&dev->mutex);
if (copy_from_user(dev->mem + p, buf, count))
ret = -EFAULT;
else {
*ppos += count;
ret = count;
printk(KERN_INFO "written %u bytes(s) from %lu\n", count, p);
}
mutex_unlock(&dev->mutex);
return ret;
}
static loff_t globalmem_llseek(struct file *filp, loff_t offset, int orig)
{
loff_t ret = 0;
switch (orig) {
case 0:
if (offset < 0) {
ret = -EINVAL;
break;
}
if ((unsigned int)offset > GLOBALMEM_SIZE) {
ret = -EINVAL;
break;
}
filp->f_pos = (unsigned int)offset;
ret = filp->f_pos;
break;
case 1:
if ((filp->f_pos + offset) > GLOBALMEM_SIZE) {
ret = -EINVAL;
break;
}
if ((filp->f_pos + offset) < 0) {
ret = -EINVAL;
break;
}
filp->f_pos += offset;
ret = filp->f_pos;
break;
default:
ret = - EINVAL;
break;
}
return ret;
}
static const struct file_operations globalmem_fops = {
.owner = THIS_MODULE,
.llseek = globalmem_llseek,
.read = globalmem_read,
.write = globalmem_write,
.unlocked_ioctl = globalmem_ioctl,
.open = globalmem_open,
.release = globalmem_release,
};
static void globalmem_setup_cdev(struct globalmem_dev *dev, int index)
{
int err, devno = MKDEV(globalmem_major, index);
cdev_init(&dev->cdev, &globalmem_fops);
dev->cdev.owner = THIS_MODULE;
err = cdev_add(&dev->cdev, devno, 1);
if (err)
printk(KERN_NOTICE "Error %d adding globalmem%d", err, index);
}
static int __init globalmem_init(void)
{
int ret;
dev_t devno = MKDEV(globalmem_major, 0);
if (globalmem_major)
ret = register_chrdev_region(devno, 1, "globalmem");
else {
ret = alloc_chrdev_region(&devno, 0, 1, "globalmem");
globalmem_major = MAJOR(devno);
}
if (ret < 0)
return ret;
globalmem_devp = kzalloc(sizeof(struct globalmem_dev), GFP_KERNEL);
if (!globalmem_devp) {
ret = -ENOMEM;
goto fail_malloc;
}
globalmem_setup_cdev(globalmem_devp, 0);
mutex_init(&globalmem_devp->mutex);
return 0;
fail_malloc:
unregister_chrdev_region(devno, 1);
return ret;
}
module_init(globalmem_init);
static void __exit globalmem_exit(void)
{
cdev_del(&globalmem_devp->cdev);
kfree(globalmem_devp);
unregister_chrdev_region(MKDEV(globalmem_major, 0), 1);
}
module_exit(globalmem_exit);
MODULE_AUTHOR("Barry Song <[email protected]>");
MODULE_LICENSE("GPL v2");第8章 Linux设备驱动中的阻塞与非阻塞I/O
8.1 阻塞与非阻塞I/O
阻塞操作是指在执行设备操作时, 若不能获得资源, 则挂起进程直到满足可操作的条件后再进行操
作。 被挂起的进程进入睡眠状态, 被从调度器的运行队列移走, 直到等待的条件被满足。 而非阻塞操作的
进程在不能进行设备操作时, 并不挂起, 它要么放弃, 要么不停地查询, 直至可以进行操作为止。
char buf;
fd = open("/dev/ttyS1", O_RDWR);
...
res = read(fd,&buf,1); /* 当串口上有输入时才返回 */
if(res==1)
printf("%c\n", buf);
char buf;
fd = open("/dev/ttyS1", O_RDWR| O_NONBLOCK);
...
