✌ ShuffleSplit函数的使用方法
1、✌ 原理
用于将样本集合随机“打散”后划分为训练集、测试集(可理解为验证集,下同)
类似于交叉验证
2、✌ 函数形式
ShuffleSplit(n_splits=10, test_size=’default’, train_size=None, random_state=None)
3、✌ 重要参数
n_splits:
划分数据集的份数,类似于KFlod的折数,默认为10份
test_size:
测试集所占总样本的比例,如test_size=0.2即将划分后的数据集中20%作为测试集
random_state:
随机数种子,使每次划分的数据集不变
4、✌ 代码示例
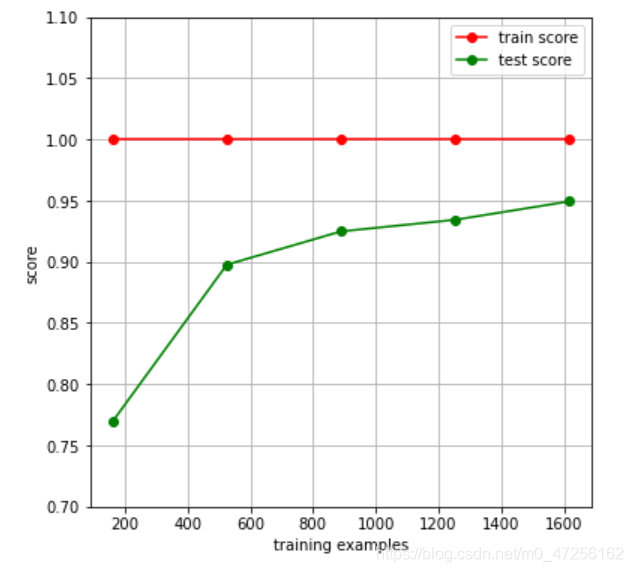
学习曲线就是通过画出不同训练集大小时训练集和交叉验证的准确率,可以看到模型在新数据上的表现,进而来判断模型是否方差偏高或偏差过高,以及增大训练集是否可以减小过拟合。
✌ 导库
from sklearn.datasets import load_digits # 导入手写数字集
from sklearn.model_selection import learning_curve # 导入学习曲线类
from sklearn.model_selection import learning_curve # 导入数据分割类
✌ 加载数据
fig,ax=plt.subplots(1,1,figsize=(6,6)) # 设置画布和子图
data=load_digits()
x,y=data.data,data.target # 加载特征矩阵和标签
✌ 画图
train_sizes,train_scores,test_scores=learning_curve(RandomForestClassifier(n_estimators=50),x,y,cv=ShuffleSplit(n_splits=50,test_size=0.2,random_state=0),n_jobs=4)
# 设置分类器为随机森林,x,y,cv为ShuffleSplit分割模式,cpu同时运算为4个
ax.set_ylim((0.7,1.1)) # 设置子图的纵坐标的范围为(0.7~1.1)
ax.set_xlabel("training examples") # 设置子图的x轴名称
ax.set_ylabel("score")
ax.grid() # 画出网图
ax.plot(train_sizes,np.mean(train_scores,axis=1),'o-',color='r',label='train score')
# 画训练集数据分数,横坐标为用作训练的样本数,纵坐标为不同折下的训练分数的均值
ax.plot(train_sizes,np.mean(test_scores,axis=1),'o-',color='g',label='test score')
ax.legend(loc='best') # 设置图例
plt.show()