文章目录
为了能将用户程序装入内存,必须为它分配一定大小的内存空间。连续分配方式是最早出现的一种存储器分配方式,该分配方式为每一个用户程序分配一个连续的内存空间,程序中的代码或者数据的逻辑地址相邻,体现在内存空间分配物理地址的相邻。
连续分配方式分为四种:单一连续分配,固定分区分配,动态分区分配,动态可重定位分区。
一、单一连续分配
- 在单道程序环境下,当时的存储器管理方式是把内存分为系统区和用户区两部分。
- 系统区仅提供给OS使用,它通常是放在内存的低址部分。
- 在用户区内存中,仅装有一道用户程序,即整个内存的用户空间由该程序独占。
- 这样的存储器分配方式被称为单一连续分配方式。
二、固定分区分配
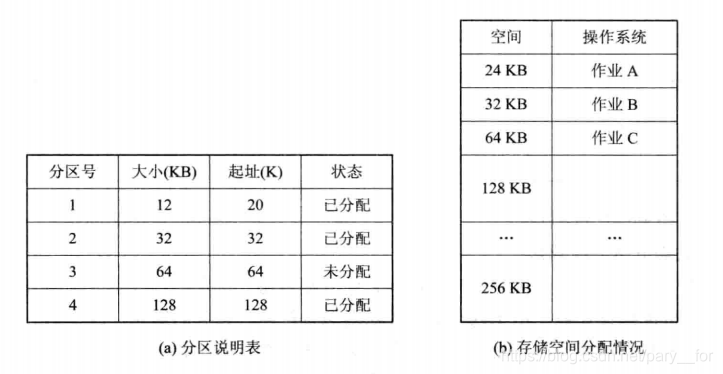
- 出现多道程序系统后,为了能在内存中装入多道程序,且这些程序之间不会发生相互干扰,于是将整个用户空间划分为若干固定大小的区域,每个分区只装入一个作业,这就是最早的最简单的一种可运行多道的分区式存储管理。
1. 划分分区的方法
可按照下面两种方法将用户空间分为若干个固定大小的分区:
- 分区大小相等(指所有的内存分区大小相等)。缺点:缺乏灵活性,即程序太小会造成内存空间浪费;程序太大,一个空间不足以装入该程序。
- 分区大小不等。增加了存储器分配的灵活性。
2. 内存分配
- 为了便于内存分配,通常将分区按其大小进行排队,并为之建立一张分区使用表,其中各表项包括:每个分区的起始地址、大小及状态(是否已分配)。
- 当有一个用户程序要装入时,由内存分配程序依据用户程序大小检索该表,从中找出一个能满足要求的,未分配的分区,将其分配给该程序,然后将该表项中的状态为“已分配”。若未找到大小足够的分区,则拒绝为该用户分配内存。
三、动态分区分配
- 动态分区分配是根据进程的实际需求,动态地为之分配内存空间。
- 在实现动态分区分配时,将涉及分区分配中所用的数据结构,分区分配算法和分区的分配和回收这样三方面问题。
1. 动态分区分配中的数据结构
常用的数据结构有:空闲分区表、空闲分区链。
-
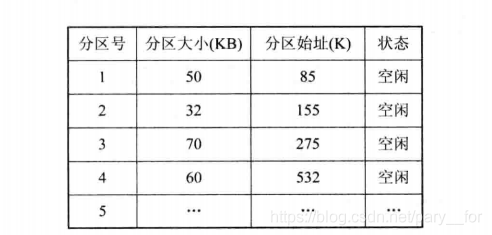
空闲分区表
