1.目标是爬取腾讯国内外疫情数据
2.对爬取的数据进行数据清洗
3.清洗后数据的分析和可视化
实现思路:1.到所要爬取的网页使用f12查看源代码,查找所要爬取的数据的路据
2.使用get或post进行数据的爬取
3.提取有用的数据
4.使用pandas库将数据转换为二维表
5.使用pandas库进行数据清洗和回归方程的绘制
6.使用matplotlib库进行数据可视化
技术难点:数据在网页中的查找和爬取,爬取之后对有效数据的提取
打开所要爬取的网页:https://news.qq.com/zt2020/page/feiyan.htmfrom=timeline&isappinstalled=0#/global
使用f12打开工具找到真正的url,通过f12 Network可查找到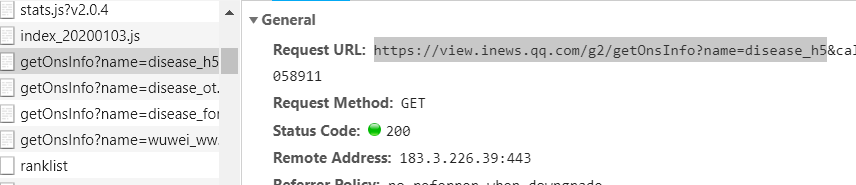
这个文件,文件打开是
同理,这是外国的文件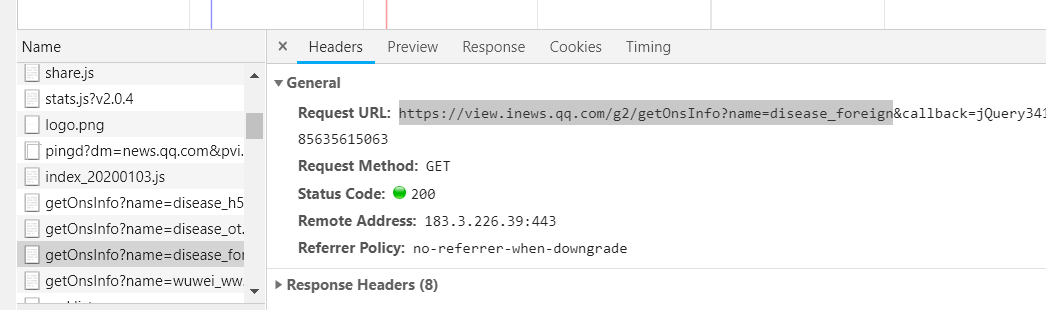
打开是这样的
里面正是所需要的数据
通过Console查找到此文件对应的路径可看到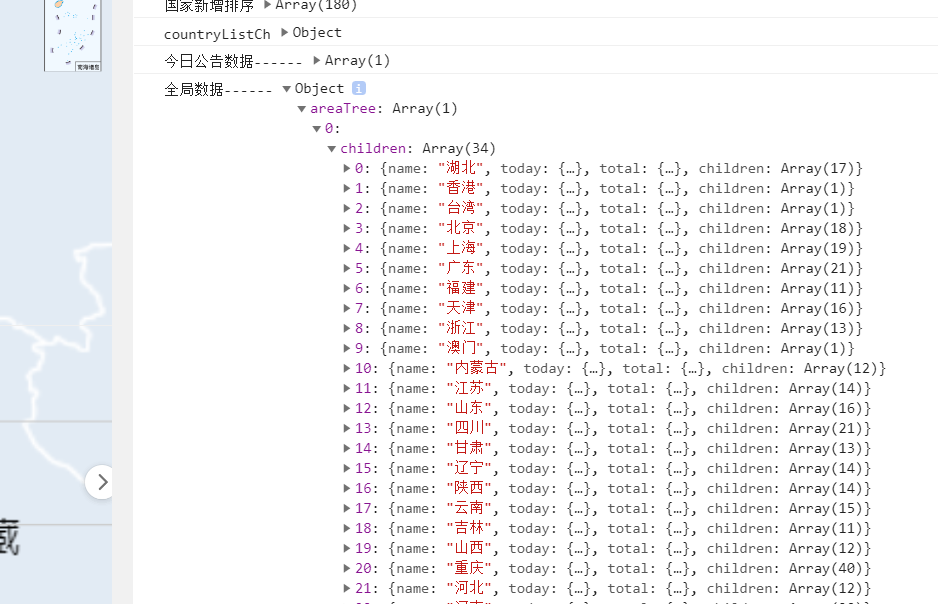
国外的是
可以看到我国的疫情数据在areaTree标签下的0标签下的子标签里,外国数据在countryAddConfirmRankList标签下所以使用以下代码:
#导入相关库
import json import requests import numpy as np import pandas as pd import matplotlib import matplotlib.pyplot as plt from scipy.optimize import leastsq
#爬取的网页地址 url="https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5" url2="https://view.inews.qq.com/g2/getOnsInfo?name=disease_foreign" #伪装请求头 headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} #获取网页数据 r=requests.get(url,timeout=30,headers=headers) req=requests.get(url2,timeout=30,headers=headers) #将数据json化去掉/,方便操作 data = json.loads(r.text) data = json.loads(data['data']) data3 = json.loads(req.text) data3 = json.loads(data3['data'])
print(data)
print(data3)
输出结果国内
国外
接下来提取所需要的数据,用到以下代码:
#从爬取的信息中提取所需信息
china=data['areaTree'][0]['children']
#爬取各大国家疫情情况
country=data3['countryAddConfirmRankList']
#print(china)
chinaTotals="确诊人数:"+str(data['chinaTotal']['confirm'])+\
"疑似人数:"+str(data['chinaTotal']['suspect'])+\
"死亡人数:"+str(data['chinaTotal']['dead'])+\
"治愈人数:"+str(data['chinaTotal']['heal'])+\
"更新日期:"+data['lastUpdateTime']
print(chinaTotals)
#获取中国各省名称,确诊人数,疑似人数,死亡人数,治愈人数
Total=[]
for i in range(len(china)):
Total.append([china[i]['name'],china[i]['total']['confirm'],
china[i]['total']['suspect'],china[i]['total']['dead'],
