
本文由 GOPS2017 北京站大会供稿并整理发布,高效运维社区致力于陪伴您的职业生涯,与您一起愉快的成长。
作者简介:

赵舜东
中国SaltStack用户组发起人
江湖人称:赵班长,曾在武警某部负责指挥自动化的架构和运维工作,2008年退役后一直从事互联网运维工作,历任运维工程师、运维经理、运维架构师、运维总监。《SaltStack技术入门与实战》作者,《运维知识体系》作者,GOPS金牌讲师,Exin DevOps Master认证讲师。
运维在忙什么?
下面是一个运维朋友日常工作中比较常见的一个场景:
开发: Hi,哥们,我刚才上线了一个新功能,帮我看一下运行日志有没有什么异常……
运维: 好的,马上;测试: Hi,兄弟,目前A接口的访问量掉了;帮我看下错误日志有啥ERROR……
运维:好的,稍等;开发: Hi,好基友,帮我把我log目录下的日志文件取下来……
运维: 好的,过会儿给你;
另外,我之前的运维团队,有的运维一天到晚都忙这些东西;部署、执行脚本、拿文件、awk分析日志等等,而且还忙的不行。
还有个做系统运维的工程师的朋友,我问他每天都忙什么。他说每天拿日志占1/3的工作量;第二是部署、把代码上传服务器什么的。
那么运维天天在忙什么呢?我想多半在处理日志相关的问题吧~
日志需求
从日志来说,对于运维来说需要进行哪些日志收集。对于这个问题可以分为一下五个方面。

需求一:系统日志
首先是要掌握操作系统的运行状态;系统日志非常有用。例如,一个内存坏了你怎么能知道?一般内存坏在系统上会有日志提示,或者写个阈值内存低于多少报警。但是有时候内存是8G的,坏了一根内存条不知道;而且内存条硬件日志上也是看不出来的。通过系统日志就可以发现该问题。