while(read(fd,&buf,1)!=1)
continue; /* 串口上无输入也返回, 因此要循环尝试读取串口 */
printf("%c\n", buf);
8.2 轮询操作
当多路复用的文件数量庞大、 I/O流量频繁的时候, 一般不太适合使用select() 和poll() , 此种情
况下, select() 和poll() 的性能表现较差, 我们宜使用epoll。 epoll的最大好处是不会随着fd的数目增长
而降低效率, select() 则会随着fd的数量增大性能下降明显
int epoll_create(int size);
创建一个epoll的句柄, size用来告诉内核要监听多少个fd。 需要注意的是, 当创建好epoll句柄后, 它
本身也会占用一个fd值, 所以在使用完epoll后, 必须调用close() 关闭。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
告诉内核要监听什么类型的事件。 第1个参数是epoll_create() 的返回值, 第2个参数表示动作, 包
含:
EPOLL_CTL_ADD: 注册新的fd到epfd中。
EPOLL_CTL_MOD: 修改已经注册的fd的监听事件。
EPOLL_CTL_DEL: 从epfd中删除一个fd。
第3个参数是需要监听的fd, 第4个参数是告诉内核需要监听的事件类型, struct epoll_event结构如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的“或”:EPOLLIN: 表示对应的文件描述符可以读。
EPOLLOUT: 表示对应的文件描述符可以写。
EPOLLPRI: 表示对应的文件描述符有紧急的数据可读( 这里应该表示的是有socket带外数据到
来) 。
EPOLLERR: 表示对应的文件描述符发生错误。
EPOLLHUP: 表示对应的文件描述符被挂断。
EPOLLET: 将epoll设为边缘触发( Edge Triggered) 模式, 这是相对于水平触发( Level Triggered) 来
说的。 LT( Level Triggered) 是缺省的工作方式, 在LT情况下, 内核告诉用户一个fd是否就绪了, 之后用
户可以对这个就绪的fd进行I/O操作。 但是如果用户不进行任何操作, 该事件并不会丢失, 而ET( EdgeTriggered) 是高速工作方式, 在这种模式下, 当fd从未就绪变为就绪时, 内核通过epoll告诉用户, 然后它
会假设用户知道fd已经就绪, 并且不会再为那个fd发送更多的就绪通知。
EPOLLONESHOT: 意味着一次性监听, 当监听完这次事件之后, 如果还需要继续监听这个fd的话,
需要再次把这个fd加入到epoll队列里。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
等待事件的产生, 其中events参数是输出参数, 用来从内核得到事件的集合, maxevents告诉内核本次
最多收多少事件, maxevents的值不能大于创建epoll_create( ) 时的size, 参数timeout是超时时间( 以毫秒
为单位, 0意味着立即返回, -1意味着永久等待) 。 该函数的返回值是需要处理的事件数目, 如返回0, 则
表示已超时。
一般来说, 当涉及的fd数量较少的时候, 使用select是合适的; 如果涉及的fd很多, 如在大规模并发的服务器中侦听许多socket
的时候, 则不太适合选用select, 而适合选用epoll。
第9章 Linux设备驱动中的异步通知与异步I/O
在设备驱动中使用异步通知可以使得在进行对设备的访问时, 由驱动主动通知应用程序进行访问。 这
样, 使用非阻塞I/O的应用程序无须轮询设备是否可访问, 而阻塞访问也可以被类似“中断”的异步通知所
取代。
除了异步通知以外, 应用还可以在发起I/O请求后, 立即返回。 之后, 再查询I/O完成情况, 或者I/O完
成后被调回。 这个过程叫作异步I/O。
异步通知的意思是: 一旦设备就绪, 则主动通知应用程序, 这样应用程序根本就不需要查询设备状
态, 这一点非常类似于硬件上“中断”的概念, 比较准确的称谓是“信号驱动的异步I/O”。 信号是在软件层