china[i]['total']['heal']])
#print(Total)
#获取各国新增加确诊人数
Country=[]
for i in range(len(country)):
Country.append([country[i]['nation'],country[i]['addConfirm']])
print(Country)
输出结果如下

下一步将数据转化为二维表然后进行数据清洗代码如下:
#将数据转换为二维表方便数据清洗和进一步的数据可视化
data1=pd.DataFrame(Total,index=range(1,35),columns=['省份','确诊人数','疑似人数','死亡人数','治愈人数'])
data4=pd.DataFrame(Country,index=range(1,11),columns=['国家','新增确诊人数'])
#print(data1)查看输出二维表是否出错
#数据清洗
#查找是否有缺失值
data1.isnull()
data4.isnull()
#只显示存在缺失的行列
data1[data1.isnull().values==True]
data4[data4.isnull().values==True]
#查找重复值
data1.duplicated()
data4.duplicated()
#删除重复值
data2=data1.drop_duplicates()
data5=data4.drop_duplicates()
#统计空值
data2.isna()
data5.isna()
print(data2)
print(data5)
输出结果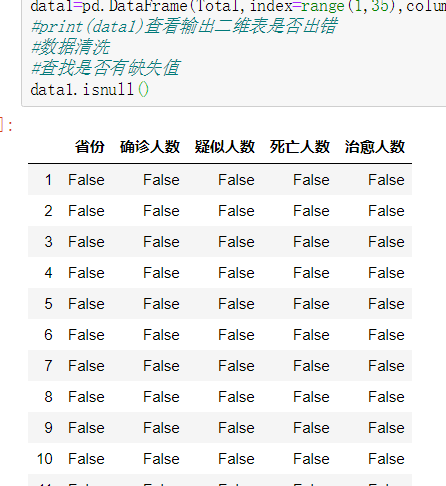
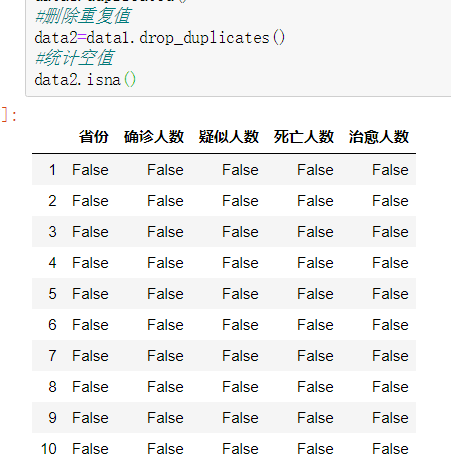
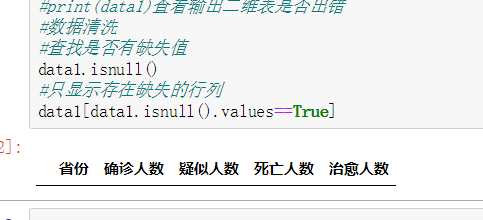
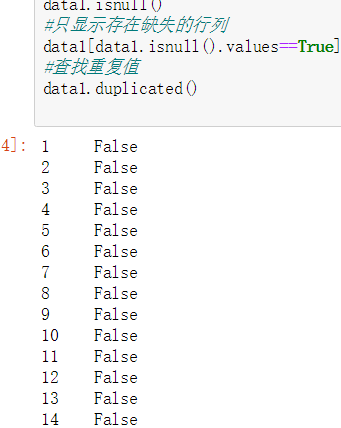
下一步进行数据可视化如下
#进行数据可视化
#正常显示中文
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus']=False
#创建画布
plt.figure(figsize=(10,10))#设置画布大小
#绘制子图1
axes1=plt.subplot(2,2,1)
X=data2.loc[:,'省份']
Y=data2.loc[:,'确诊人数']
#绘制柱状图
plt.bar(X,Y)
plt.title('我国各省至今确诊人数')
plt.xlabel('省份')
plt.ylabel('确诊人数')
#绘制子图2
axes2=plt.subplot(2,2,2)
#绘制确诊人数,疑似人数,死亡人数,治愈人数的饼图
a=[data['chinaTotal']['confirm'],data['chinaTotal']['suspect'],
data['chinaTotal']['dead'],data['chinaTotal']['heal']]
plt.pie(a,labels=['确诊人数','疑似人数','死亡人数','治愈人数'])
#绘制子图3
axes3=plt.subplot(2,1,2)
f=data5.loc[:,'国家']
g=data5.loc[:,'新增确诊人数']
plt.bar(f,g)
plt.title("国外新增确诊人数")
plt.show()
输出结果
接下来绘制散点图和回归方程代码如下:
#绘制散点图建立回归方程
X=data2.loc[:,'确诊人数']
Y=data2.loc[:,'治愈人数']
#计算相关性
X.corr(Y)
def func(params,x):
k,b=params
return k*x+b
#设误差函数
def error(params,x,y):
return func(params,x)-y
#主程序,输出最后的结果
def main():
plt.figure()
p0=[1,1]
