一、主题式网络爬虫设计方案
1.网络爬虫名称:Python爬取虾米音乐排行榜
2.网络爬虫爬取的内容与数据特征分析:爬取玩家评论的数据,分析各类数据之间的特征与关系
3.网络爬虫设计方案概述:
思路:爬取数据,分析html页面,标记需要的数据标签,对数据提取、处理、可视化、绘制图形、保存数据
二、主题页面的结构特征分析
1、主题页面的结构与特征分析:
需要爬取的内容如下:
以 https://www.xiami.com/billboard/306
为例:
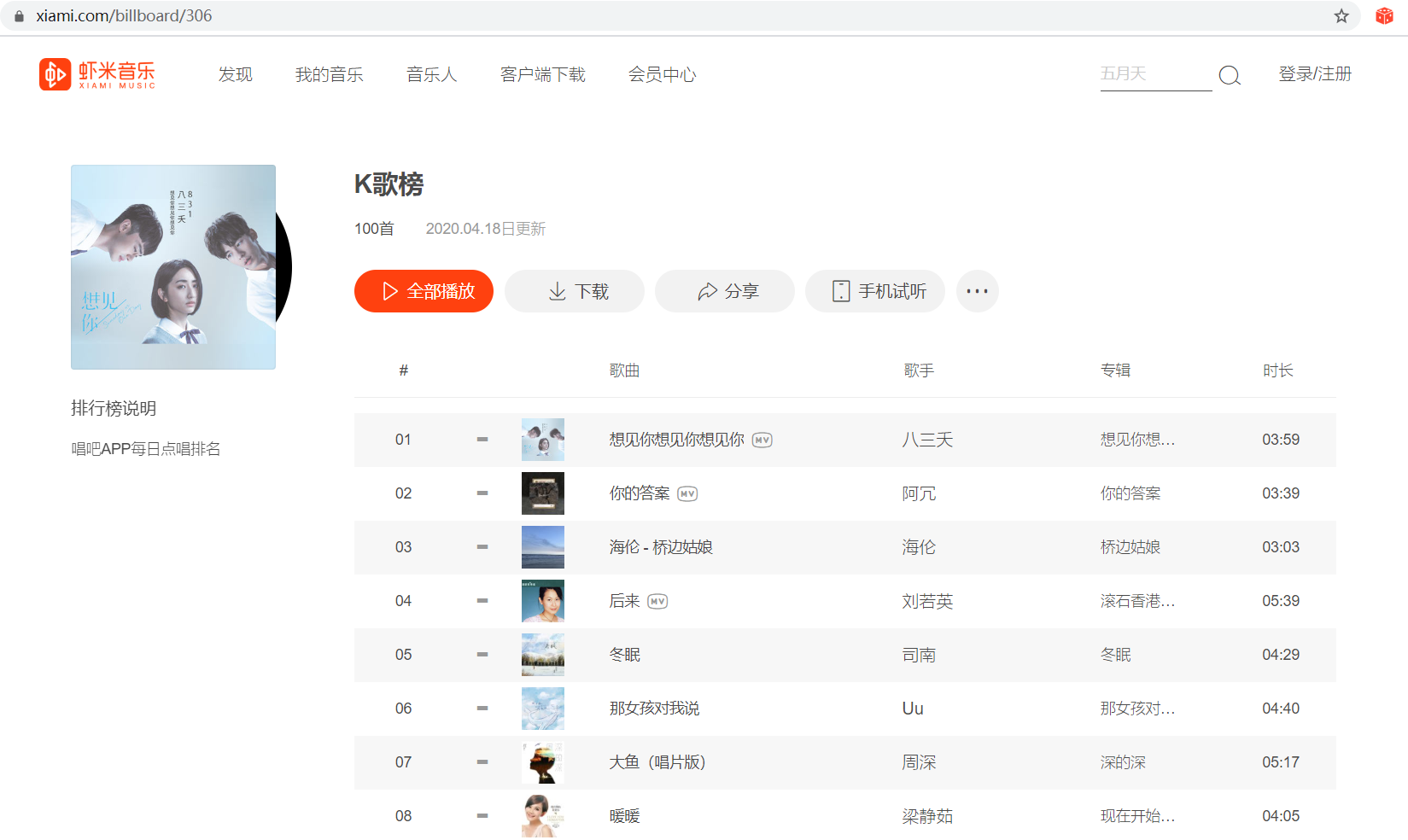
2、页面解析:



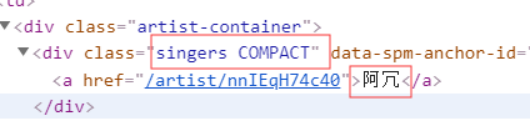

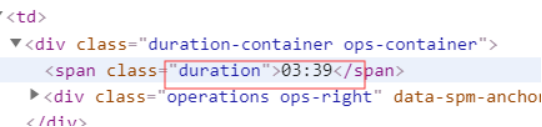
三、网络爬虫程序设计
1.数据爬取与采集:
获取网页数据:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import requests #获取虾米网页数据 def getHtml(url): try: # 伪装UA ua = {'user-agent': 'Mozilla/5.0 Chrome/79.0.3945.88 Safari/537.36'} # 读取网页 r = requests.get(url, headers=ua) # 获取状态 r.raise_for_status() # 打印数据 print(r.text) # 返回数据 return r.text except: return "Fail"
数据分析:
from bs4 import BeautifulSoup def parseHtml(html): # 数据数组 datas = [] # 结构解析 soup = BeautifulSoup(html, "html.parser") # 获取排名 ids = soup.select('.em.index') # 组号 i = 0 # 循环排名号 for id in ids: # 字典 data = {} # 获取编号 idd = id.get_text() # 打印数据 print(idd) # 获取歌曲名 titles = soup.select('.song-name.em')[i].get_text() # 打印数据 print(titles) # 获取歌手 songer = soup.select('.singers.COMPACT')[i].get_text() # 打印数据 print(songer) # 获取专辑 album = soup.select('.album')[i].get_text() # 打印数据 print(album) # 获取时长 duration = soup.select('.duration')[i].get_text() # 打印数据 print(duration) # 数组 i = i + 1 # 加入字典 data['#'] = idd data['歌曲'] = titles data['歌手'] = songer data['专辑'] = album data['时长'] = duration # 加入数组 datas.append(data) # 返回数组 return datas
写入Excle表格,分析数据更方便:
import records # 初始化组件 results = records.RecordCollection(iter(list)) # 文件流 with open('list.xlsx', 'wb') as f: # 写入 f.write(results.export('xlsx'))