次上对中断机制的一种模拟, 在原理上, 一个进程收到一个信号与处理器收到一个中断请求可以说是一样
的。 信号是异步的, 一个进程不必通过任何操作来等待信号的到达, 事实上, 进程也不知道信号到底什么
时候到达。
阻塞I/O意味着一直等待设备可访问后再访问, 非阻塞I/O中使用poll() 意味着查询设备是否可访
问, 而异步通知则意味着设备通知用户自身可访问, 之后用户再进行I/O处理。 由此可见, 这几种I/O方式
可以相互补充
第10章 中断与时钟
10.1 中断与定时器
中断是指CPU在执行程序的过程中, 出现了某些突发事件急待处理, CPU必须暂停当前程序的执
行, 转去处理突发事件, 处理完毕后又返回原程序被中断的位置继续执行。
内部中断的中断源来自CPU内部(软件中断指
令、 溢出、 除法错误等, 例如, 操作系统从用户态切换到内核态需借助CPU内部的软件中断) ,外部中断
的中断源来自CPU外部, 由外设提出请求
中断是否可以屏蔽, 中断可分为可屏蔽中断与不可屏蔽中断(NMI) , 可屏蔽中断可以通过设置
中断控制器寄存器等方法被屏蔽, 屏蔽后, 该中断不再得到响应, 而不可屏蔽中断不能被屏蔽。
根据中断入口跳转方法的不同, 中断可分为向量中断和非向量中断。 采用向量中断的CPU通常为不同
的中断分配不同的中断号, 当检测到某中断号的中断到来后, 就自动跳转到与该中断号对应的地址执行。
不同中断号的中断有不同的入口地址。 非向量中断的多个中断共享一个入口地址, 进入该入口地址后, 再
通过软件判断中断标志来识别具体是哪个中断。 也就是说, 向量中断由硬件提供中断服务程序入口地址,
非向量中断由软件提供中断服务程序入口地址。
10.2 Linux中断处理程序架构
a.中断执行时间尽量短
b.中断处理需完成的工作尽量大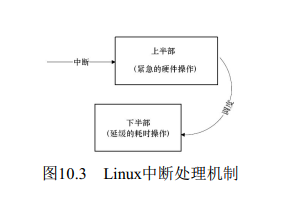
10.3 Linux中断编程
10.3.1 申请和释放中断
在Linux设备驱动中, 使用中断的设备需要申请和释放对应的中断, 并分别使用内核提供的
request_irq() 和free_irq() 函数。
1.申请irq
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long flags,
const char *name, void *dev);
irq是要申请的硬件中断号。
handler是向系统登记的中断处理函数(顶半部) , 是一个回调函数, 中断发生时, 系统调用这个函
数, dev参数将被传递给它。
irqflags是中断处理的属性, 可以指定中断的触发方式以及处理方式。 在触发方式方面, 可以是
IRQF_TRIGGER_RISING、 IRQF_TRIGGER_FALLING、 IRQF_TRIGGER_HIGH、 IRQF_TRIGGER_LOW
等。 在处理方式方面, 若设置了IRQF_SHARED, 则表示多个设备共享中断, dev是要传递给中断服务程
序的私有数据, 一般设置为这个设备的设备结构体或者NULL。
request_irq() 返回0表示成功, 返回-EINVAL表示中断号无效或处理函数指针为NULL, 返回-
EBUSY表示中断已经被占用且不能共享。
2.释放irq
与request_irq() 相对应的函数为free_irq() , free_irq() 的原型为:
void free_irq(unsigned int irq,void *dev_id);
free_irq() 中参数的定义与request_irq() 相同。
10.3.2 使能和屏蔽中断
下列3个函数用于屏蔽一个中断源:
void disable_irq(int irq);
void disable_irq_nosync(int irq);
void enable_irq(int irq);
10.3.3 底半部机制
Linux实现底半部的机制主要有tasklet、 工作队列、 软中断和线程化irq。
/* 定义tasklet和底半部函数并将它们关联 */
void xxx_do_tasklet(unsigned long);
DECLARE_TASKLET(xxx_tasklet, xxx_do_tasklet, 0);
/* 中断处理底半部 */
void xxx_do_tasklet(unsigned long)
{
...