Para=leastsq(error,p0,args=(X,Y))
k,b=Para[0]
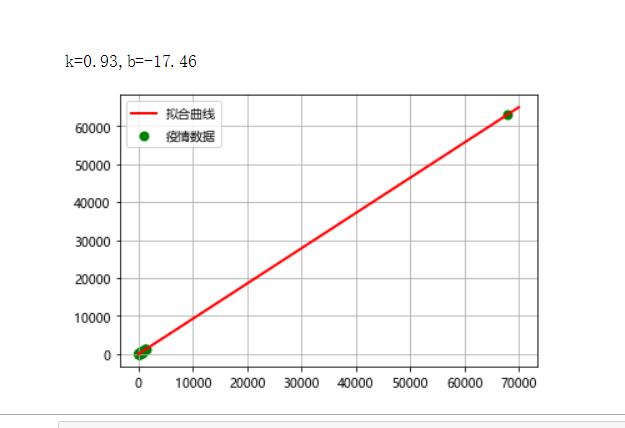
print("k={:.2f},b={:.2f}".format(k,b))
plt.scatter(X,Y,color="green",label="疫情数据",linewidth=2)
#画拟合曲线
x=np.linspace(1,70000,1000)
y=k*x+b
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
plt.legend()#绘制图例
plt.grid()
plt.show()
main()
#保存数据
dataframe_file.to_csv("疫情数据.csv", index=False)
输出结果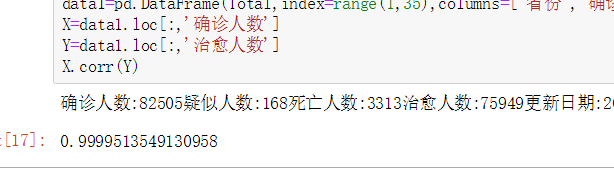
所有代码汇总如下:#导入相关库
import json
import requests
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
url="https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
url2="https://view.inews.qq.com/g2/getOnsInfo?name=disease_foreign"
#伪装请求头
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
#获取网页数据
r=requests.get(url,timeout=30,headers=headers)
req=requests.get(url2,timeout=30,headers=headers)
#将数据json化去掉/,方便操作
data = json.loads(r.text)
data = json.loads(data['data'])
data3 = json.loads(req.text)
data3 = json.loads(data3['data'])
#print(data)查看爬取数据
#从爬取的信息中提取所需信息
china=data['areaTree'][0]['children']
#爬取各大国家疫情情况
country=data3['countryAddConfirmRankList']
#print(china)
chinaTotals="确诊人数:"+str(data['chinaTotal']['confirm'])+\
"疑似人数:"+str(data['chinaTotal']['suspect'])+\
"死亡人数:"+str(data['chinaTotal']['dead'])+\
"治愈人数:"+str(data['chinaTotal']['heal'])+\
"更新日期:"+data['lastUpdateTime']
print(chinaTotals)
#获取中国各省名称,确诊人数,疑似人数,死亡人数,治愈人数
#建立空列表保存数据
Total=[]
for i in range(len(china)):
Total.append([china[i]['name'],china[i]['total']['confirm'],
china[i]['total']['suspect'],china[i]['total']['dead'],
china[i]['total']['heal']])
#print(Total)
#获取各国新增加确诊人数
#建立空列表保存数据
Country=[]
for i in range(len(country)):
Country.append([country[i]['nation'],country[i]['addConfirm']])
#print(Country)
#将数据转换为二维表方便数据清洗和进一步的数据可视化
data1=pd.DataFrame(Total,index=range(1,35),columns=['省份','确诊人数','疑似人数','死亡人数','治愈人数'])