在系统中设置一张空闲分区表,用来记录每个分区的情况,每个空闲分区占一个表目。表目中包括分区号,分区大小和分区始址等数据项
-
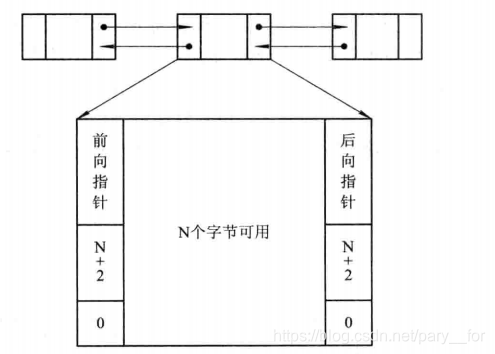
空闲分区链
为实现对空闲分区的分配和链接,在每个分区的起始部分设置一些用于控制分区分配的信息,以及用来链接各分区所用的前向指针,在分区尾部设置一向后指针,通过前、后向链接指针,可将所有的空闲分区链接成一个双向链表。
2. 动态分区分配算法
- 为把一个新作业装入内存,须按照一定的分配算法,从空闲分区表或空闲分区链中选出一分区分配给该作业。由于内存分配算法对系统性能有很大的影响,故人们对它进行了较为广泛而深入的研究,于是产生了许多动态分区分配算法。
- 在下面(四、基于顺序搜索的动态分区分配算法)(五、基于索引搜索的动态分区分配算法)详细介绍。
3. 分区分配操作
在动态分区存储管理方式中,主要的操作是:分配内存和回收内存。
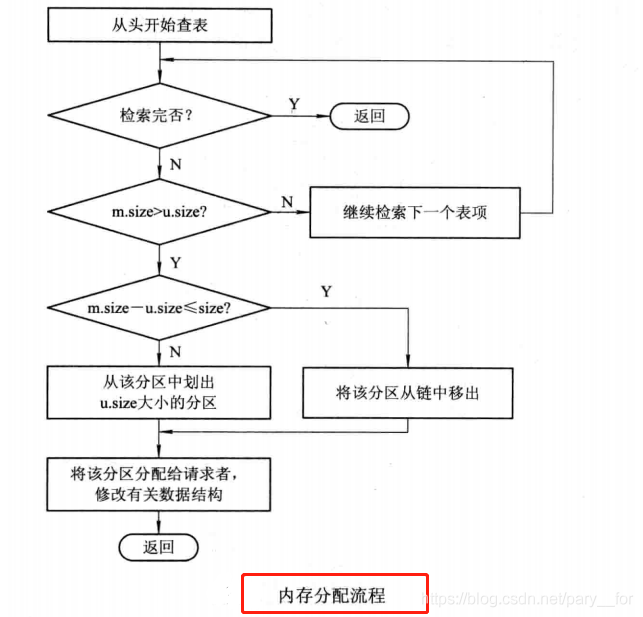
- 分配内存
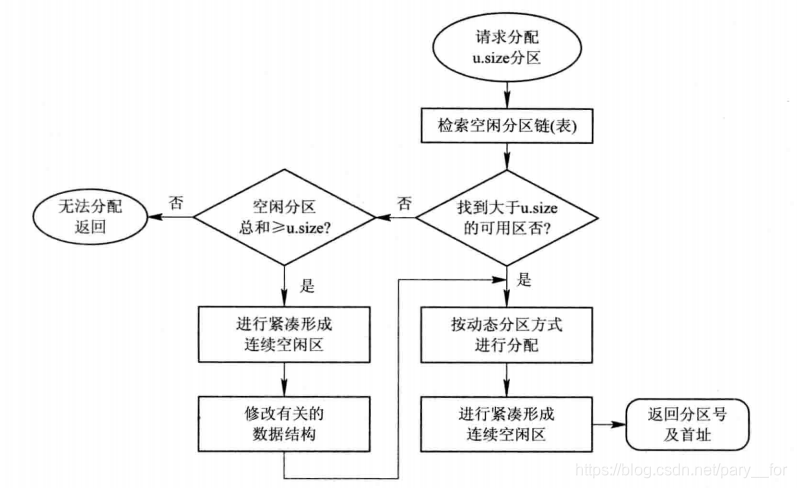
系统应利用某种分配算法,从空闲分区链(表)中找到所需大小的分区。设请求的分区大小为 u.size,表中每个空闲分区的大小可表示为 m.size,size 是事先规定的不再切割的剩余分区大小。此时操作系统分配内存如下图的流程图
- 回收内存
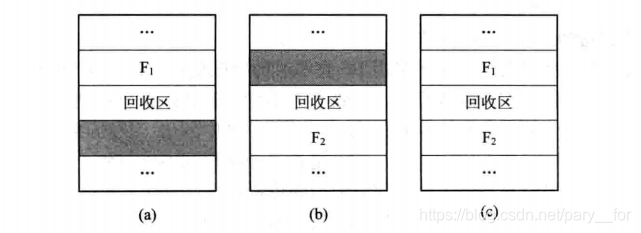
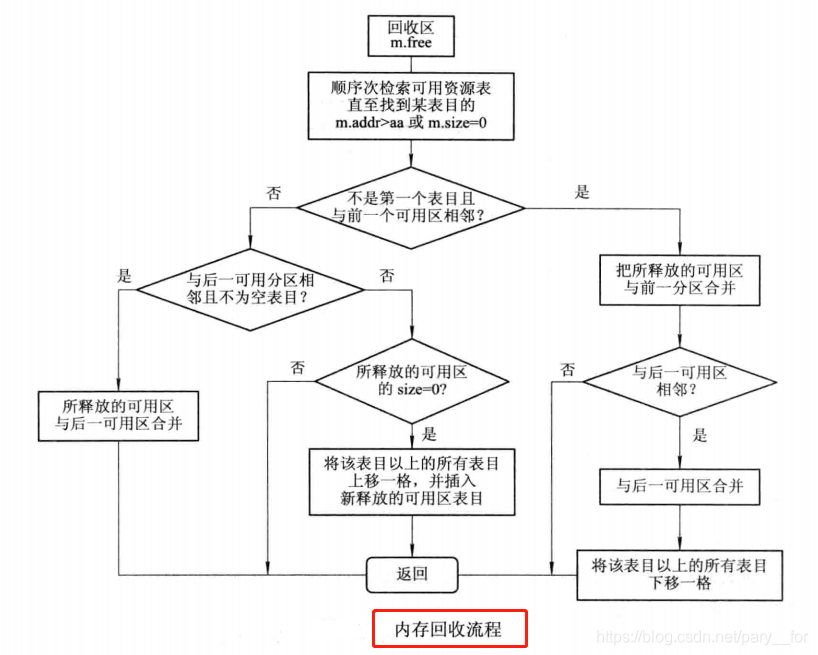
当进程运行完毕释放内存时,系统根据回收区的首址,从空闲区链(表)中找到相应的插入点,此时可能出现以下四种情况之一:- 回收区与插入点的前一个空闲分区F1相邻接,见图(a)。此时应将回收区与插入点的前一分区合并,不必为回收分区分配新表项,而只需修改其前一分区F1的大小。
- 回收分区与插入点的后一空闲分区F2相邻接,见图(b)。此时也可将两分区合并,形成新的空闲分区,但用回收区的首址作为新空闲区的首址,大小为两者之和。
- 回收区同时与插入点的前、后两个分区邻接,见图©。此时将三个分区合并,使用F1的表项和F1的首址,取消F2的表项,大小为三者之和。