需求二:访问日志
之前我们做广告,访问日志对我们来说就是命根子;我们要依赖访问日志拿到非常多的数据。以此来统计分析访问来源、url请求频次、响应时间以及成功率等等。
需求三:运行日志
通过运行日志我们可以了解到系统运行详情,运行的异常以及业务的输出日志。
需求四:错误日志
你需要根据关键字来查找一些错误日志。例如,很多时候发现日志和流量波动是可以关联上的;可以以此来做全流量分析。
需求五:关联日志
最后就是业务关联日志。这里举个曾经遇到过的一个例子。刚开始做电商的时候,老板没事过来问,平时我们每分钟也就几十单,问我们为什么最近的一段时间每分钟一下子来了好几百单。
其实当时觉得挺奇怪的,为什么问我呢。后来想想因为运维做的不到位;你说突然来了很多单子,运营也不知道,这个时候最容易知道的是运维了。你可以通过各种手段判断出这个订单到底是干嘛的。
所以我认为运维的目标是:“知其然,知其所以然”。比如说,如果老板问你“为什么最近5分钟这么多订单”,你可以告诉他“是因为我们做了买一送一的活动,很多人就来了”。
日志收集环境的痛点
先抛出一个问题,为什么要做日志收集?开发人员需要查询日志;但是开发人员不能有线上服务器登录的权限。现在很多大公司也不允许运维登录线上机器了。因为ssh登录上去就可以干出和别人一样的事情;就可能导致这个节点和其他节点不一样,不一样就出事了。
还有就是各个系统都有日志;日志数据分散难以查找。这个痛点有两个方面的问题需要解决;其一就是如何收集,其二就是标准化。

对于一个应用系统你需要明白你要做哪些日志;在做需求日志调研的时候,把日志需求确定下来。之前我们有个用户服务,因为压力很大;我们需要单独拆分成为微服务。此时有两种待选方案,第一种是RPC过程调用;