data4=pd.DataFrame(Country,index=range(1,11),columns=['国家','新增确诊人数'])
#print(data1)查看输出二维表是否出错
#数据清洗
#查找是否有缺失值
data1.isnull()
data4.isnull()
#只显示存在缺失的行列
data1[data1.isnull().values==True]
data4[data4.isnull().values==True]
#查找重复值
data1.duplicated()
data4.duplicated()
#删除重复值
data2=data1.drop_duplicates()
data5=data4.drop_duplicates()
#统计空值
data2.isna()
data5.isna()
print(data2)
print(data5)
#进行数据可视化
#正常显示中文
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
#正常显示负号
plt.rcParams['axes.unicode_minus']=False
#创建画布
plt.figure(figsize=(10,10))#设置画布大小
#绘制子图1
axes1=plt.subplot(2,2,1)
X=data2.loc[:,'省份']
Y=data2.loc[:,'确诊人数']
#绘制柱状图
plt.bar(X,Y)
#标题
plt.title('我国各省至今确诊人数')
#x轴名称
plt.xlabel('省份')
#y轴名称
plt.ylabel('确诊人数')
#绘制子图2
axes2=plt.subplot(2,2,2)
#绘制确诊人数,疑似人数,死亡人数,治愈人数的饼图
a=[data['chinaTotal']['confirm'],data['chinaTotal']['suspect'],
data['chinaTotal']['dead'],data['chinaTotal']['heal']]
#绘制饼图
plt.pie(a,labels=['确诊人数','疑似人数','死亡人数','治愈人数'])
#绘制子图3
axes3=plt.subplot(2,1,2)
f=data5.loc[:,'国家']
g=data5.loc[:,'新增确诊人数']
#绘制柱状图
plt.bar(f,g)
plt.title("国外新增确诊人数")
plt.show()
#绘制散点图建立回归方程
X=data2.loc[:,'确诊人数']
Y=data2.loc[:,'治愈人数']
X.corr(Y)
def func(params,x):
k,b=params
return k*x+b
#设误差函数
def error(params,x,y):
return func(params,x)-y
#主程序,输出最后的结果
def main():
plt.figure()
p0=[1,1]
Para=leastsq(error,p0,args=(X,Y))
k,b=Para[0]
print("k={:.2f},b={:.2f}".format(k,b))
plt.scatter(X,Y,color="green",label="疫情数据",linewidth=2)
#画拟合曲线
x=np.linspace(1,70000,1000)
y=k*x+b
plt.plot(x,y,color="red",label="拟合曲线",linewidth=2)
plt.legend()#绘制图例
plt.grid()
plt.show()
main()
#保存数据
dataframe_file.to_csv("疫情数据.csv", index=False)
通过数据的分析和可视化可得知:国内疫情逐渐稳定,确诊人数多,治愈人数也多,每日增加人数少。国外疫情形势不容乐观,每日确诊人数增长迅猛。
总结:这次作业大部分要求都做了,爬取国外是后面才加进去的为了美观插入到了代码中,导致变量名有些乱。散点图由于湖南省确诊人数与其他省差距实在太大,导致点都集中在一起。