1.前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以点击下方链接自行获取
作为爬虫一员,掌握一门爬虫框架是必备技能,因此作为一名小白的你,我想向你推荐『Scrapy』。
具体『Scrapy』是什么,作用这些就不啰嗦(都是废话,百度有Scrapy简介),时间宝贵,就直接上干货(实战案例带你体验scrapy的使用)。
下面会以『B站』为目标进行实战!
2.Scrapy入门实战
1.环境准备
安装scrapy
pip install scrapy
通过上面这个命令即可直接安装好scrapy库
2.建立scrapy项目
scrapy startproject Bili
通过上面这个命令可以建立一个项目名称:Bili 的爬虫项目。

这里就可以在桌面建立了一个名字为:Bili 的爬虫项目
项目结构
Bili
├── Bili
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── __pycache__
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
各个文件作用
- scrapy.cfg:项目的总配置文件,通常无须修改。
- Bili:项目的 Python 模块,程序将从此处导入 Python 代码。
- Bili/items.py:用于定义项目用到的 Item 类。Item 类就是一个 DTO(数据传输对象),通常就是定义 N 个属性,该类需要由开发者来定义。
- Bili/pipelines.py:项目的管道文件,它负责处理爬取到的信息。该文件需要由开发者编写。
- Bili/settings.py:项目的配置文件,在该文件中进行项目相关配置。
- Bili/spiders:在该目录下存放项目所需的蜘蛛,蜘蛛负责抓取项目感兴趣的信息。
3.明确爬取内容

https://search.bilibili.com/all?keyword=%E8%AF%BE%E7%A8%8B&page=2
以上面链接为例(B站),爬取视频的标题(title)和链接(url)
4.定义项目中每一个类
Items类
import scrapy
class BiliItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#pass
# 视频标题
title = scrapy.Field()
# 链接
url = scrapy.Field()
爬取字段是视频的标题(title)和链接(url),所以对于了title和url两个变量
定义spider类
spider类作用是自定义网页解析规则(新建scrapy项目是没有的,需要自己新建)。
Scrapy 为创建 Spider 提供了 scrapy genspider 命令,该命令的语法格式如下:
scrapy genspider [options] <name> <domain>
在命令行窗口中进入 Bili 目录下,然后执行如下命令即可创建一个 Spider:
scrapy genspider lyc "bilibili.com"

运行上面命令,即可在 Bili 项目的 Bili /spider 目录下找到一个 lyc.py 文件
编辑lyc.py
import scrapy
from Bili.items import BiliItem
class LycSpider(scrapy.Spider):
name = 'lyc'
allowed_domains = ['bilibili.com']
start_urls = ['https://search.bilibili.com/all?keyword=课程&page=2']
# 爬取的方法
def parse(self, response):
item = BiliItem()
# 匹配
for jobs_primary in response.xpath('//*[@id="all-list"]/div[1]/ul/li'):
item['title'] = jobs_primary.xpath('./a/@title').extract()
item['url'] = jobs_primary.xpath('./a/@href').extract()
# 不能使用return
yield item
# pass
修改pipeline类
这个类是对爬取的文件最后的处理,一般为负责将所爬取的数据写入文件或数据库中.。
这里我们将它输出到控制台.
from itemadapter import ItemAdapter
class BiliPipeline:
def process_item(self, item, spider):
print("title:", item['title'])
print("url:", item['url'])
修改settings类
BOT_NAME = 'Bili'
SPIDER_MODULES = ['Bili.spiders']
NEWSPIDER_MODULE = 'Bili.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Bili (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 配置默认的请求头
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Bili.pipelines.BiliPipeline': 300,
}
一个 Scarpy项目的简单架构就完成了我们可以运行一下试试.
启动项目
scrapy crawl lyc
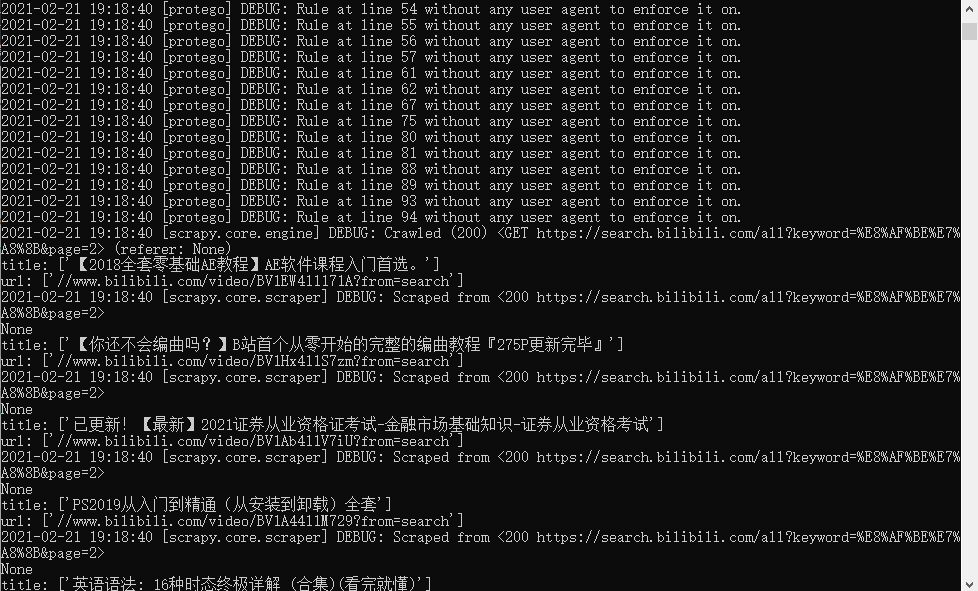
但只有 一页的内容 , 我们可以解析下一页 .