第二种是http协议。当时研发考虑了运维的需求,第一个是权限控制;第二个是监控的需求。监控的需求包括集群健康检查以及调用和响应的统计。
需求提出来后,除非做个框架,要不然RPC方式做不了;要不然只能选用http。因为系统将来是要运行的;所以非功能的需求也是很大的一块,在做需求的时候一定要把运维的需求考虑进去。
解决疼点的神器—ELK架构起源
曾经的ELK架构
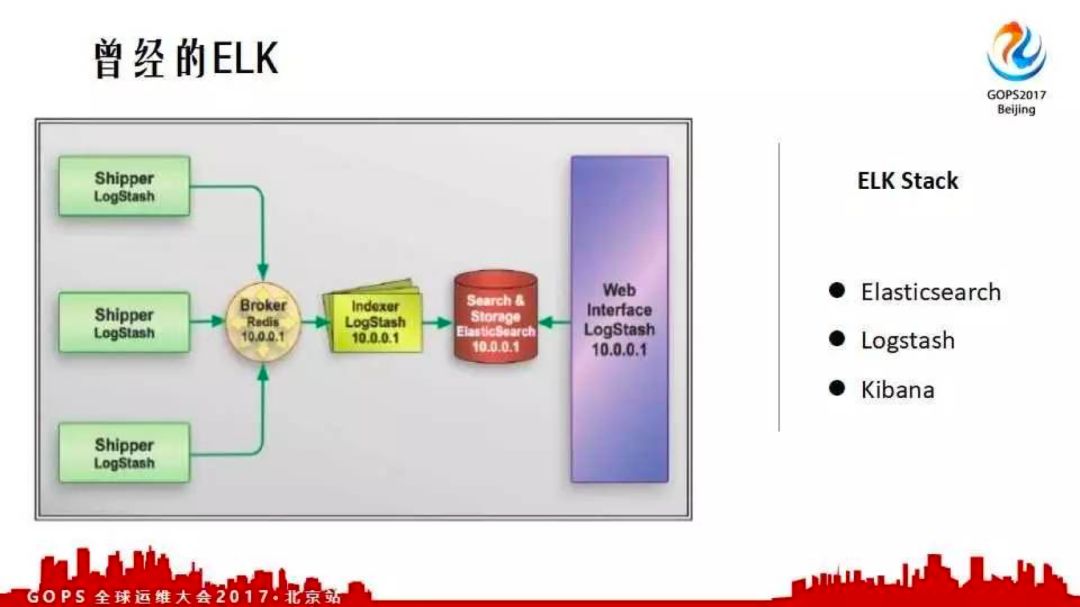
曾经的ELK架构是logstash、elasticsearch及kibana。在当下的容器时代该怎么办?我们之前的做法是在每台物理机上都起一个docker。所有容器启动的时候,就可以获取到容器相关的目录;把目录统一起来写在这个里面,该容器中logstash把日志收走。这种方式没有成本比较低,没有什么技术瓶颈。
elasticsearch是基于lucene实现的分布式全文搜索引擎。elasticsearch提供原生的 java API;同时,也提供restful的API。
logstash作为数据采集端;同时,具备数据流的处理能力。kibana作为前端数据展示;可以呈现各种复杂数据结构,灵活度很高。
现在的Elastic Stack
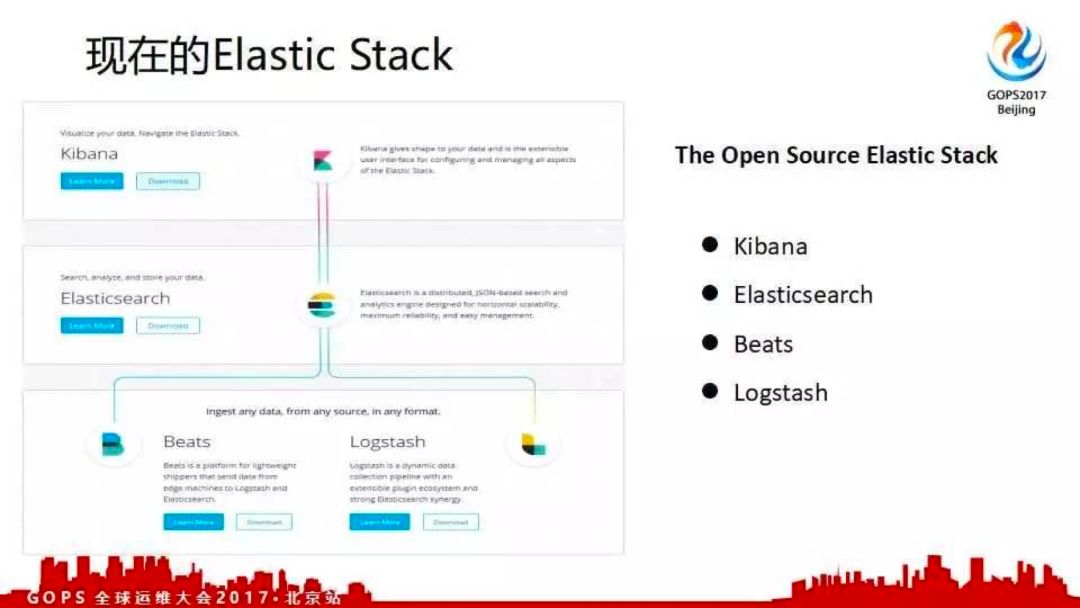
现在ELK更名为Elastic Stack;因为elastic收购了beats工具。beats工具可以做日志收集、网络收集及流收集等,扩大了整个生态圈。
