安装
能直接安装就再好不过
pip install xgboost
如果不能就下载之后本地安装
安装包下载地址 这里 想要啥包都有

数据集
pima-indians-diabetes.csv 文件

调查印度糖尿病人的一些数据, 最终的预测结果是是否患病
# 1. Number of times pregnant # 2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test # 3. Diastolic blood pressure (mm Hg) # 4. Triceps skin fold thickness (mm) # 5. 2-Hour serum insulin (mu U/ml) # 6. Body mass index (weight in kg/(height in m)^2) # 7. Diabetes pedigree function # 8. Age (years) # 9. Class variable (0 or 1)
共有 8 个特征变量, 以及 1 个分类标签
Xgboost 使用
基础使用框架
from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 下载数据集 datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签 X = datasets[:,0:8] Y = datasets[:,8] # 切分 训练集 测试集 seed = 7 test_size = 0.33 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建 训练 model = XGBClassifier() model.fit(X_train, y_train) # 预测模型 y_pred = model.predict(X_test) predictions = [round(i) for i in y_pred] # 精度计算 accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" %(accuracy * 100) )
Accuracy: 77.95%
中间过程展示
Xgboost 的原理是在上一棵树的基础上通过添加树从而实现模型的提升的
如果希望看到中间的升级过程可以进行如下的操作
from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 下载数据集 datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签 X = datasets[:,0:8] Y = datasets[:,8] # 切分 训练集 测试集 seed = 7 test_size = 0.33 X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建 训练 model = XGBClassifier() eval_set = [(X_test, y_test)] model.fit(X_train, y_train, # 传入的训练数据 early_stopping_rounds=10, # 当多少次的 lost值不在下降就停止模型 eval_metric='logloss', # lost 评估标准 eval_set=eval_set, # 构造一个测试集, 没加入一个就进行一次测试 verbose=True # 是否展示出中间的详细数据打印 ) # 预测模型 y_pred = model.predict(X_test) predictions = [round(i) for i in y_pred] # 精度计算 accuracy = accuracy_score(y_test, predictions) print("Accuracy: %.2f%%" %(accuracy * 100) )
打印的过程中会体现出 lost 值的变化过程
扫描二维码关注公众号,回复:
8017441 查看本文章



[0] validation_0-logloss:0.660186 Will train until validation_0-logloss hasn't improved in 10 rounds. [1] validation_0-logloss:0.634854 [2] validation_0-logloss:0.61224 [3] validation_0-logloss:0.593118 [4] validation_0-logloss:0.578303 [5] validation_0-logloss:0.564942 [6] validation_0-logloss:0.555113 [7] validation_0-logloss:0.54499 [8] validation_0-logloss:0.539151 [9] validation_0-logloss:0.531819 [10] validation_0-logloss:0.526065 [11] validation_0-logloss:0.519769 [12] validation_0-logloss:0.514979 [13] validation_0-logloss:0.50927 [14] validation_0-logloss:0.506086 [15] validation_0-logloss:0.503565 [16] validation_0-logloss:0.503591 [17] validation_0-logloss:0.500805 [18] validation_0-logloss:0.497605 [19] validation_0-logloss:0.495328 [20] validation_0-logloss:0.494777 [21] validation_0-logloss:0.494274 [22] validation_0-logloss:0.493333 [23] validation_0-logloss:0.492211 [24] validation_0-logloss:0.491936 [25] validation_0-logloss:0.490578 [26] validation_0-logloss:0.490895 [27] validation_0-logloss:0.490646 [28] validation_0-logloss:0.491911 [29] validation_0-logloss:0.491407 [30] validation_0-logloss:0.488828 [31] validation_0-logloss:0.487867 [32] validation_0-logloss:0.487297 [33] validation_0-logloss:0.487562 [34] validation_0-logloss:0.487789 [35] validation_0-logloss:0.487962 [36] validation_0-logloss:0.488218 [37] validation_0-logloss:0.489582 [38] validation_0-logloss:0.489334 [39] validation_0-logloss:0.490968 [40] validation_0-logloss:0.48978 [41] validation_0-logloss:0.490704 [42] validation_0-logloss:0.492369 Stopping. Best iteration: [32] validation_0-logloss:0.487297 Accuracy: 77.56%
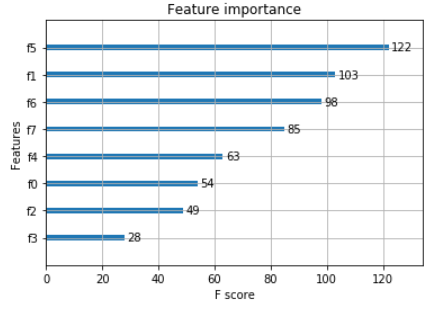
特征重要性展示
from numpy import loadtxt from xgboost import XGBClassifier from xgboost import plot_importance from matplotlib import pyplot # 下载数据集 datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签 X = datasets[:,0:8] Y = datasets[:,8] # 模型创建 训练 model = XGBClassifier() model.fit(X, Y) # 展示特征重要程度 plot_importance(model) pyplot.show()
参数调节
Xgboost 有很多的参数可以调节
常见参数
学习率
learning rate 一般设置在 0.1 以下
tree 相关参数
max_depth 最大深度
min_child_weight 最小叶子权重
subsample 随机选择比例
colsample_bytree 速记特征比例
gamma 损失率相关的一个参数
正则化参数
lambda
alpha
其他参数示例
更详细的的参数可以参考官方文档
xgb1 = XGBClassifier( learning_rate= 0.1, n_estimators=1000, max_depth=5, min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, objective='binary:logistic', # 指定出是用什么损失函数, 一阶导还是二阶导 nthread=4, # scale_pos_weight=1, seed=27 # 随机种子 )
参数选择示例
from numpy import loadtxt from xgboost import XGBClassifier from sklearn.model_selection import GridSearchCV from sklearn.model_selection import StratifiedKFold # 下载数据集 datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分 特征 标签 X = datasets[:,0:8] Y = datasets[:,8] # 模型创建 训练 model = XGBClassifier() # 学习率备选数据 learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3] param_grid = dict(learning_rate=learning_rate) # 格式要求转换为字典格式 # 交叉验证 kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7) # 训练模型最佳学习率选择 grid_serarch = GridSearchCV(model, param_grid, scoring='neg_log_loss', n_jobs=-1, # 当前所有 cpu 都跑这个事 cv=kfold) grid_serarch = grid_serarch.fit(X, Y) # 打印结果 print("Best: %f using %s" % (grid_serarch.best_score_, grid_serarch.best_params_)) means = grid_serarch.cv_results_['mean_test_score'] params = grid_serarch.cv_results_['params'] for mean, param in zip(means, params): print("%f with: %r" % (mean, param))
打印结果
Best: -0.483304 using {'learning_rate': 0.1}
-0.689811 with: {'learning_rate': 0.0001}
-0.661827 with: {'learning_rate': 0.001}
-0.531155 with: {'learning_rate': 0.01}
-0.483304 with: {'learning_rate': 0.1}
-0.515642 with: {'learning_rate': 0.2}
-0.554158 with: {'learning_rate': 0.3}