}
/* 中断处理顶半部 */
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
tasklet_schedule(&xxx_tasklet);
...
}
/* 设备驱动模块加载函数 */
int __init xxx_init(void)
{
...
/* 申请中断 */
result = request_irq(xxx_irq, xxx_interrupt,
0, "xxx", NULL);
...
return IRQ_HANDLED;
}
/* 设备驱动模块卸载函数 */
void __exit xxx_exit(void)
{
...
/* 释放中断 */
free_irq(xxx_irq, xxx_interrupt);36 ...
}
/* 定义工作队列和关联函数 */
struct work_struct xxx_wq;
void xxx_do_work(struct work_struct *work);
/* 中断处理底半部 */
void xxx_do_work(struct work_struct *work)
{
...
}
/*中断处理顶半部*/
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
schedule_work(&xxx_wq);
...
return IRQ_HANDLED;
}
/* 设备驱动模块加载函数 */
int xxx_init(void)
{
...
/* 申请中断 */
result = request_irq(xxx_irq, xxx_interrupt,
0, "xxx", NULL);
...
/* 初始化工作队列 */
INIT_WORK(&xxx_wq, xxx_do_work);
...31}
/* 设备驱动模块卸载函数 */
void xxx_exit(void)
{
36 ...
37 /* 释放中断 */
38 free_irq(xxx_irq, xxx_interrupt);
39 ...
40}工作队列的使用方法和tasklet非常相似, 但是工作队列的执行上下文是内核线程, 因此可以调度和睡
眠。
10.4 中断共享
代码清单10.8 共享中断编程模板
/* 中断处理顶半部 */
irqreturn_t xxx_interrupt(int irq, void *dev_id)
{
...
int status = read_int_status(); /* 获知中断源 */
if(!is_myint(dev_id,status)) /* 判断是否为本设备中断 */
return IRQ_NONE; /* 不是本设备中断, 立即返回 */
/* 是本设备中断, 进行处理 */
...
return IRQ_HANDLED; /* 返回IRQ_HANDLED表明中断已被处理 */
}
/* 设备驱动模块加载函数 */
int xxx_init(void)
{
...
/* 申请共享中断 */
result = request_irq(sh_irq, xxx_interrupt,
IRQF_SHARED, "xxx", xxx_dev);
...
}
/* 设备驱动模块卸载函数 */
void xxx_exit(void)
{27 ...
/* 释放中断 */
free_irq(xxx_irq, xxx_interrupt);
...
}10.5 内核定时器
软件意义上的定时器最终依赖硬件定时器来实现, 内核在时钟中断发生后检测各定时器是否到期, 到
期后的定时器处理函数将作为软中断在底半部执行。 实质上, 时钟中断处理程序会唤起TIMER_SOFTIRQ
软中断, 运行当前处理器上到期的所有定时器。
内核定时器使用模板
/* xxx设备结构体 */
struct xxx_dev {
struct cdev cdev;
...
timer_list xxx_timer; /* 设备要使用的定时器 */
};
/* xxx驱动中的某函数 */
xxx_func1(…)
{
struct xxx_dev *dev = filp->private_data;
...
/* 初始化定时器 */
init_timer(&dev->xxx_timer);
dev->xxx_timer.function = &xxx_do_timer;
dev->xxx_timer.data = (unsigned long)dev;
/* 设备结构体指针作为定时器处理函数参数 */
dev->xxx_timer.expires = jiffies + delay;
/* 添加(注册) 定时器 */
add_timer(&dev->xxx_timer);
...
}
/* xxx驱动中的某函数 */
xxx_func2(…)
{
...
/* 删除定时器 */
del_timer (&dev->xxx_timer);
...
}
/* 定时器处理函数 */
static void xxx_do_timer(unsigned long arg)
{
struct xxx_device *dev = (struct xxx_device *)(arg);
...
/* 调度定时器再执行 */
dev->xxx_timer.expires = jiffies + delay;
add_timer(&dev->xxx_timer);
...
}