原文参考链接:http://www.cnblogs.com/lianyingteng/p/7811126.html
sklearn_user_guide:https://download.csdn.net/download/jimi0123/10898941
传统的机器学习任务从开始到建模的一般流程是:获取数据 -> 数据预处理 -> 训练建模 -> 模型评估 -> 预测,分类。本文我们将依据传统机器学习的流程,看看在每一步流程中都有哪些常用的函数以及它们的用法是怎么样的。希望你看完这篇文章可以最为快速的开始你的学习任务。
1. 获取数据
1.1 导入sklearn数据集
sklearn中包含了大量的优质的数据集,在你学习机器学习的过程中,你可以通过使用这些数据集实现出不同的模型,从而提高你的动手实践能力,同时这个过程也可以加深你对理论知识的理解和把握。
要想使用sklearn中的数据集,必须导入datasets模块。
from sklearn import datasets
iris = datasets.load_iris() # 导入数据集
X = iris.data # 获得其特征向量
y = iris.target # 获得样本label
1.2 创建数据集
除了可以使用sklearn自带的数据集,还可以自己去创建训练样本,sklearn中的samples generator包含的大量创建样本数据的方法。我们拿分类问题的样本生成器个栗子。
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2, scale=1.0,
random_state=20)
1.3 导入已有数据集
导入自己下载或者收集的的数据集
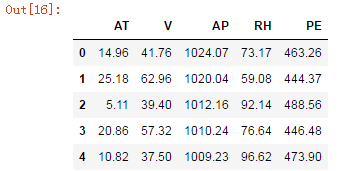
data = pd.read_csv("E:/py/jupyter/exercise/ccpp.csv") #读取数据
data.head() #测试数据,显示前5行,后5行用data.tail
2 数据预处理
2.1 数据归一化
为了使得训练数据的标准化规则与测试数据的标准化规则同步,preprocessing中提供了很多Scaler:
from sklearn import preprocessing
# 1. 基于mean和std的标准化
scaler = preprocessing.StandardScaler().fit(train_data)
scaler.transform(train_data)
scaler.transform(test_data)
# 2. 将每个特征值归一化到一个固定范围
scaler = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(train_data)
scaler.transform(train_data)
scaler.transform(test_data)
#feature_range: 定义归一化范围,注用()括起来
2.2 正则化(normalize)
当你想要计算两个样本的相似度时必不可少的一个操作,就是正则化。其思想是:首先求出样本的p-范数,然后该样本的所有元素都要除以该范数,这样最终使得每个样本的范数都为1。
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
2.3 one-hot编码
one-hot编码是一种对离散特征值的编码方式,在LR模型中常用到,用于给线性模型增加非线性能力。
data = [[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]
encoder = preprocessing.OneHotEncoder().fit(data)
enc.transform(data).toarray()
3. 数据集拆分
在得到训练数据集时,通常我们经常会把训练数据集进一步拆分成训练集和验证集,这样有助于我们模型参数的选取,一般选取70%的数据作为训练集。
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,Y,test_size = 0.3,random_state=1)
4. 定义模型
在这一步我们首先要分析自己数据的类型,搞清出你要用什么模型来做,然后我们就可以在sklearn中定义模型了。sklearn为所有模型提供了非常相似的接口,这样使得我们可以更加快速的熟悉所有模型的用法。在这之前我们先来看看模型的常用属性和功能:
# 拟合模型
model.fit(X_train, y_train)
# 模型预测
model.predict(X_test)
# 获得这个模型的参数
model.get_params()
# 为模型进行打分
model.score(data_X, data_y) # 线性回归:R square; 分类问题: acc
# 定义线性回归模型
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True, normalize=False,
copy_X=True, n_jobs=1)
# 定义逻辑回归模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(penalty=’l2’, dual=False, tol=0.0001, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver=’liblinear’, max_iter=100, multi_class=’ovr’,
verbose=0, warm_start=False, n_jobs=1)
# 定义贝叶斯模型
from sklearn import naive_bayes
model = naive_bayes.GaussianNB() # 高斯贝叶斯
model = naive_bayes.MultinomialNB(alpha=1.0, fit_prior=True, class_prior=None)
model = naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)
KNN、SVM、决策树、神经网络......
