0、序
0.1、MTCNN是啥?
MTCNN是一个深度卷积多任务的框架。这个框架利用了检测和对准之间固有的关系来增强其性能。在预测人脸和脸部标记点时,通过3个级联的CNN网络完成从粗到精的处理。在使用该网络之前,需要先进行图片的剪裁、缩放将图片缩放到不同的尺寸,形成图像金字塔,然后将不同尺寸的图片放到以下的三个子网络去进行训练。
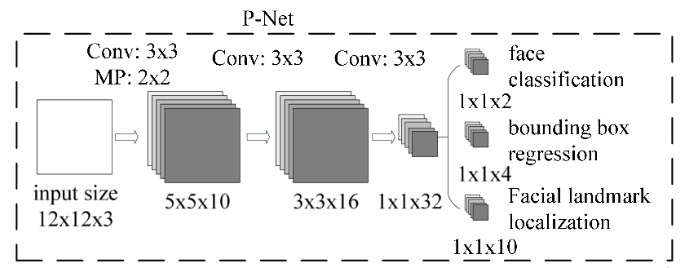
第一阶段使用P-Net:
1)阶段一:使用P-Net网络的时候,输入12×12×3的RGB图像,通过10个3×3的卷积核,和2×2的Max Pooling池化操作,形成10个5×5的特征图;
2)阶段二:通过16个3×3×10的卷积核,生成16个3×3的特征图;
3)阶段三:通过32个3×3×16的卷积核将输入的16个3×3的特征图处理,生成32个1×1的特征图。
输出:
1)一个1×1×2的二分类得分,表示不是人脸的概率和是人脸的概率;
2)4个bounding box的坐标偏移量;
3)5个人脸特征点的坐标。
第二阶段使用R-Net:
对P-Net生成的bouding box进行进一步的优化调整。输入换成了24×24×3的RGB图片,并加入全链接层。

第三阶段使用O-Net:
输出最终的人脸框和特征点位置,和第二阶段类似,不过这里输出的5个特征点的位置。

MTCNN论文传送门:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
MTCNN在github项目源码:https://github.com/kpzhang93/MTCNN_face_detection_alignment
关于FaceNet的相关介绍就不再赘述,详细可见我上一篇博文Jetson nano实战系列:基于dlib+FaceNet实现人脸识别。
1、基本实现
该demo基于MTCNN和FaceNet实现人脸识别,从功能上可分为两大部分即:人脸检测和人脸识别。人脸检测部分使用MTCNN是一个深度卷积多任务的框架,根据使用MTCNN返回的人脸区域框图作为后半部分FaceNet人脸识别的输入,结合上述这两部分实现实时的人脸识别。
2、Coding