将以下代码加到 lyc.py
import scrapy
from Bili.items import BiliItem
class LycSpider(scrapy.Spider):
name = 'lyc'
allowed_domains = ['bilibili.com']
start_urls = ['https://search.bilibili.com/all?keyword=课程&page=2']
# 爬取的方法
def parse(self, response):
item = BiliItem()
# 匹配
for jobs_primary in response.xpath('//*[@id="all-list"]/div[1]/ul/li'):
item['title'] = jobs_primary.xpath('./a/@title').extract()
item['url'] = jobs_primary.xpath('./a/@href').extract()
# 不能使用return
yield item
# 获取当前页的链接
url = response.request.url
# page +1
new_link = url[0:-1]+str(int(url[-1])+1)
# 再次发送请求获取下一页数据
yield scrapy.Request(new_link, callback=self.parse)
下一页爬取
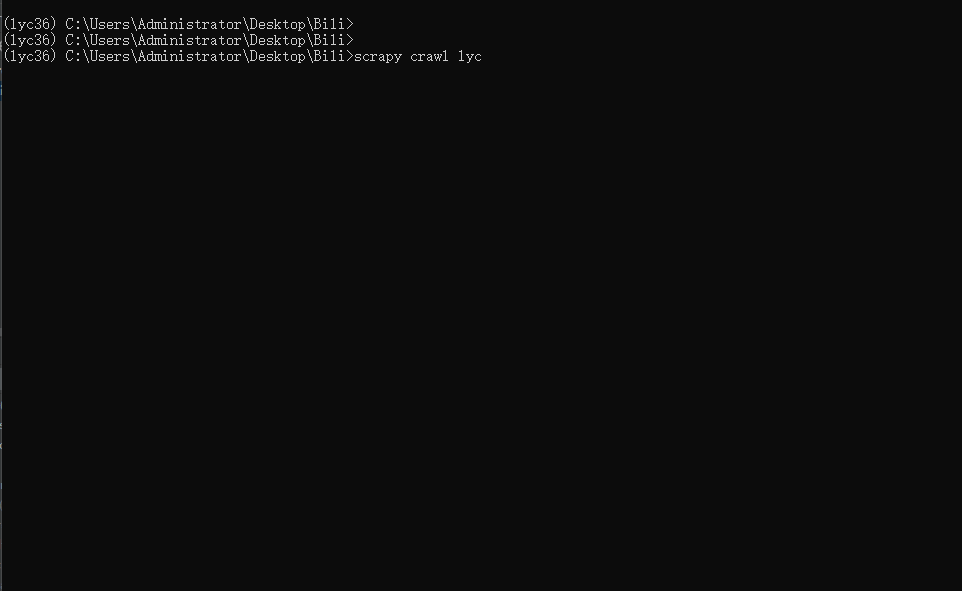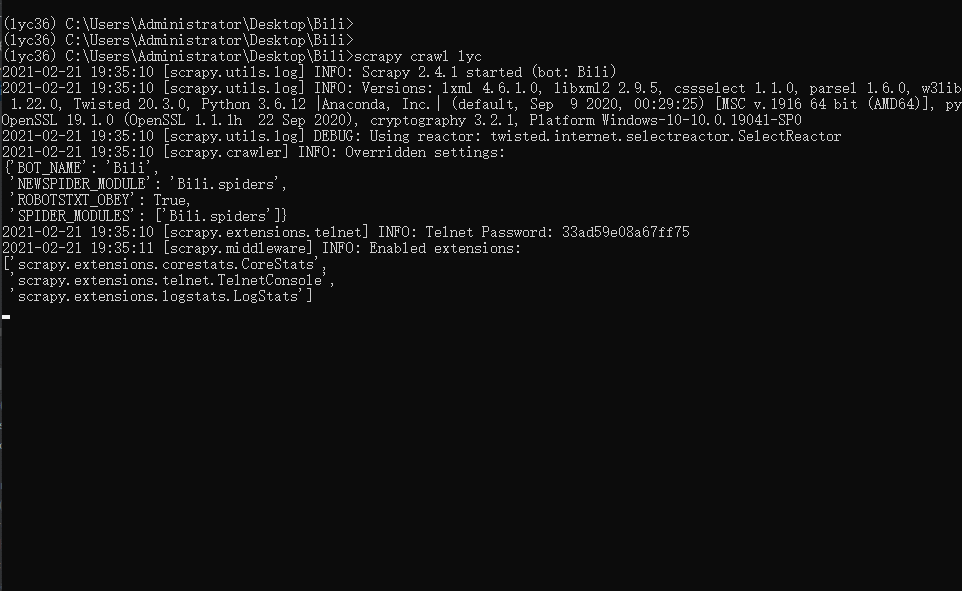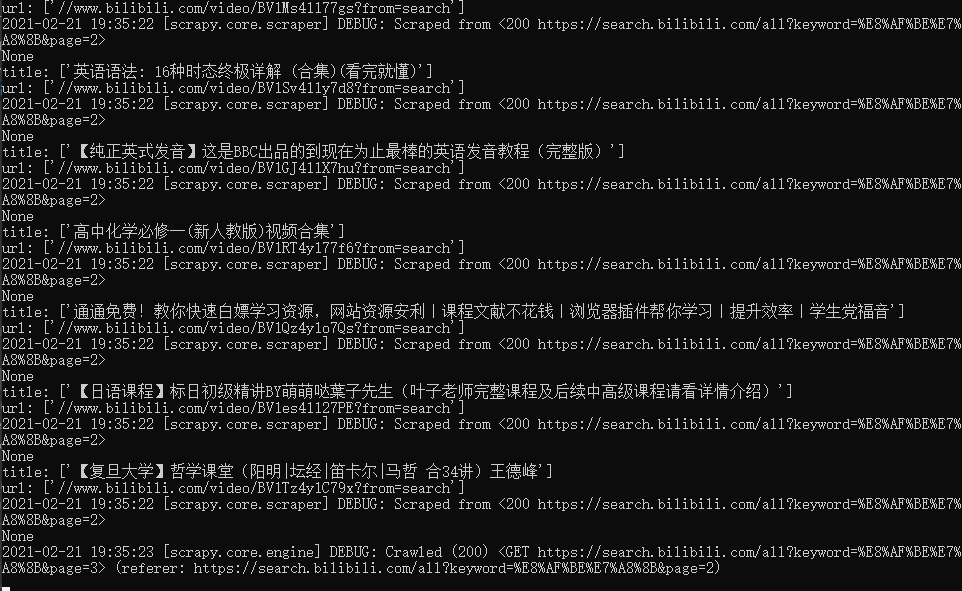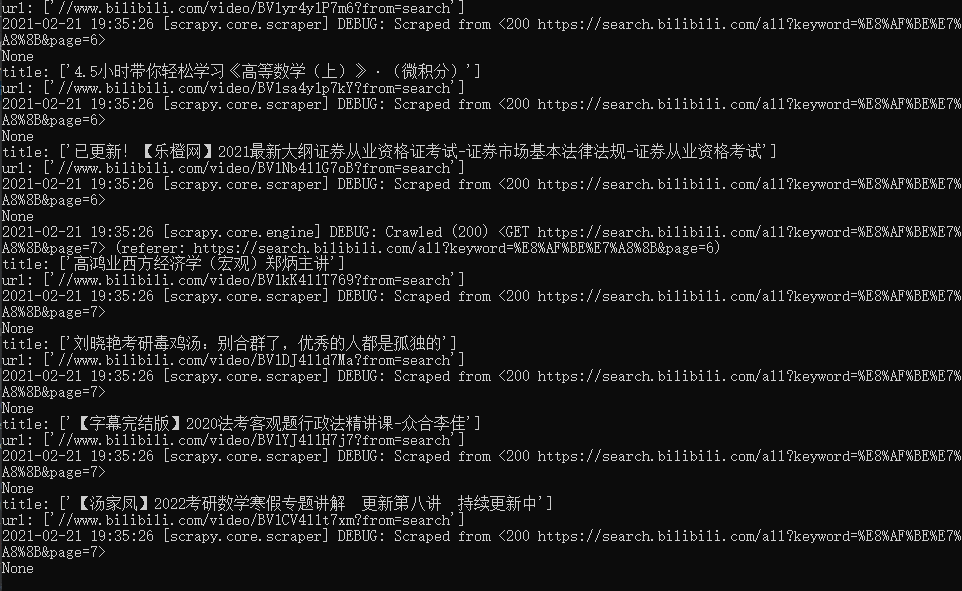
再次执行 , 就会一页一页的爬取 .
3.总结
1、通过实战案例『B站』,手把手实现scrapy项目的创建,解析网页,最后成功爬取数据并打印(保存)
2、适合小白入门scrapy,欢迎收藏,分析,学习