- 回收区既不与F1邻接,又不与F2邻接。这时应为回收区单独建立一个新表项,填写回收区的首址和大小,并根据其首址插入到空闲链中的适当位置。
四、基于顺序搜索的动态分区分配算法
- 为了实现动态分区分配,通常是将系统的空闲分区链接成一个链。所谓的顺序搜索,是指依次搜索空闲分区链上的空闲分区,去寻找一个其大小能够满足要求的分区。
- 基于顺序搜索的动态分区分配算法有以下几种:首次适应算法,循环首次适应算法,最佳适应算法,最坏适应算法。
1. 首次适应算法(FF)(首地址递增,从链首开始)
- 以空闲分区链为例来说明采用FF算法时的分配情况。
- FF算法要求空闲分区链以地址递增的次序链接。在分配内存时,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止。然后再按照作业的大小,从该分区中划出一块内存空间,分配给请求者,余下的空闲分区仍留在空闲链中。若从链首直至链尾都不能找到一个能满足要求的分区,则表明系统中已没有足够大的内存分配给该进程,内存分配失败,返回。
- 优点:保留了高址部分的大空闲区,为之后到达的大作业分配大的内存空间创造了条件。
- 缺点:低址部分不断被划分,留下许多难以利用的,很小的分区,称为碎片。而且每次都是从头开始搜索,这就增加了空闲分区的开销。
2. 循环首次适应算法(NF)(首地址递增,不从链首开始)
- 为避免低址部分留下许多很小的空闲分区,以及减少查找可用空闲分区的开销,循环首次适应算法在为进程分配内存空间时,不再是每次都从链首开始查找,而是从上次找到的空闲分区的下一个空闲分区开始查找,直至找到一个能满足要求的空闲分区,从中划出一块与请求大小相等的内存空间分配给作业。
- 优点:该算法可以使内存中的空闲分区分布的更加均匀,从而减少了查询时间。
- 缺点:缺乏较大空闲分区。
3. 最佳适应算法(BF)(空闲分区大小递增)
- 所谓“最佳”是指,每次为作业分配内存时,总是把能满足要求、又是最小的空闲分区分配给作业,避免“大材小用”。为了加速寻找,该算法要求将所有的空闲分区按其容量以从小到大的顺序形成一空闲分区链。
- 优点:可以尽可能的找到最适合的内存空间。