目前elastic公司也在做SaaS,SaaS面对的是互联网所有用户也是未来大的趋势。
ELK学习之elasticsearch入门

下面将介绍elasticsearch相关的基础知识。elasticsearch集群有三种状态,分别是绿色、黄色和红色。绿色表示所有的主、副分片都正常运行。
这里涉及到分片的概念,elastisearch的分片其实是一个节点上lucene实例。elasticsearch一个索引默认情况下分成五个分片和一个副本。
假设有两台机器,其中一台机器挂了;原有的副本分片会被提升为主分片。通过这样的方式来保证它的高可用。集群黄色表示所有主分片正常运行;但是存在有问题的副本分片。此时可能有副本分片丢失或没有创建,但数据不会丢失。
红色说明集群存在主分片不正常运行;这时可能有数据丢失的风险。
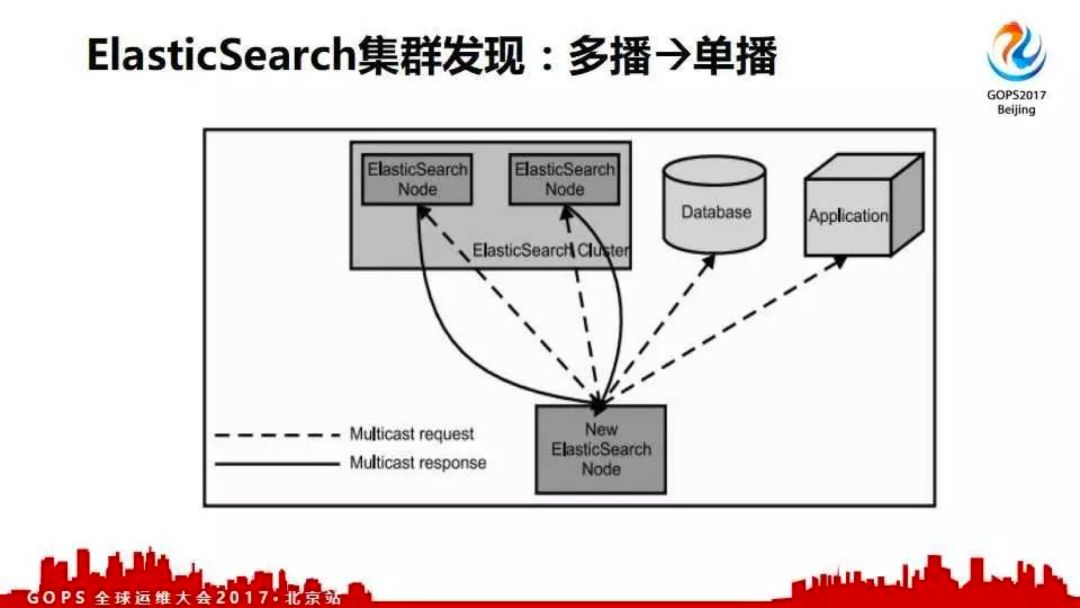
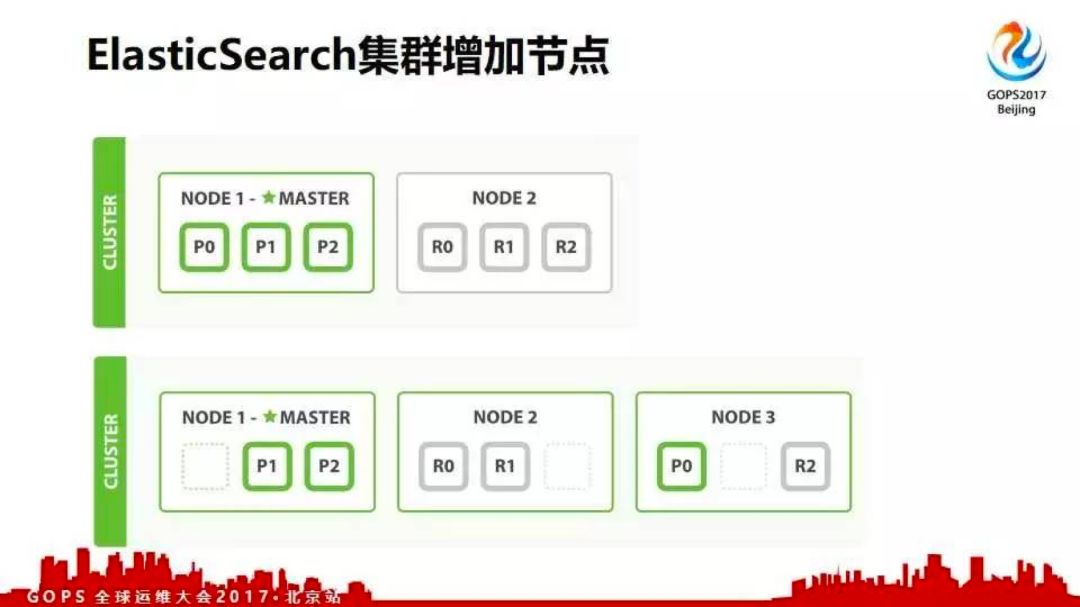
elastisearch的集群发现最早是多播方式的,在后来的2.x版本中改成单播了;因为多播发现存在一些问题。现在的5.1版本都改成单播发现方式了。在绿色状态下,当集群增加一个节点后集群会自动均衡分片,将部分分片迁移到刚加入的节点上。

索引的副本数量是可以调整;在节点数量一定的情况下只是增加冗余度,并不能提高性能。比如三个副本,这个时候同时挂两台机器都不会导致数据丢失;但是分片数量要根据规模进行调优。

节点宕机了怎么办?其实elasticsearch这是很正常的。如果主节点挂了,集群会重新选取一个master。选主完成后集群中分片会自动均衡。如有副本分片丢失,会自动创建新的副本分片。