运行结果:
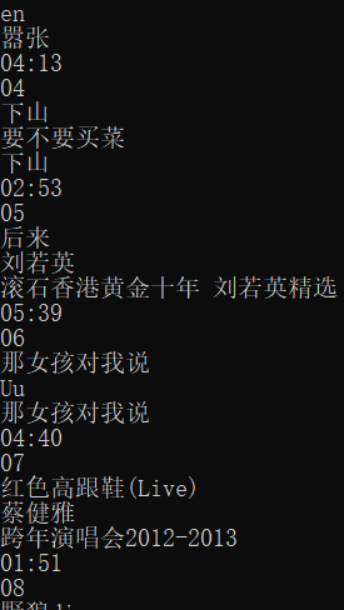
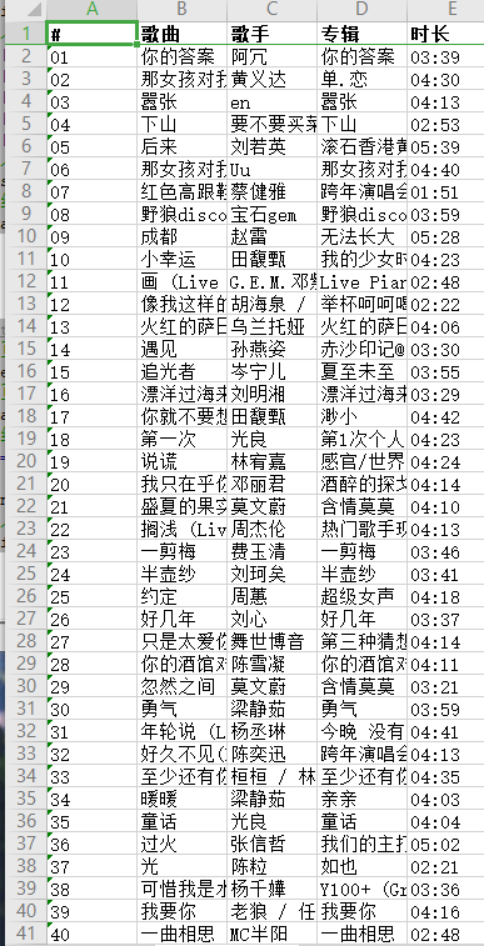
完整代码
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup import records def getHtml(url): ''' 获取目标网页数据 ''' try: # 伪装UA ua = {'user-agent': 'Mozilla/5.0'} # 读取网页 r = requests.get(url, headers=ua) # 获取状态 r.raise_for_status() # 打印数据 print(r.text) # 返回数据 return r.text except: return "Fail" def parseHtml(html): # 数据数组 datas = [] # 结构解析 soup = BeautifulSoup(html, "html.parser") # 获取排名 ids = soup.select('.em.index') # 组号 i = 0 # 循环排名号 for id in ids: # 字典 data = {} # 获取编号 idd = id.get_text() # 打印数据 print(idd) # 获取歌曲名 titles = soup.select('.song-name.em')[i].get_text() # 打印数据 print(titles) # 获取歌手 songer = soup.select('.singers.COMPACT')[i].get_text() # 打印数据 print(songer) # 获取专辑 album = soup.select('.album')[i].get_text() # 打印数据 print(album) # 获取时长 duration = soup.select('.duration')[i].get_text() # 打印数据 print(duration) # 链接 .song-name.em > a a = 'https://www.xiami.com' + soup.select('.song-name.em > a')[i].get('href') # 打印数据 print(a) # 数组 i = i + 1 # 加入字典 data['#'] = idd data['歌曲'] = titles data['歌手'] = songer data['专辑'] = album data['时长'] = duration data['链接'] = a # 加入数组 datas.append(data) # 返回数组 return datas def main(): # url url = "https://www.xiami.com/billboard/306" # 获取网页数据 html = getHtml(url) # 解析网页结构 list = parseHtml(html) # 初始化组件 results = records.RecordCollection(iter(list)) # 文件流 with open('list.xlsx', 'wb') as f: # 写入 f.write(results.export('xlsx')) main()
四、结论(10分)
对本次程序设计任务完成的情况做一个简单的小结。
python很高效率,以后做调查调研更加方便了!