2.1、新建FaceNet model类,编写相关构造函数,推理函数,析构函数
import tensorflow.compat.v1 as tf
from scipy import misc
import facenet
import numpy as np
#facenet network class
class FaceNet_Model():
def __init__(self, model_file):
tf.Graph().as_default()
self.sess = tf.Session()
with self.sess.as_default():
facenet.load_model('20180402-114759.pb')
self.image_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
self.phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
self.embeddings_op = tf.get_default_graph().get_tensor_by_name("embeddings:0")
def get_descriptor(self, image):
image = misc.imresize(image, (160,160), interp = "bilinear")
image = facenet.prewhiten(image)
images = np.stack([image])
feed_dict = {
self.image_placeholder:images, self.phase_train_placeholder:False}
emb = self.sess.run(self.embeddings_op, feed_dict = feed_dict)
return emb[0,:]
def __del__(self):
self.sess.close()
def g_FaceNetModel(model_file):
return FaceNet_Model(model_file)
2.2、新建MTCNN_model类,编写相关构造函数,以及功能函数
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from scipy import misc
import tensorflow.compat.v1 as tf
import numpy as np
import sys
import os
import copy
import argparse
import facenet
import align.detect_face
class MTCNN_Model():
def __init__(self):
# Setup P-Net R-Net O-Net
self.minsize = 20 # minimum size of face
self.threshold = [ 0.6, 0.7, 0.7 ] # three steps's threshold
self.factor = 0.709 # scale factor
self.gpu_memory_fraction = 0.7
self.face_crop_size = 160
self.face_crop_margin = 32
self.pnet, self.rnet, self.onet = self.__mtcnn_setup() #mtcnn setup
def __mtcnn_setup(self):
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=self.gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
return align.detect_face.create_mtcnn(sess, None)
# func face_detect for face catch and alignment
def face_detector(self, image):
bounding_boxes, _ = align.detect_face.detect_face(image, self.minsize,
self.pnet, self.rnet, self.onet,
self.threshold, self.factor)
return bounding_boxes
#face alignment
def face_aligner(self, image, bb):
bounding_box = np.zeros(4, dtype=np.int32)
img_size = np.asarray(image.shape)[0:2]
bounding_box[0] = np.maximum(bb[0] - self.face_crop_margin / 2, 0)
bounding_box[1] = np.maximum(bb[1] - self.face_crop_margin / 2, 0)
bounding_box[2] = np.minimum(bb[2] + self.face_crop_margin / 2, img_size[1])
bounding_box[3] = np.minimum(bb[3] + self.face_crop_margin / 2, img_size[0])
cropped = image[bounding_box[1]:bounding_box[3], bounding_box[0]:bounding_box[2], :]
face_aligned = misc.imresize(cropped, (self.face_crop_size, self.face_crop_size), interp='bilinear')
return face_aligned
def __del__(self):
self.sess.close()
def g_mtcnn_model():
return MTCNN_Model()
2.3、人脸数据注册并保存本地
人脸特征向量的获取还是借助dlib获取人脸区域图像,将其作为输入至FaceNet中获取人脸的特征向量表示。
import dlib
import cv2
import os
import facenet_model
import pickle
font = cv2.FONT_HERSHEY_SIMPLEX
detector = dlib.get_frontal_face_detector()
face_net = facenet_model.g_FaceNetModel('20180402-114759.pb')
imagePATH = '/home/colin/works/face_dataset/processed/'
def create_known(path):
global font
person_names = []
face_features = []
print("creating known face lib...")
for root, dirs, files in os.walk(path):
if len(files) != 0:
print(files)
for file in files:
if '.jpg' in file or '.png' in file:
path=os.path.join(root,file)
name=os.path.splitext(file)[0]
print(file)
image = cv2.imread(path)
rgb_img = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
dets = detector(rgb_img)
if(len(dets) == 0):
continue
det = dets[0]
face_img = rgb_img[det.top():det.bottom(), det.left():det.right()]
descriptor = face_net.get_descriptor(face_img)
person_name = file[:file.rfind('_')]
person_names.append(person_name)
face_features.append(descriptor)
print('Appending + '+person_name+'...')
with open('gtk_dataset.pkl', 'wb') as f:
pickle.dump(person_names, f)
pickle.dump(face_features, f)
print('Face Library Created!')
if __name__ == "__main__":
create_known(imagePATH)
2.4、人脸检测与识别
import cv2
import os
import time
import numpy as np
import dlib
import align.detect_face
import facenet_model
import mtcnn_model
import pickle
import image_shop
################################ Global variable ######################################
person_names = []
face_features = []
imagePATH = '/home/colin/works/face_recognition_mtcnn_facenet/dataset/processed/Colin/'
face_net = None
mtcnn_det = None
########################################################################################
# 640 480 320 240
def gstreamer_pipeline(
capture_width=320,
capture_height=240,
display_width=320,
display_height=240,
framerate=15,
flip_method=0,
):
return (
"nvarguscamerasrc ! "
"video/x-raw(memory:NVMM), "
"width=(int)%d, height=(int)%d, "
"format=(string)NV12, framerate=(fraction)%d/1 ! "
"nvvidconv flip-method=%d ! "
"video/x-raw, width=(int)%d, height=(int)%d, format=(string)BGRx ! "
"videoconvert ! "
"video/x-raw, format=(string)BGR ! appsink"
% (
capture_width,
capture_height,
framerate,
flip_method,
display_width,
display_height,
)
)
def train_data_load():
global person_names, face_features
with open('gtk_dataset.pkl','rb') as f:
person_names=pickle.load(f)
face_features=pickle.load(f)
def facenet_recognition(image):
faces = []
face_names = []
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
bounding_boxes = mtcnn_det.face_detector(rgb_image)
for bb in bounding_boxes:
person_name = 'unknown'
#face aligment
face_img= mtcnn_det.face_aligner(rgb_image, bb)
#get the face descriptor
descriptor = face_net.get_descriptor(face_img)
min_dist = 0.7 #1
for i in range(len(face_features)):
dist = np.linalg.norm(descriptor-face_features[i])
print('dist:', dist)
if dist < min_dist:
min_dist = dist
person_name = person_names[i]
face_names.append(person_name)
#Fix the rectangle error by colin.tan 2020-11-25
bounding_boxes = bounding_boxes[:,0:4].astype(int)
for name ,box in zip(face_names,bounding_boxes):
cv2.rectangle(image, (box[0],box[1]),(box[2],box[3]), (0, 255, 0), 2)
cv2.putText(image,name, (box[0],box[1]), cv2.FONT_HERSHEY_COMPLEX_SMALL, 0.7, (0, 0, 255), thickness=2)
face_names = None
return image
def face_recognition_livevideo(window_name, camera_idx):
cv2.namedWindow(window_name)
#CSI Camera for get pipeline
cap = cv2.VideoCapture(gstreamer_pipeline(flip_method=camera_idx), cv2.CAP_GSTREAMER)
while cap.isOpened():
ok, frame = cap.read() #read 1 frame
if not ok:
break
resImage= facenet_recognition(frame)
#display
cv2.imshow(window_name, resImage)
c = cv2.waitKey(1)
if c & 0xFF == ord('q'):
break
#close
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
train_data_load()
mtcnn_det = mtcnn_model.g_mtcnn_model()
face_net = facenet_model.g_FaceNetModel('20180402-114759.pb')
face_recognition_livevideo('Find Face', 0)
3、Demo效果