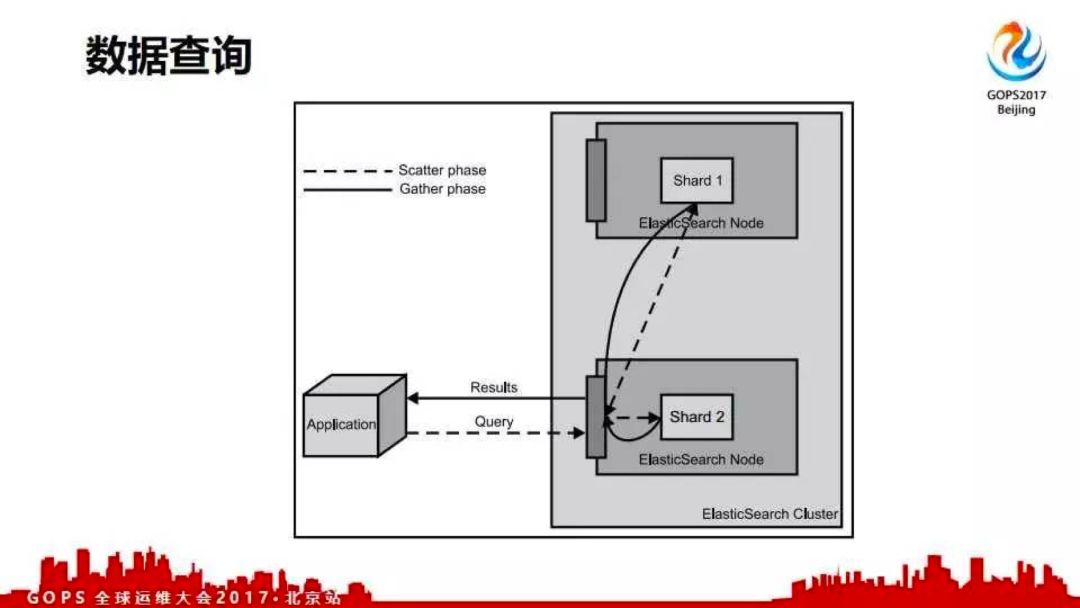
elasticsearch所有节点都接受查询请求,查询请求被调度到各个节点进行数据检索;各个节点返回结果并合并响应查询请求。查询过程如下图所示。
ELK学习之logstash入门
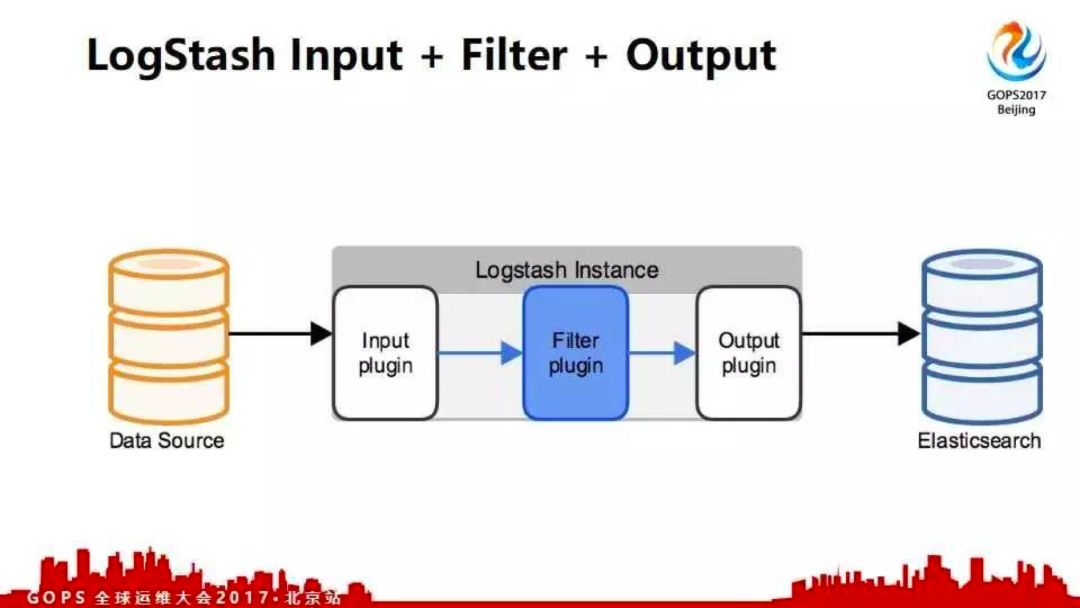
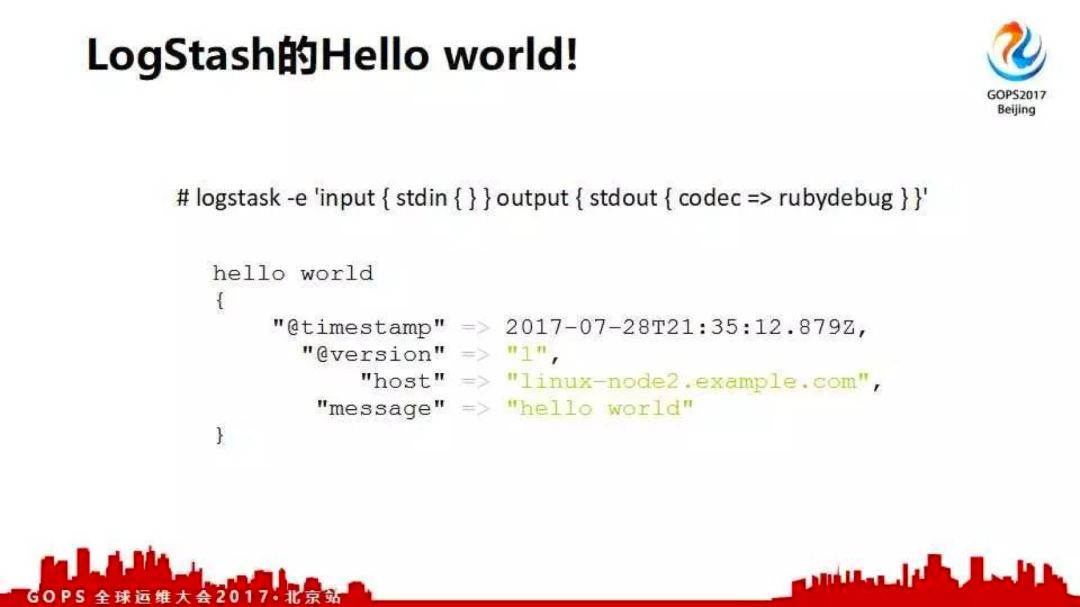
下面介绍如何使用logstash进行日志收集,并讲一些案例。这是一个logstash的hello world,直接在命令行输出。logstash有三个模块,分别是input、filter和output。数据input存stdin;从标准输入进来,到标准输出。这里面加了编码,输入hello world效果就是这样;你的数据在message中,同时logstash会加一个时间戳。
再看一个案例,我从标准输入直接写入elasticsearch怎么写。这里写一个文件,input标准输入;然后是output。output中使用一个插件将其写入elasticsearch;还有个标准输出,通过rubydebug展示出来。学习logstash主要是学习各种插件的使用。比如第一个要收集系统日志;系统日志文件从哪里来,使用input插件。数据要写到elasticsearch里面去,通过output中的插件实现。
在新版本的ELK中,logstash、elasticsearch以及kibana的版本都统一了;学习可以直接看官方文档。