参考user_guide
5. 模型评估与选择
对于分类器,或者说分类算法,评价指标主要有accuracy, [precision,recall,宏平均和微平均,F-score,pr曲线],ROC-AUC曲线,gini系数。
对于回归分析,主要有mse和r2/拟合优度。
关于评价指标的具体含义可参考:
https://blog.csdn.net/pipisorry/article/details/52574156
https://www.cnblogs.com/pinard/p/5993450.html
6. 保存模型
6.1 保存为pickle文件
import pickle
# 保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
# 读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)
6.2 sklearn自带方法joblib
from sklearn.externals import joblib
# 保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')
7. 举个小栗子
不必纠结所用数据的具体含义,完成一个简单的线性回归。
#导入包
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn import datasets, linear_model
#1. 读取数据
data = pd.read_csv("E:/py/jupyter/exercise/ccpp.csv") #读取数据
data.head() #测试数据,显示前5行,后5行用data.tail
#2. 准备运行的数据
X = data[['AT','V','AP','RH']]
Y = data[['PE']]
#3. 划分训练集和测试集
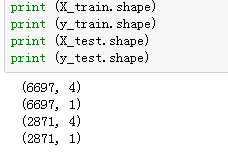
from sklearn.cross_validation import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,Y,test_size = 0.3,random_state=1)
#4.运行sklearn线性模型
from sklearn.linear_model import LinearRegression
linreg = LinearRegression()
linreg.fit(X_train,y_train)
#拟合完毕后,看看模型系数结果:
print (linreg.intercept_) #截距
print (linreg.coef_) #4个系数
[458.39877507]
[[-1.97137593 -0.23772975 0.05834485 -0.15731748]]
#5. 模型评价
#我们需要评估我们的模型的好坏程度,对于线性回归来说,
#我们一般用均方差(Mean Squared Error, MSE)或者均方根差(Root Mean Squared Error, RMSE)在测试集上的表现来评价模型的
#好坏。
y_pred = linreg.predict(X_test)
from sklearn import metrics
print("MSE:",metrics.mean_squared_error(y_test,y_pred))
print("RMSE:",np.sqrt(metrics.mean_squared_error(y_test,y_pred)))
MSE: 20.77747810688439
RMSE: 4.558231905781494
#得到了MSE或者RMSE,如果我们用其他方法得到了不同的系数,需要选择模型时,就用MSE小的时候对应的参数。
#6. 交叉验证
#我们可以通过交叉验证来持续优化模型,代码如下,我们采用10折交叉验证,即cross_val_predict中的cv参数为10:
X = data[['AT','V','AP','RH']]
Y = data[['PE']]
from sklearn.model_selection import cross_val_predict
predicted = cross_val_predict(linreg,X,Y,cv=10)
print("MSE:",metrics.mean_squared_error(Y,predicted))
print("RMSE:",np.sqrt(metrics.mean_squared_error(Y,predicted)))
MSE: 20.79367250985753
RMSE: 4.560007950635342
#可以看出,采用交叉验证模型的MSE比上述的大, 主要原因是我们这里是对所有折的样本做测试集对应的预测值的MSE,而上述只
#使用了0.3的数据集做了MSE。两者的先决条件并不同。
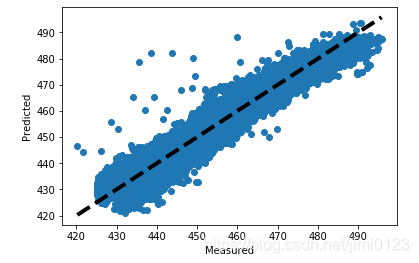
#7.观察结果
#这里画图真实值和预测值的变化关系,离中间的直线y=x直接越近的点代表预测损失越低
fig,ax = plt.subplots()
ax.scatter(Y,predicted) #散点图
ax.plot([Y.min(),Y.max()], [Y.min(), Y.max()], 'k--', lw=4) #虚线
ax.set_xlabel('Measured')
ax.set_ylabel('Predicted')
plt.show()