- 缺点:BF算法会造成每次分配后所切割的剩余部分总是最小的,这样,在存储器中会留下许多难以利用的碎片。
4. 最坏适应算法(WF)(空闲分区大小递减)
- 由于最坏适应分配算法选择空闲分区的策略正好与最佳适应算法相反:它在扫描整个空闲分区表或链表时,总是挑选一个最大的空闲区,从中分割一部分存储空间给作业使用,以至于存储器中缺乏大的空闲分区,故把它称为是最坏适应算法。
- 优点:使可剩下的空闲区不至于太小,产生碎片的可能性很小,对中小作业有利。
- 缺点:缺乏较大空闲分区。
五、基于索引搜索的动态分区分配算法
- 基于顺序搜索的动态分区分配算法,比较适合于不太大的系统。
- 当系统很大时,就不适用,而一般采用的是基于索引搜索的动态分区分配算法。
- 目前常用的有快速适应算法,伙伴系统 和 哈希算法。
1.快速适应算法
- 该算法又称为分类搜索法,是将空闲分区根据其容量大小进行分类,对于每一类具有相同容量的所有空闲分区,单独设立一个空闲分区链表,这样系统中存在多个空闲分区链表。同时,在内存中设立一张 管理索引表,其中的每一个索引表项对应了一种空闲分区类型,并记录了该类型空闲分区链表表头的指针。
- 该算法在搜索可分为两步:
- 第一步,根据进程的长度,从索引表中去寻找能够容纳它的最下空闲区链表;
- 第二步,就是从链表中取出第一块进行分配即可。
- 优点:不会对分区进行切割,所以不会产生碎片,也能保留较大的分区,查询速度快。
- 缺点:为了有效合并分区,在分区归还主存时的算法复杂,系统开销较大。
2. 伙伴系统
- 在伙伴系统中,其分配和回收的时间性能取决于查找空闲分区的位置和分割、合并空闲区所花费的时间。
- 在回收空闲分配区时,需要对空闲分区进行合并,所以其时间性能比快速摄影算法差;但由于采用了索引搜索算法,比顺序搜索算法好。
- 其空间性能,由于对空闲分区进行合并,减少了小的空闲分区,提高了空闲分区的可使用率。故优于快速适应算法,比顺序搜索法略差。

3. 哈希算法
- 在上述的分类搜索算法和伙伴系统算法中,都是将空闲分区根据分区大小进行分类,对于每一类具有相同大小的空闲分区,单独设立一个空闲分区链表。在为进程分配空间时,需要在一张管理索引表中查找到所需空间大小所对应的表项,从中得到对应的空闲分区链表表头指针,从而通过查找得到一个空闲分区。如果对空闲分区分类较细,则相应索引表的表项也就较多,因此会显著地增加搜索索引表的表项的时间开销。