我们看一个demo案例。demo案例是输入什么东西,输入到ES里面;同时输出到当前的rubydebug。这里logstash装了一个elasticsearch插件;目前elasticsearch里面有两个索引。你不写索引名会自动生成索引名,后面自带时间戳。最简单日志收集方式就是一个文件,把它直接写到elasticsearch中。
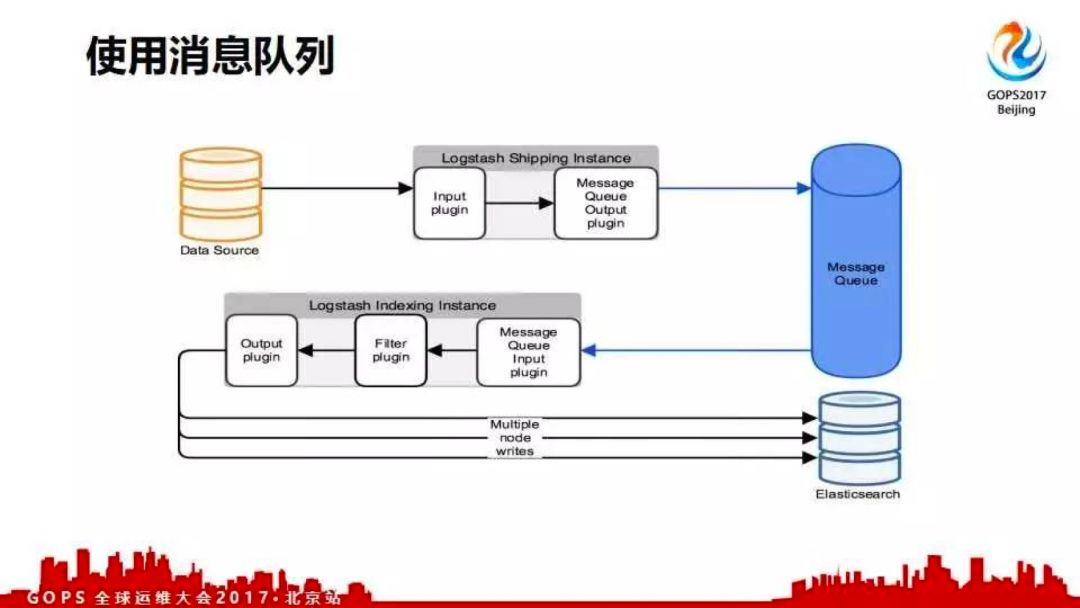
下一个是使用消息队列做日志收集的解耦;这个架构是目前经典的架构。数据源写在input里面,用个插件把数据采集到;然后output用消息队列插件把数据写到消息队列中。logstash有很多消息队列插件,例如kafka、rabbitmq、zeromq等。
什么是解耦?解耦之后后端所有的东西都挂了,只要消息队列不挂这个日志就不会丢;因为全写在消息队列中。消息队列可以通过集群保证不会挂。
再者通过解耦可以做什么呢?数据原封不动收到消息队列中,我不在采集的实例上处理。如果那样做的话,当数据量很大的情况下,这时候CPU的就可能扛不住而影响到业务的正常。
我们在消息队列之后接上logstash进行消费,写入elasticsearch。在logstash的filter模块对数据进行处理。同时,可以根据消费的情况起多个消费者实例。
ELK 学习之 kibana 简介与 ELK 企业实践
kibana介绍
简单介绍一下kibana,原因是没有数据就没法作图。实际上kibana作图相对来说比较简单,千万不要担心学不会;只要有数据肯定就能学会。
kibana的图简单看一下;它有查看时间的范围,例如今天。经常有人说,我刚写的日志为什么没有;就是因为时间的问题。有很多相对绝对的时间范围;所有的搜索都是可以保存下来的,保存的搜索语句可以做其他相关的作用。这样的话,你在做可视化的时候就可以拿来用了。比如我们创建一个可视化图形,我们数据能够做简单统计多少行;你可以从一个已保存的搜索来实现。
还有你可以将多个可视化视图放到dashboard中;同时,dashboard也是可以保存复用的。通过kibana可以做很好看的大盘。比如我们之前做过的业务的大盘、运维的大盘;一边是值班表,一边是用户分钟注册数、用户日活饼图、核心数据库日志等等类似的东西。
ELK企业实践
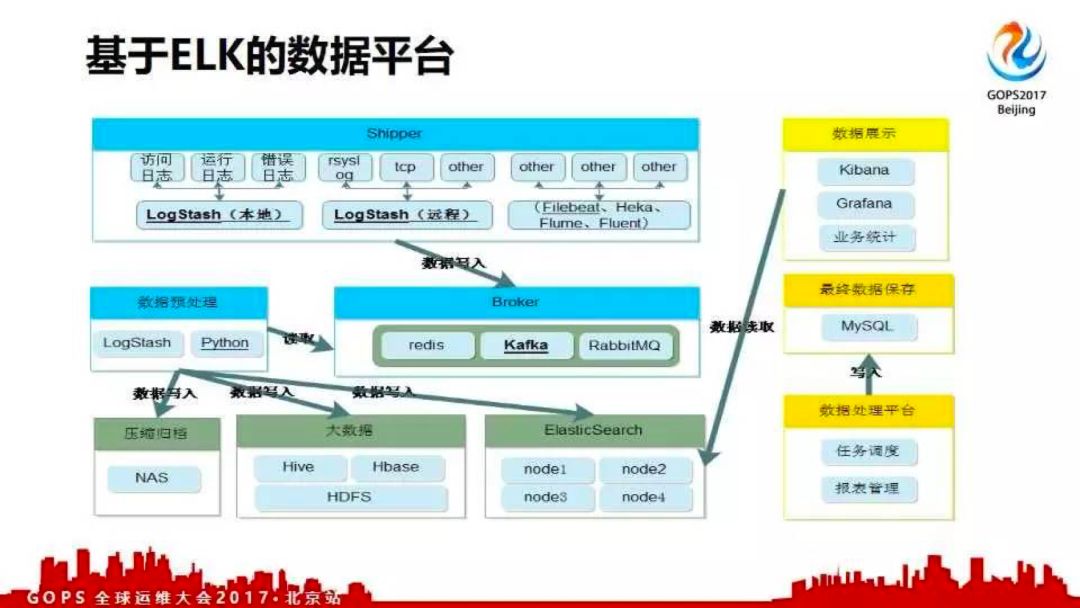
这是基于elasticsearch做的架构图;主要部分是收集消息队列和不同的存储。因为logstash的插件比较多,所以所有的东西都要通过logstash来处理。目前ELK相关的书籍就是《ELK权威指南》,有纸质版的也有免费的PDF版,大家可以看一看。
整体学习ELK记住我说的几句话;整个工具不是重点,重点是怎么在公司推日志标准化。因为日志不标准,收集一推乱七八糟的日志没用;让后短发挥价值的事情全都做不了。然后是通过工具做统一的采集。
logstash还可以做报警处理;比如根据关键字发一个什么东西到指定的地方。你自己也可以做把所有的日志写到elasticsearch中,然后调用elasticsearch;如果发现关键字就报警,这也是一种方式。
举个例子,我们的流量突然有一个小坑,这个时候你去查nginx错误日志发现有。去查php日志也有,再去查mysql慢查询也是有。mysql慢查询需要正则匹配;然后很多人跑过来问我正则写的对不对。这时候就很崩溃了。所以建立日志标准化至关重要。
更多相关文章阅读