- 哈希算法就是利用哈希库快速查找的优点,以及空闲分区在可利用空闲区表中的分布规律,建立哈希函数,构造一张以空闲分区大小为关键字的哈希表,该表的每一个表项记录了一个对应的空闲分区链表表头指针。
- 当进行空闲分区分配时,根据所需空闲分区的大小,通过哈希函数计算,即得到在哈希表中的位置。从中得到相应的空闲分区链表,实现最佳分配策略。
六、动态可重定位分区分配
1. 紧凑
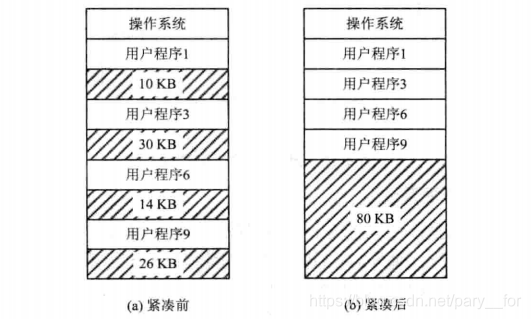
- 连续分配方式的一个重要特点是,一个系统或用户程序必须被装入一片连续的内存空间中。当一台计算机运行了一段时间后,它的内存空间将会被分割成许多小的分区,而缺乏大的空闲空间。即使这些分散的许多小分区的容量总和大于要装入的程序,但由于这些分区不相邻接,也无法把该程序装入内存。
- 如果想把大作业装入,可采用的一种方法是:将内存中所有作业进行移动,使他们都相邻接。这样,即可把许多碎片拼接成一个大分区,这种方法称为"拼接"或者"紧凑"。
2. 动态重定位
- 在动态运行时装入的方式中,作业装入内存后的所有地址仍然都是相对(逻辑)地址。而将相对地址转换为绝对(物理)地址的工作被推迟到程序指令要真正执行时进行。
- 为使地址的转换不会影响到指令的执行速度,必须有硬件地址变换机构的支持,即须在系统中增设一个重定位寄存器,用它来存放程序(数据)在内存中的起始地址。程序在执行时,真正访问的内存地址是相对地址与重定位寄存器中的地址相加而形成的。
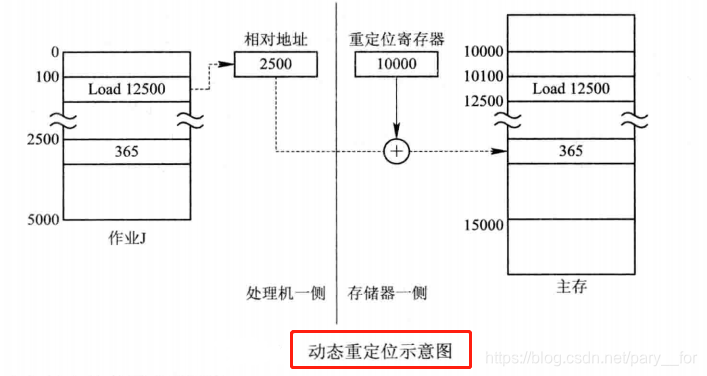
3. 动态重定位分区分配算法
- 动态重定位分区分配算法与动态分区分配算法基本上相同,差别仅在于:在这种分配算法中,增加了紧凑的功能。
- 通常,当该算法不能找到一个足够大的空闲分区以满足用户需求时,如果所有的小的空闲分区的容量总和大于用户的要求,这时便须对内存进行“紧凑”,将经“紧凑”后所得到的大空闲分区分配给用户。如果所有的小的空闲分区的容量总和仍小于用户的要求,则返回分配失败信息。